







关于kaggle,不多说了,直接上干货,我这次做的是入门级别的这个题目——手写数字的图像识别预测,主要使用了KNN、LR、RF、SVM四种分类器进行预测。
一、KNN分类器
KNN算法是所有机器学习算法中最简单的模型了,可以说是不需要训练的,直接计算最近距离样本的类别来进行划分,最大的缺点就是计算量大。
首先导入各种第三方包,并读取数据
import pandas as pd
import numpy as np
import time
from sklearn.cross_validation import cross_val_score
import threading
import warnings
warnings.filterwarnings("ignore")
#读取训练数据集
dataset = pd.read_csv("train.csv")
print(dataset.shape)
X_train = dataset.values[0:, 1:]
y_train = dataset.values[0:, 0]
#读取测试数据集
X_test = pd.read_csv("test.csv").values(42000, 785)
由于数据集的维数太大,会给计算带来很大的开销,在此对数据进行PCA降维处理,并保证数据的具有原始数据95%的信息
## 对数据进行PCA降维
from sklearn.decomposition import PCA
PCA_model = PCA()
PCA_model.fit(X_train)
information_list = PCA_model.explained_variance_ratio_
score = 0
num = 0
for i in information_list:
score += i
num += 1
if score >= 0.95:
print("num:", num)
break
#根据训练的降维模型,对训练数据和测试数据进行降维得到降维后的数据
PCA_model = PCA(num)
PCA_model.fit(X_train)
X_train = PCA_model.transform(X_train)
print(X_train.shape)
X_test = PCA_model.transform(X_test)
print(X_test.shape)num: 154 (42000, 154) (28000, 154)
对数据及逆行降维后,可见数据的维度从785下降到了154,下降了大约80%的数据量,但仍保保留着95% 的信息。
## 对特征数据数据进行归一化化处理
X_train = (X_train - X_train.min())/(X_train.max() - X_train.min())
X_test = (X_test - X_test.min())/(X_test.max() - X_test.min())# 取少量数据进行超参数的选择或参数的选择
X_train_small = X_train[0:5000]
y_train_small = y_train[0:5000]创建函数用于选取KNN类中选取最合适的超参数k的值
from sklearn.neighbors import KNeighborsClassifier
# 测试函数 用于找到最合适的超参数K值
def ceshi_k(num1, num2):
for k in range(num1, num2 + 1):
start = time.clock()
# 创建KNN分类器对象
knn_clf=KNeighborsClassifier(n_neighbors=k, algorithm='kd_tree', weights='distance', p=2)
# 对训练数据集做5折交叉训练,取平均值作为结果
score = cross_val_score(knn_clf, X_train_small, y_train_small, cv=5)
elapsed = (time.clock() - start)
print( "k取值为 ", k, "时,的结果是:", score.mean(), ". Time used:", int(elapsed), "s" )start = time.clock()
threads = []
t1 = threading.Thread(target=ceshi_k, args=(1, 3,))
threads.append(t1)
t2 = threading.Thread(target=ceshi_k, args=(4, 6,))
threads.append(t2)
t3 = threading.Thread(target=ceshi_k, args=(7, 9,))
threads.append(t3)
for t in threads:
t.start()
for j in threads:
j.join()
elapsed = (time.clock() - start)
print("Total Time used:", int(elapsed), "s")k取值为 4 时,的结果是: 0.969118920724 . Time used: 3299 s k取值为 7 时,的结果是: 0.965976298233 . Time used: 3315 s k取值为 1 时,的结果是: 0.966238027247 . Time used: 3333 s k取值为 5 时,的结果是: 0.966904566608 . Time used: 2983 s k取值为 8 时,的结果是: 0.966476346453 . Time used: 2983 s k取值为 2 时,的结果是: 0.966238027247 . Time used: 2982 s k取值为 6 时,的结果是: 0.967785759978 . Time used: 2885 s k取值为 9 时,的结果是: 0.964571448194 . Time used: 2883 s k取值为 3 时,的结果是: 0.967809305968 . Time used: 2881 s Total Time used: 9198 s由结果可以得到当k取4时,准确率最高,那么在下面进行预测时创建的分类器就将k设置为4
#读取测试数据集
