








本文将讲解 Python 编程语言中 多线程处理情况下线程同步的概念。
线程之间的同步
线程同步被定义为一种机制,它确保两个或多个并发线程不会同时执行某些称为关键段的特定程序段。
关键部分是指访问共享资源的程序部分。
例如,在下图中,3 个线程尝试同时访问共享资源或关键部分。
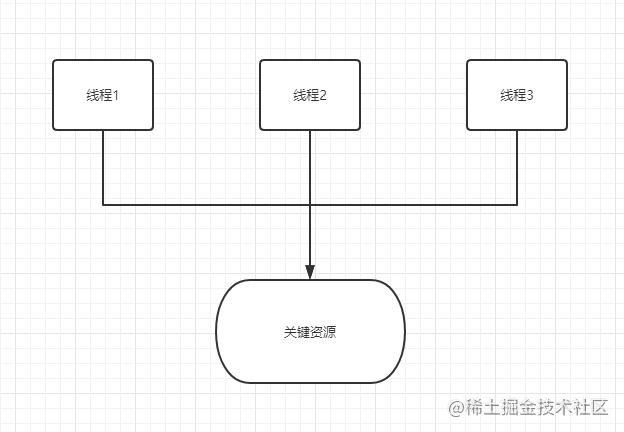
对共享资源的并发访问可能导致争用情况。
当两个或多个线程可以访问共享数据并尝试同时更改共享数据时,就会发生争用情况。因此,变量的值可能是不可预测的,并且根据进程的上下文切换的时间而变化。
考虑下面的程序来理解争用条件的概念:
import threading
# 全局变量 x
x = 0
def increment():
"""用于递增全局变量x的函数"""
global x
x += 1
def thread_task():
""" 线程的任务调用增量函数100000次。"""
for _ in range(10000000):
increment()
def main_task():
global x
# 将全局变量x设置为0
x = 0
# 创建线程
t1 = threading.Thread(target=thread_task)
t2 = threading.Thread(target=thread_task)
# 开启线程
t1.start()
t2.start()
# 等待线程完成
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(10):
main_task()
print("迭代 {0}: x = {1}".format(i, x))
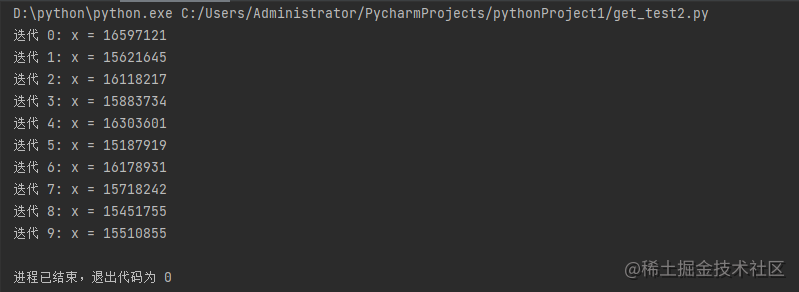
运行结果:
在上面的程序中:
- 在函数main_task中创建两个线程 t1 和 t2,并且全局变量 x 设置为 0。
- 每个线程都有一个目标函数thread_task其中增量函数被调用 100000 次。
- increment 函数将在每次调用中将全局变量 x 递增 1。
x 的预期最终值为 200000,但我们在函数的 10 次迭代中得到main_task是一些不同的值。
(如果您每次的运行结果都一样,可能是由于您的计算机性能比较好,可以尝试这加大
thread_task()方法的数据,如多加一个零或几个零,如10000000次)
发生这种情况是由于线程对共享变量 x 的并发访问。x 值的这种不可预测性只不过是竞态条件。
下面给出的是一个图表,显示了在上面的程序中如何发生争用条件:
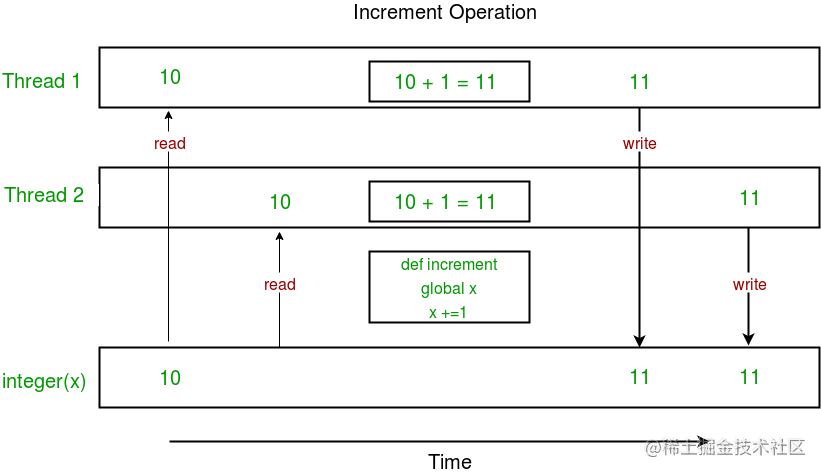
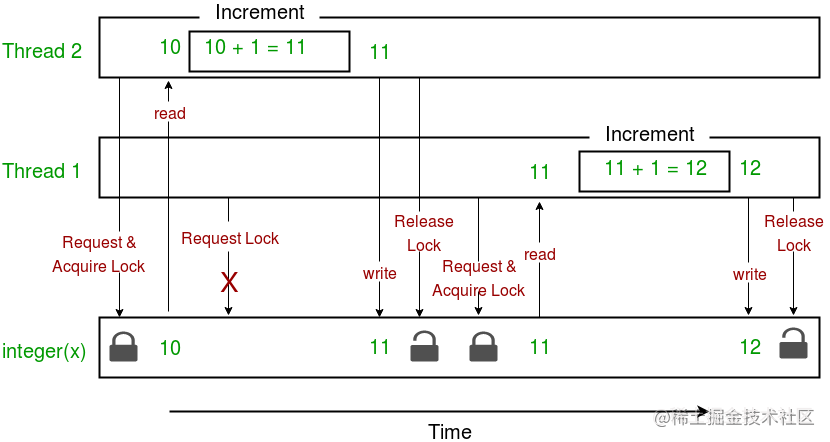
请注意,上图中 x 的预期值为 12,但由于争用条件,结果是 11!
