






目录
一.机器学习的简介
机器学习是一种人工智能(AI)的分支,它专注于构建能够从数据中学习的系统。其目标是使计算机系统具备一定的智能,使其能够通过数据发现模式、进行预测和做出决策,而无需显式地进行编程。
核心概念:
1.数据驱动: 机器学习的核心是通过大量的数据来训练模型,使其能够从数据中学习规律和模式。
2.模型: 模型是机器学习系统的核心组件,它可以是一个数学函数、一个算法或者一个神经网络结构。模型通过学习数据的特征和目标之间的关系来进行预测或决策。
3.特征工程: 特征工程是指对原始数据进行处理和转换,以提取出对模型训练和预测有用的特征。良好的特征工程可以显著提高模型的性能。
4训练和测试: 机器学习模型通过训练数据进行学习,然后通过测试数据进行验证和评估。训练数据用于调整模型参数,而测试数据用于评估模型的性能和泛化能力。
5.监督学习、无监督学习和强化学习: 监督学习是指模型通过已知的输入和输出来学习,无监督学习是指模型从无标记的数据中学习,而强化学习是指模型通过与环境的交互来学习最优的决策策略。
主要应用领域:
1.预测和分类: 机器学习可用于预测和分类任务,如股票价格预测、垃圾邮件过滤、图像识别和语音识别等。
2.聚类和分群: 机器学习可用于将数据分组成相似的子集,如市场细分、社交网络分析和推荐系统等。
3.回归分析: 机器学习可用于建立数据的数学模型,以预测数值型的目标变量,如房价预测、销售预测和股票价格预测等。
4.强化学习: 机器学习可用于构建智能体,使其通过与环境的交互来学习最优的行为策略,如自动驾驶汽车和游戏智能体等。
总的来说,机器学习在各个领域都有着广泛的应用,正在不断地改变着我们的生活和工作方式。
二.项目开始。
我们要以二手车市场为背景,预测二手汽车的交易价格,在这个项目中我们一定有三个数据包,used_car_sample_submit.csv这是一个示例提交文件,通常包含两列数据:一个是标识物品的唯一ID(例如“SaleID”),另一个是需要预测的目标变量(例如“price”)。比赛参与者可以使用训练好的模型对测试数据进行预测,并将预测结果保存为类似于这个示例提交文件的格式,然后提交到比赛的评估系统中进行评估。used_car_testB_20200421.zip这是一个压缩文件,其中包含训练数据集。在机器学习竞赛中,参与者通常会使用训练数据集来训练模型。该数据集通常包含多个特征列(如汽车的品牌、型号、里程等)和一个目标变量列(如汽车的价格),用于训练模型。used_car_train_20200313.zip,这也是一个压缩文件,其中包含测试数据集。测试数据集通常与训练数据集类似,但是它不包含目标变量列。参与者需要使用训练好的模型对测试数据进行预测,并生成类似于示例提交文件的格式,然后提交到比赛的评估系统中。
导入必要的包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error# 读取数据
train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
test_data = pd.read_csv('used_car_testB_20200421.csv', sep=' ')# 数据预处理
# 处理缺失值,将'-'替换为NaN
train_data.replace('-', np.nan, inplace=True)
test_data.replace('-', np.nan, inplace=True)# 填充缺失值,使用平均值填充
numeric_features = train_data.select_dtypes(include=[np.number]).columns.tolist()
if 'price' in numeric_features: # 检查'price'是否在数值型特征中