X_test = pd.read_csv("test.csv").values
knn_clf=KNeighborsClassifier(n_neighbors=4, algorithm='kd_tree', weights='distance', p=2)
start = time.clock()
knn_clf.fit(X_train,y_train)
result=knn_clf.predict(X_test)
result = np.c_[range(1,len(result)+1), result.astype(int)]
df_result = pd.DataFrame(result, columns=['ImageId', 'Label'])
df_result.to_csv('./results.knn.csv', index=False)
#end time
elapsed = (time.clock() - start)
print("Test Time used:",int(elapsed/60) , "min")上传到kaggle上看一下结果吧。

看结果0.97185,还不错,可是看到排名1292,心都凉了,可是也没有什么特征能够优化的了,可能是模型太简单了,下面使用更复杂的机器学习模型进行预测,应该能够取得更加好的成绩吧。
二、LR分类器
LR是一个适用性特别光而且比较简单的二分类分类器,这里将其用作多分类的情况,数据处理部分与上面的相同,这里不再赘述
from sklearn.linear_model import LogisticRegression
start = time.clock()
lr_clf=LogisticRegression(penalty='l2', solver ='lbfgs', multi_class='multinomial', max_iter=800, C=0.2 )
parameters = {'penalty':['l1', 'l2'] , 'C':[8e-2, 12e-2, 0.15, 0.18, 2e-1]}
gs_clf = GridSearchCV(lr_clf, parameters, n_jobs=1, verbose=True )
gs_clf.fit( X_train.astype('float'), y_train )
for params, mean_score, scores in gs_clf.grid_scores_:
print("%0.4f (+/-%0.03f) for %r" % (mean_score, scores.std() * 2, params))
#end time
elapsed = (time.clock() - start)
print("Time used:",elapsed)从结果中可以看到参数的最终取值,采用L1正则,C的值取0.2
## 结合以上两种模型的多种参数,选取最好的参数penalty='l1', C=0.2
from sklearn.linear_model import LogisticRegression
lr_clf=LogisticRegression(penalty='l1', C=0.2 )
lr_clf.fit( X_train.astype('float'), y_train)
result = lr_clf.predict(X_test)
result = np.c_[range(1,len(result)+1), result.astype(int)]
# 添加列索引
df_result = pd.DataFrame(result, columns=['ImageId', 'Label'])
# 保存到文件
df_result.to_csv('./results+降维+逻辑回归.csv', index=False)最终得到的结果是88.557%,kaggle结果见下图。

三、RF随机森林分类器
随机森林属于集成学习中并行化方法的Bagging的一种形式,集成学习一般来说具有其他单一分类器所不具备的功能,这里使用随机森林进行分类,使用随机森林是不需要对数据进行归一化处理
from sklearn.ensemble import RandomForestClassifier
#begin time
start = time.clock()
parameters = {'n_estimators':[10, 50, 100, 400], 'criterion':['gini','entropy'], 'max_features':['auto', 5, 10]}
rf_clf=RandomForestClassifier(n_estimators=400, n_jobs=4, verbose=1)
gs_clf = GridSearchCV(rf_clf, parameters, n_jobs=1, verbose=True )
gs_clf.fit( X_train_small.astype('int'), y_train_small )
for params, mean_score, scores in gs_clf.grid_scores_:
print("%0.3f for %r" % (mean_score, params))
#end time
elapsed = (time.clock() - start)
print("Time used:",elapsed)0.802 for {'criterion': 'gini', 'max_features': 'auto', 'n_estimators': 10}
0.898 for {'criterion': 'gini', 'max_features': 'auto', 'n_estimators': 50}
0.913 for {'criterion': 'gini', 'max_features': 'auto', 'n_estimators': 100}
0.921 for {'criterion': 'gini', 'max_features': 'auto', 'n_estimators': 400}
0.683 for {'criterion': 'gini', 'max_features': 5, 'n_estimators': 10}