因此,我们需要一个工具来在多个线程之间进行适当的同步。
这里我们就会用到线程锁了
线程锁
线程模块提供了一个 Lock 类来处理争用条件。锁定是使用操作系统提供的信号量对象实现的。
信号量是一个同步对象,用于控制多个进程/线程对并行编程环境中公共资源的访问。它只是操作系统(或内核)存储中指定位置的值,每个进程/线程都可以检查该值,然后进行更改。根据找到的值,进程/线程可以使用该资源,或者会发现它已在使用中,并且必须等待一段时间才能重试。信号量可以是二进制(0 或 1),也可以具有其他值。通常,使用信号量的进程/线程会检查该值,然后,如果它使用资源,则更改该值以反映此值,以便后续信号量用户将知道等待。
Lock 类提供以下方法:
-
获取([阻塞]) : 获取锁。锁可以是阻塞的,也可以是非阻塞的。
- 当在将阻塞参数设置为 True(默认值)的情况下调用时,线程执行将被阻塞,直到锁定解锁,然后锁定设置为锁定并返回 True。
- 当在将阻塞参数设置为 False 的情况下调用时,不会阻塞线程执行。如果锁定已解锁,则将其设置为锁定并返回 True, 否则会立即返回 False。
-
释放() : 释放锁。
- 锁定后,将其重置为已解锁,然后返回。如果任何其他线程被阻塞等待锁定解锁,请只允许其中一个线程继续。
- 如果锁定已解锁,则会引发线程错误。
请考虑下面给出的示例:
import threading
# 全局变量 x
x = 0
def increment():
"""用于递增全局变量x的函数"""
global x
x += 1
def thread_task(lock):
"""线程的任务调用增量函数100000次."""
for _ in range(100000):
lock.acquire()
increment()
lock.release()
def main_task():
global x
# 设置全局变量为 0
x = 0
# 创建线程锁
lock = threading.Lock()
# 创建线程
t1 = threading.Thread(target=thread_task, args=(lock,))
t2 = threading.Thread(target=thread_task, args=(lock,))
# 开启线程
t1.start()
t2.start()
# 等待所有线程完成
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(10):
main_task()
print("迭代 {0}: x = {1}".format(i, x))
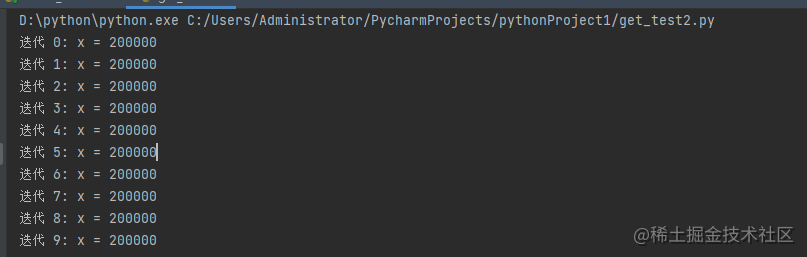
运行结果:
让我们尝试一步一步地理解上面的代码:
-
首先,使用以下命令创建 Lock 对象:
lock = threading.Lock() -
然后,将 lock 作为目标函数参数传递:
t1 = threading.Thread(target=thread_task, args=(lock,)) t2 = threading.Thread(target=thread_task, args=(lock,)) -
在目标函数的关键部分,我们使用 lock.acquire() 方法应用 lock。一旦获得锁,在使用 lock.release() 方法释放锁之前,没有其他线程可以访问关键部分(此处为增量函数)。
lock.acquire() increment() lock.release()正如您在结果中看到的,x 的最终值每次都显示为 200000(这是预期的最终结果)。
下面给出了一个图表,描述了上述程序中锁的实现:
多线程处理的一些优点和缺点
最后,以下是多线程处理的一些优点和缺点:
优势:
- 它不会阻止用户。这是因为线程彼此独立。
- 由于线程并行执行任务,因此可以更好地利用系统资源。
- 增强了多处理器计算机上的性能。
- 多线程服务器和交互式 GUI 仅使用多线程处理。
弊:
- 随着线程数量的增加,复杂性也会增加。
- 共享资源(对象、数据)的同步是必要的。
- 调试难度大,有时结果不可预测。
- 导致饥饿的潜在死锁,即某些线程可能无法提供糟糕的设计
- 构造和同步线程会占用大量 CPU/内存。
















 2350
2350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











