







本文介绍数据分析案例——MovieLens 1M数据集
GroupLens Research(http://www.grouplens.org/node/73)采集了一组从20世纪90年末到21世纪初由MovieLens用户提供的电影评分数据。这些数据中包括电影评分、电影元数据(风格类型和年代)以及关于用户的人口统计学数据(年龄、邮编、性别和职业等)。基于机器学习算法的推荐系统一般都会对此类数据感兴趣。虽然我不会在本书中详细介绍机器学习技术,但我会告诉你如何对这种数据进行切片切块以满足实际需求。
MovieLens 1M数据集含有来自6000名用户对4000部电影的100万条评分数据。它分为三个表:评分、用户信息和电影信息。将该数据从zip文件中解压出来之后,可以通过pandas.read_table将各个表分别读到一个pandas DataFrame对象中:
def print_first_lines(filename, num_lines=5):
"""
打印文件的前几行。
:param filename: 文件路径
:param num_lines: 要打印的行数,默认为5
"""
with open(filename, 'r', encoding='utf-8') as file: # 指定编码可能有助于避免读取错误
for _ in range(num_lines):
line = file.readline().strip()
if line: # 确保行不为空
print(line)
# 定义文件名
filename1 = 'datasets/movielens/users.dat'
filename2 = 'datasets/movielens/ratings.dat'
filename3 = 'datasets/movielens/movies.dat'
# 打印每个文件的前5行
print("First 5 lines of users.dat:")
print_first_lines(filename1)
print("\nFirst 5 lines of ratings.dat:")
print_first_lines(filename2)
print("\nFirst 5 lines of movies.dat:")
print_first_lines(filename3)
这部分是先查看数据的格式,结果如下:
First 5 lines of users.dat:
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
4::M::45::7::02460
5::M::25::20::55455
First 5 lines of ratings.dat:
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275
1::2355::5::978824291
First 5 lines of movies.dat:
1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
4::Waiting to Exhale (1995)::Comedy|Drama
5::Father of the Bride Part II (1995)::Comedy
现在开始读取数据:
import pandas as pd
# Make display smaller
pd.options.display.max_rows = 10
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']
users = pd.read_table(filename1, sep='::', header=None, names=unames, engine='python')
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table(filename2, sep='::', header=None, names=rnames, engine='python')
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table(filename3, sep='::', header=None, names=mnames, engine='python')