0.866 for {'criterion': 'gini', 'max_features': 5, 'n_estimators': 50}
0.898 for {'criterion': 'gini', 'max_features': 5, 'n_estimators': 100}
0.915 for {'criterion': 'gini', 'max_features': 5, 'n_estimators': 400}
0.792 for {'criterion': 'gini', 'max_features': 10, 'n_estimators': 10}
0.898 for {'criterion': 'gini', 'max_features': 10, 'n_estimators': 50}
0.910 for {'criterion': 'gini', 'max_features': 10, 'n_estimators': 100}
0.922 for {'criterion': 'gini', 'max_features': 10, 'n_estimators': 400}
0.807 for {'criterion': 'entropy', 'max_features': 'auto', 'n_estimators': 10}
0.899 for {'criterion': 'entropy', 'max_features': 'auto', 'n_estimators': 50}
0.907 for {'criterion': 'entropy', 'max_features': 'auto', 'n_estimators': 100}
0.918 for {'criterion': 'entropy', 'max_features': 'auto', 'n_estimators': 400}
0.669 for {'criterion': 'entropy', 'max_features': 5, 'n_estimators': 10}
0.862 for {'criterion': 'entropy', 'max_features': 5, 'n_estimators': 50}
0.896 for {'criterion': 'entropy', 'max_features': 5, 'n_estimators': 100}
0.916 for {'criterion': 'entropy', 'max_features': 5, 'n_estimators': 400}
0.788 for {'criterion': 'entropy', 'max_features': 10, 'n_estimators': 10}
0.891 for {'criterion': 'entropy', 'max_features': 10, 'n_estimators': 50}
0.906 for {'criterion': 'entropy', 'max_features': 10, 'n_estimators': 100}
0.918 for {'criterion': 'entropy', 'max_features': 10, 'n_estimators': 400}
Time used: 507.2511155929216
其中0.922最大,故选取的参数是:n_estimators=400, verbose=1, criterion = 'gini', max_features = '10'
rf_clf=RandomForestClassifier(n_estimators=400, n_jobs=4, verbose=1, criterion = 'gini', max_features = '10')
rf_clf.fit( X_train.astype('float'), y_train)
result = rf_clf.predict(X_test)
result = np.c_[range(1,len(result)+1), result.astype(int)]
# 添加列索引
df_result = pd.DataFrame(result, columns=['ImageId', 'Label'])
# 保存到文件
df_result.to_csv('./results+降维+随机森林.csv', index=False)
可见随机森林的结果正确率只有94.814%,还不如KNN 和逻辑回归的结果好。
四、SVM分类器
SVM是神经网络出现之前最好的机器学习模型,SVM是Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况,甚至扩展到使用非线性函数中去。
from sklearn.svm import SVC
from sklearn.grid_search import GridSearchCV
start = time.clock()
parameters = {'C':( 1, 2, 5, 10, 50) , 'gamma':[0.01, 0.02, 0.03, 0.04, 0.05]}
svc_clf=SVC( kernel='rbf', verbose=True )
gs_clf = GridSearchCV(svc_clf, parameters, n_jobs=1, verbose=True )
gs_clf.fit( X_train_small.astype('float'), y_train_small )
for params, mean_score, scores in gs_clf.grid_scores_:
print("%0.3f\tfor %r" % (mean_score, scores.std() * 2, params))
elapsed = (time.clock() - start)
print("Time used:",elapsed)从中选取最优的参数C= 0.5 和gamma=0.025,最终的结果是98.471%
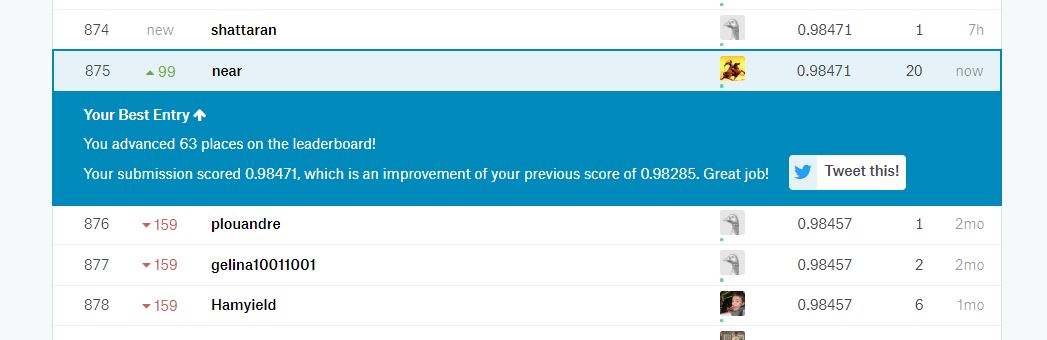
自己实际操作一下可以对模型的历届更深入一些,也锻炼了改代码bug的能力.

















 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









