







最近在做一个时空序列聚类的小项目,度量聚类优劣的指标使用到了DBI指数,所以开始学习了一下DBI指数,以下是我的理解和基于python3的实现:
戴维森堡丁指数(DBI),又称为分类适确性指标,是由大卫L·戴维斯和唐纳德·Bouldin提出的一种评估聚类算法优劣的指标。首先假设我们有m个时间序列,这些时间序列聚类为n个簇。m个时间序列设为输入矩阵X,n个簇类设为N作为参数传入算法。使用下列公式进行计算: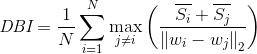
接下来是算法的具体计算步骤:
1、计算Si
DBI计算公式中首先定义了Si变量,Si计算的是类内数据到簇质心的平均距离,代表了簇类i中各时间序列的分散程度,计算公式为:
2、计算Mij
分子之和计算完后,需计算分母Mij,定义为簇类i与簇类j的距离,计算公式为:

计算了分子与分母后,DBI定义了一个衡量相似度的值Rij,计算公式为:

4、计算DBI
有了以上公式的基础,我们做一个基于簇类数n的n^2的嵌套循环,对每一个簇类i计算最大值的Rij,记为Di,即
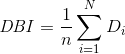
pyhton3代码实现如下:
import math
# nc is number of clusters
# to be implemented without the use of any libraries (from the scratch)
def vectorDistance(v1, v2):
"""
this function calculates de euclidean distance between two
vectors.
"""
sum = 0
for i in range(len(v1)):
sum += (v1[i] - v2[i]) ** 2
return sum ** 0.5
def compute_Si(i, x, clusters,nc):
norm_c = nc
s = 0
for t in x[i]:
s += vectorDistance(t,clusters)
return s/norm_c
def compute_Rij(i, j, x, clusters, nc):
Mij = vectorDistance(clusters[i],clusters[j])
Rij = (compute_Si(i,x,clusters[i],nc) + compute_Si(j,x,clusters[j],nc))/Mij
return Rij
def compute_Di(i, x, clusters, nc):
list_r = []
for j in range(nc):
if i != j:
temp = compute_Rij(i, j, x, clusters, nc)
list_r.append(temp)
return max(list_r)
def compute_DB_index(x, clusters, nc):
sigma_R = 0.0
for i in range(nc):
sigma_R = sigma_R + compute_Di(i, x, clusters, nc)
DB_index = float(sigma_R)/float(nc)
return DB_index















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