利用Python的切片语法,通过查看每个DataFrame的前几行即可验证数据加载工作是否一切顺利:
users[:5]
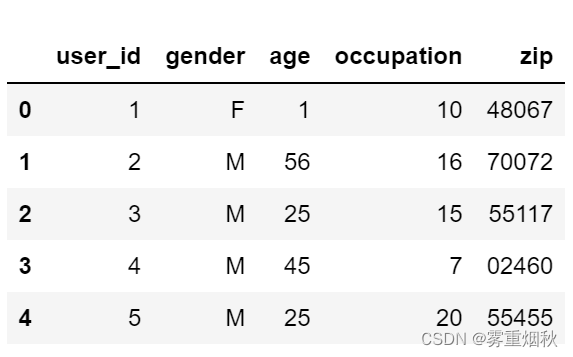
ratings[:5]
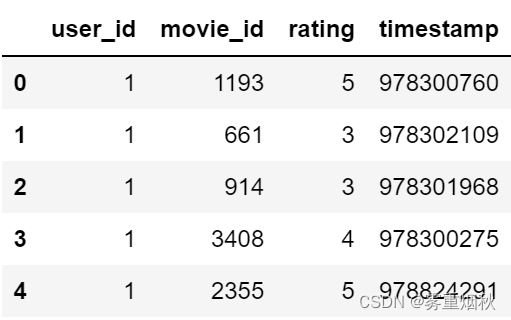
movies[:5]

ratings
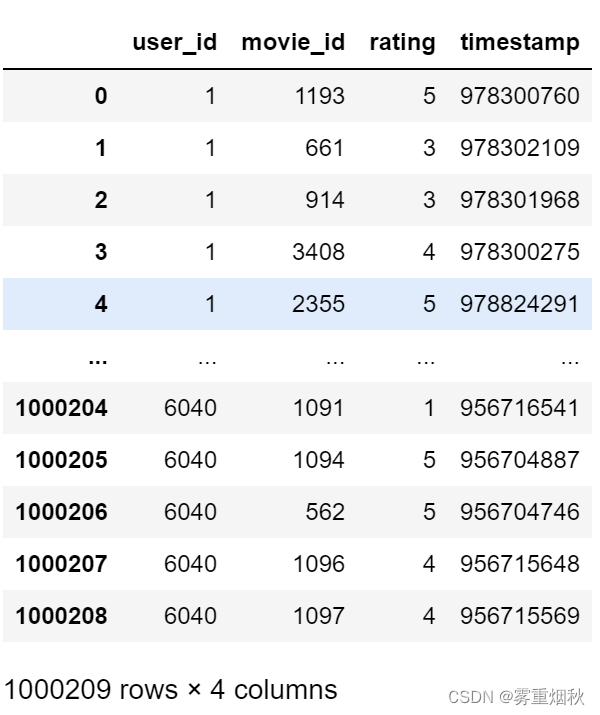
注意,其中的年龄和职业是以编码形式给出的,它们的具体含义请参考该数据集的README文件。分析散布在三个表中的数据可不是一件轻松的事情。假设我们想要根据性别和年龄计算某部电影的平均得分,如果将所有数据都合并到一个表中的话问题就简单多了。我们先用pandas的merge函数将ratings跟users合并到一起,然后再将movies也合并进去。pandas会根据列名的重叠情况推断出哪些列是合并(或连接)键:
data = pd.merge(pd.merge(ratings, users), movies)
data

data.iloc[0]
user_id 1
movie_id 1193
rating 5
timestamp 978300760
gender F
age 1
occupation 10
zip 48067
title One Flew Over the Cuckoo's Nest (1975)
genres Drama
Name: 0, dtype: object
为了按性别计算每部电影的平均得分,我们可以使用pivot_table方法(调用数据透视表pivot_table方法,要聚合的数据列是'rating',数据透视表行标签是'title',列标签是'gender',aggfunc参数指定聚合函数为'mean'):
mean_ratings = data.pivot_table('rating', index='title', columns='gender', aggfunc='mean')
mean_ratings[:5]
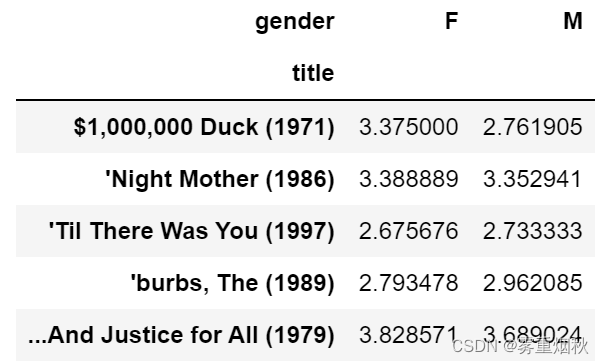
该操作产生了另一个DataFrame,其内容为电影平均得分,行标为电影名称(索引),列标为性别。现在,我打算过滤掉评分数据不够250条的电影(随便选的一个数字)。为了达到这个目的,我先对title进行分组,然后利用size()得到一个含有各电影分组大小的Series对象:
ratings_by_title = data.groupby('title').size()
ratings_by_title[:10]
title
$1,000,000 Duck (1971) 37
'Night Mother (1986) 70
'Til There Was You (1997) 52
'burbs, The (1989) 303
...And Justice for All (1979) 199
1-900 (1994) 2
10 Things I Hate About You (1999) 700
101 Dalmatians (1961) 565
101 Dalmatians (1996) 364
12 Angry Men (1957) 616
dtype: int64
activate_titles = ratings_by_title.index[ratings_by_title >= 250]
activate_titles
Index([''burbs, The (1989)', '10 Things I Hate About You (1999)',
'101 Dalmatians (1961)', '101 Dalmatians (1996)', '12 Angry Men (1957)',
'13th Warrior, The (1999)', '2 Days in the Valley (1996)',
'20,000 Leagues Under the Sea (1954)', '2001: A Space Odyssey (1968)',
'2010 (1984)',
...
