







 本文介绍了基于p-stable分布改进的位置敏感哈希(LSH)技术,优化了l_2范数下的运行时间,成为首个高效l_p范数近邻搜索算法。通过将数据点投影到随机高维直线并切割成固定长度段来生成哈希值,保持了数据点的距离关系。实验表明,该算法在不同场景下表现出良好的性能。
本文介绍了基于p-stable分布改进的位置敏感哈希(LSH)技术,优化了l_2范数下的运行时间,成为首个高效l_p范数近邻搜索算法。通过将数据点投影到随机高维直线并切割成固定长度段来生成哈希值,保持了数据点的距离关系。实验表明,该算法在不同场景下表现出良好的性能。
在数据量急速扩张和对搜索速度期望提高的背景下,位置敏感哈希技术(LSH:locality-senstive hashing)应运而生。顾名思义,这种技术就是数据点在哈希之后保持原始数据之间的距离。换一种说法就是,在原始距离中较近的点有较大的可能性被哈希成同一个点,而原始距离中距离较远的点有较大的可能性被哈希成距离很远的数据。
本文对原始的LSH提出了一种改进,即基于一种基于p-stable分布的LSH。
优点:
1.优化了之前的LSH在l_2范数下的运行时间
2.这是第一种高效的在(p<1)l_p范数下的近邻搜索算法
3.该算法可以直接作用于欧拉空间点而不需要嵌入到汉明空间。
4.query的时间复杂度与之前算法相比没有一个很大的常数。
传统位置敏感哈希
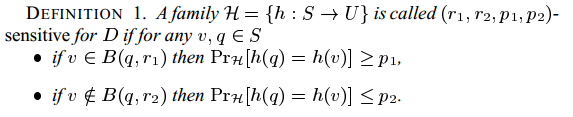
p1>p2 ;r1<r2
那么LSH技术是如何解决(R,c)-NN 问题的呢?
1. 定义r1 = R, r2 = cR, 定义相应(r1,r2,p1,p,2)哈希函数族
2. 再函数族中选k个函数构成一个映射到k维函数,新函数族G = {g:s->U_k}
3.再选一个常数L,从新函数族G中选出L个函数
4.利用这L个函数分别把输入数据映射成L个哈希表
查询步骤:
在查询一个query Q时, 用上述的L个函数分别把Q映射成L个哈希码,然后在相对应的表中找到相应的桶(buket),再从桶中筛选出符号条件的数据点。
其中通过对参数k和L进行恰当的选取,一个正确的哈希算法应保证两个结论:
1.在查询中能找到相似的点
2.控制查询返回的数据点数量。(文中的分析为 3L )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