numeric_features.remove('price') # 去除'price'字段
train_data[numeric_features] = train_data[numeric_features].fillna(train_data[numeric_features].mean())
test_data[numeric_features] = test_data[numeric_features].fillna(test_data[numeric_features].mean())# 提取特征和目标变量
features = ['name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox',
'power', 'kilometer', 'notRepairedDamage', 'regionCode', 'seller', 'offerType',
'creatDate']
target = 'price'X = train_data[features]
y = train_data[target]
# 将分类变量转换为虚拟变量
X = pd.get_dummies(X)# 划分训练集和验证集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化随机森林回归模型
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
# 在训练集上训练模型
rf_regressor.fit(X_train, y_train)# 在验证集上做出预测
y_pred = rf_regressor.predict(X_valid)# 计算均方误差
mse = mean_squared_error(y_valid, y_pred)
print("验证集均方误差:", mse)# 在测试集上做出预测
X_test = pd.get_dummies(test_data[features])
test_predictions = rf_regressor.predict(X_test)# 保存预测结果
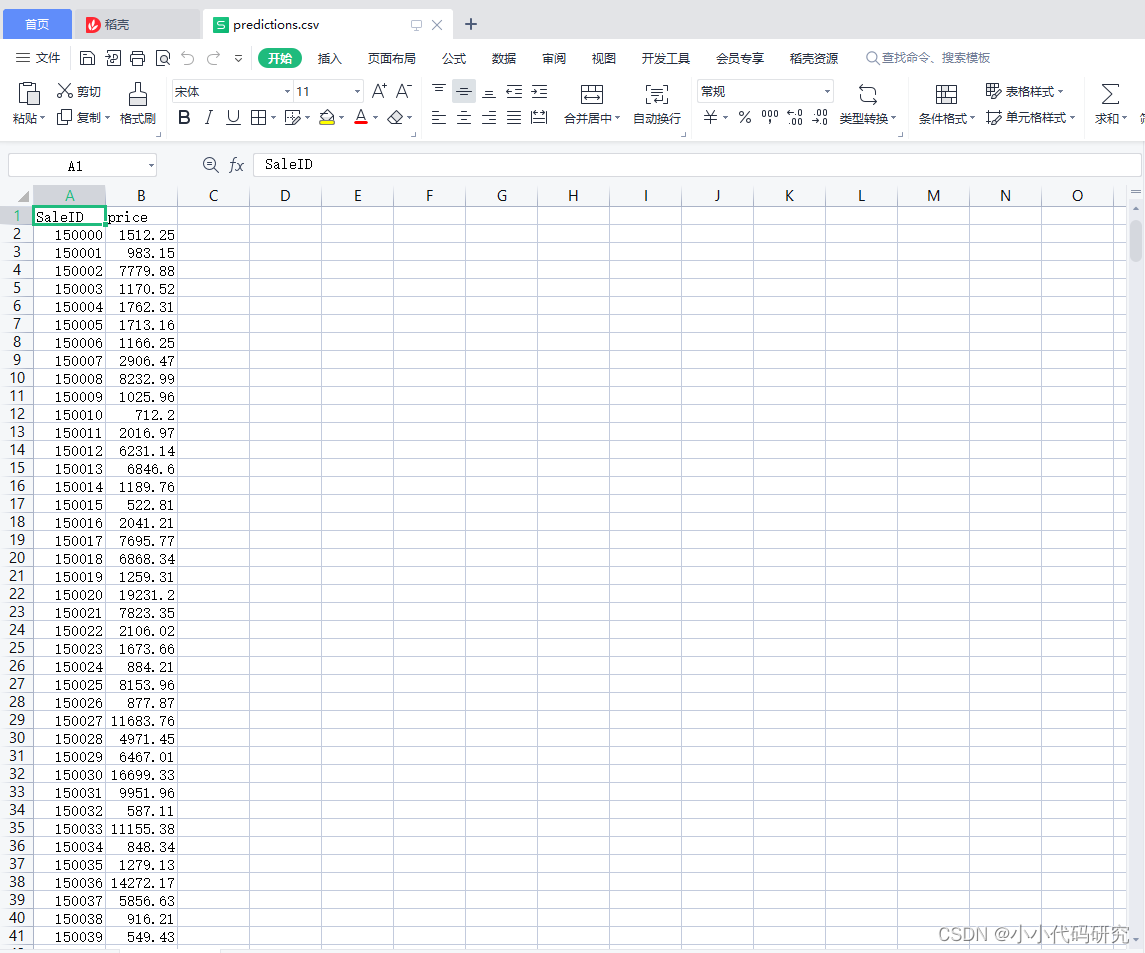
submit_sample = pd.read_csv('used_car_sample_submit.csv', sep=' ')
submit_sample['price'] = test_predictions
submit_sample.to_csv('used_car_submission.csv', index=False)运行结果
运行出来的预测值
这段代码是一个典型的机器学习项目流程,用随机森林回归模型对二手车的价格进行预测。下面是代码的主要步骤:
-
读取数据: 使用pandas库的
read_csv()函数从CSV文件中读取训练数据和测试数据。 -
数据预处理: 将缺失值(表示为'-')替换为NaN,并使用各自特征的平均值填充缺失值。
-
提取特征和目标变量: 从训练数据中提取特征和目标变量。特征包括汽车的各种属性(如名称、注册日期、品牌等),目标变量是二手车的价格。
-
转换分类变量: 将分类变量转换为虚拟变量,以便模型能够处理。
-
划分训练集和验证集: 将数据集划分为训练集和验证集,以便评估模型的性能。
-
初始化并训练模型: 初始化随机森林回归模型,并在训练集上训练模型。
-
模型评估: 在验证集上进行预测,并计算预测结果与真实值之间的均方误差,以评估模型的性能。
-
生成预测结果: 使用训练好的模型对测试集进行预测,并将预测结果保存为提交文件的格式。
-
保存预测结果: 将预测结果保存到CSV文件中,以便提交到比赛的评估系统中。















 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