'X-Men (2000)', 'Year of Living Dangerously (1982)',
'Yellow Submarine (1968)', 'You've Got Mail (1998)',
'Young Frankenstein (1974)', 'Young Guns (1988)',
'Young Guns II (1990)', 'Young Sherlock Holmes (1985)',
'Zero Effect (1998)', 'eXistenZ (1999)'],
dtype='object', name='title', length=1216)
标题索引中含有评分数据大于250条的电影名称,然后我们就可以据此从前面的mean_ratings中选取所需的行了:
mean_ratings = mean_ratings.loc[activate_titles]
mean_ratings
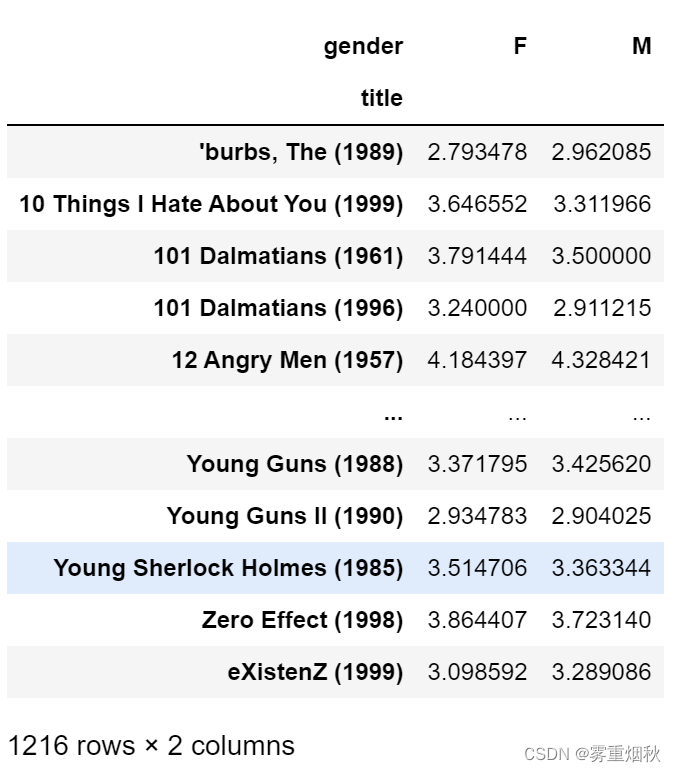
为了了解女性观众最喜欢的电影,我们可以对F列降序排列:
top_female_ratings = mean_ratings.sort_values(by='F', ascending=False)
top_female_ratings[:10]

计算评分分歧
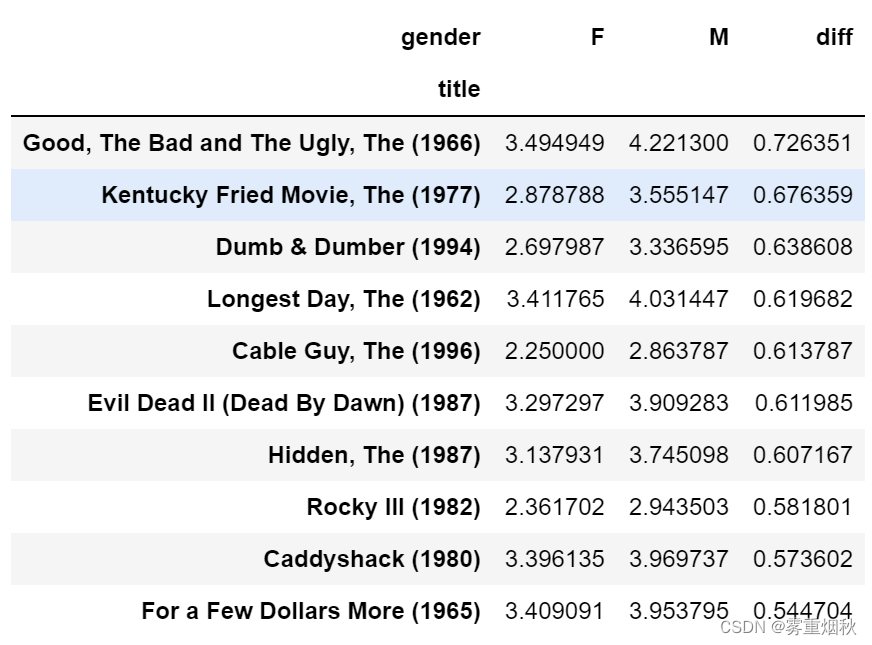
假设我们想要找出男性和女性观众分歧最大的电影。一个办法是给mean_ratings加上一个用于存放平均得分之差的列,并对其进行排序:
mean_ratings['diff'] = mean_ratings['M'] - mean_ratings['F']
按"diff"排序即可得到分歧最大且女性观众更喜欢的电影:
sorted_by_diff = mean_ratings.sort_values(by='diff')
sorted_by_diff[:10]

对排序结果反序(使用切片进行翻转,步长取-1)并取出前10行,得到的则是男性观众更喜欢的电影:
sorted_by_diff[::-1][:10]
如果只是想要找出分歧最大的电影(不考虑性别因素),则可以计算得分数据的方差或标准差:
# Standard deviation of rating grouped by title
rating_std_by_title = data.groupby('title')['rating'].std()
# Filter down to activate_titles
rating_std_by_title = rating_std_by_title.loc[activate_titles]
# Order Series by value in descending order
rating_std_by_title.sort_values(ascending=False)[:10]
