







字符串离散化: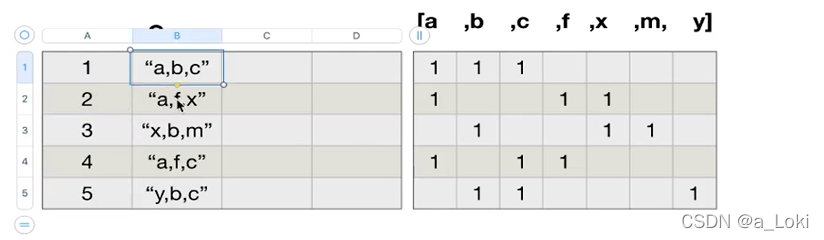
代码:(统计字符串出现的次数)
import pandas as pd
import numpy as np
df = pd.read_csv('./data/IMDB-Movie-Data.csv')
temp_list = df['Genre'].str.split(',').tolist()
genre_list = list(set([i for j in temp_list for i in j]))
# 搞出来所有的电影类型,set 去重处理
# 创建一个全为零的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# df.shape[0] 规定行,len(genre_list)规定列
# 当该类型存在时,将0改写为1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]] = 1
sum_df = zeros_df.sum(axis=0) # 求和
sum_df = sum_df.sort_values() # 排序
# 画图,选择条形图
import matplotlib.pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
_x = sum_df.index
_y = sum_df.values
plt.xticks(range(len(_x)),_x)
plt.bar(range(len(_x)),_y)
plt.show()数据合并,join:
join:默认情况下是将行索引相同的数据合并到一起
import numpy as np
import pandas as pd
t_1 = pd.DataFrame(np.zeros((2,4)),index=list('AB'),columns=list('abcd'))
t_2 = pd.DataFrame(np.ones((3,4)),index=list('ABC'),columns=list('xyzo'))
print(t_1)
print(t_2)
print(t_1.join(t_2))
print(t_2.join(t_1))
结果:

merge:
按照指定的列把数据按照一定的方式合并到一起
inner:交集
outer:并集
left:按左
right:按右

pandas分组聚合:
分组:

聚合:

1,在所有国家的数据中统计中国和美国星巴克数量
import pandas as pd
df = pd.read_csv('./starbucks_store_worldwide.csv')
# print(df)
# 分组groupby count() 聚合
groub = df.groupby(by = df['Country']).count()['Brand']
print(groub) # groub代表所有国家星巴克数量
print(groub['US']) # 美国数量
print(groub['CN']) # 中国数量2,对中国每个省份数量分组聚合
import pandas as pd
df = pd.read_csv('./starbucks_store_worldwide.csv')
china_data = df[df['Country'] == 'CN'] # 中国的数据
groub = china_data.groupby(by='State/Province').count()['Brand']# 从中取所有的省份分组聚合
print(groub)结果:
这里省份用数字代替
3,对国家和省份同时分组(多个字段分组

import pandas as pd
df = pd.read_csv('./starbucks_store_worldwide.csv')
groub = df['Brand'].groupby(by=[df['Country'],df['State/Province']]).count() # count() 求和
# df['Brand']中是不包含 Country和State/Province的,所以要从df中取
print(groub)结果:

这里注意:得到的结果是一个Series类型而不是DATa Frame ,因为我们按照国家和城市两个条件进行分组就会有俩个索引(复合索引),只有Bread一列数据。
需要变成DataFrame类型
groub1 = df[['Brand']].groupby(by=[df['Country'],df['State/Province']]).count() # count()
groub2 = df.groupby(by=[df['Country'],df['State/Province']])[['Brand']].count() # count()
groub3 = df.groupby(by=[df['Country'],df['State/Province']]).count()[['Brand']] # count()在Bread外多加一个[] (用DataFrame方式 整组一起取)
索引和复合索引:

如何通过复合索引取值:
s.swaplevel()['']:从内层开始取值
DataFrame取的时候要加上.loc















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