title
Dumb & Dumber (1994) 1.321333
Blair Witch Project, The (1999) 1.316368
Natural Born Killers (1994) 1.307198
Tank Girl (1995) 1.277695
Rocky Horror Picture Show, The (1975) 1.260177
Eyes Wide Shut (1999) 1.259624
Evita (1996) 1.253631
Billy Madison (1995) 1.249970
Fear and Loathing in Las Vegas (1998) 1.246408
Bicentennial Man (1999) 1.245533
Name: rating, dtype: float64
可能你已经注意到了,电影分类是以竖线(|)分隔的字符串形式给出的。如果想对电影分类进行分析的话,就需要先将其转换成更有用的形式才行,这里给一部分分析方案:
把'genres'列中的每个字符串拆分成一个列表,并将这个列表存储在新的'genres'列中。
data['genres'] = data['genres'].astype(str)
data['genres'] = data['genres'].str.split('|')
data['genres']
0 [Drama]
1 [Drama]
2 [Drama]
3 [Drama]
4 [Drama]
...
1000204 [Documentary]
1000205 [Drama]
1000206 [Drama]
1000207 [Comedy, Drama, Western]
1000208 [Documentary]
Name: genres, Length: 1000209, dtype: object
直接使用列表推导式和pd.Series构造函数展平genres列:
all_genres = pd.Series([item for sublist in data['genres'] for item in sublist])
统计频率:
genre_counts = all_genres.value_counts()
genre_counts
Comedy 356580
Drama 354529
Action 257457
Thriller 189680
Sci-Fi 157294
...
Mystery 40178
Fantasy 36301
Western 20683
Film-Noir 18261
Documentary 7910
Length: 18, dtype: int64















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









