






Resvit: Residual vision transformers for multi-modal medical image synthesis(TMI2022) Paper
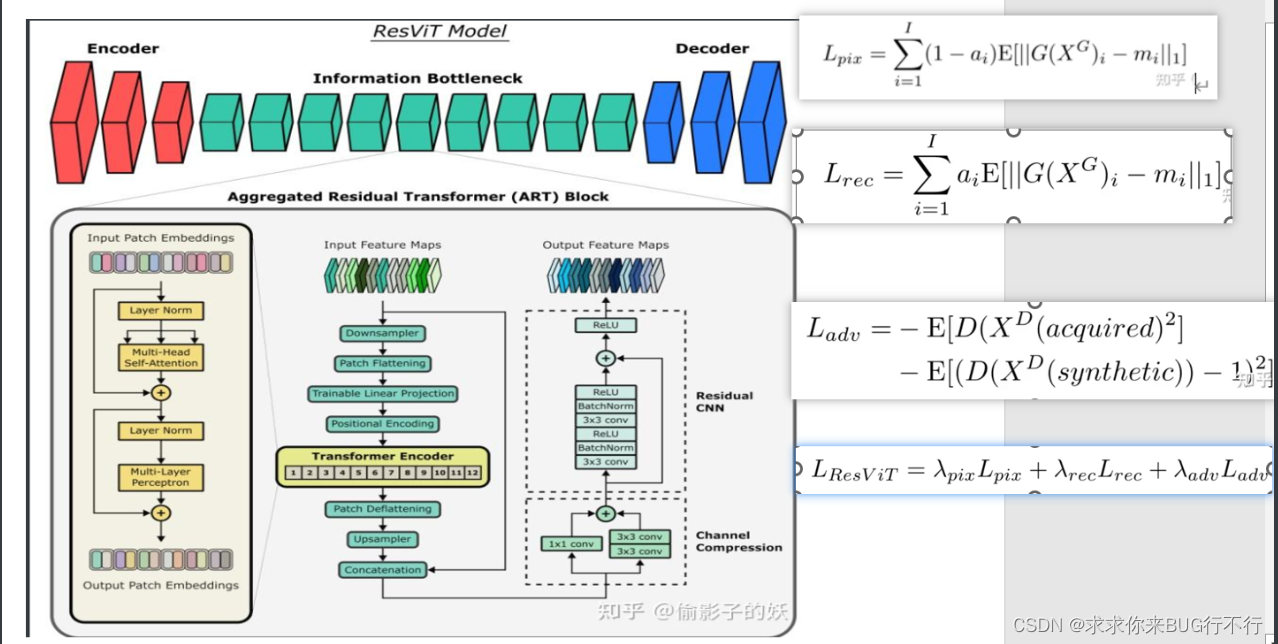
CNN 被设计为使用紧凑型滤波器执行局部处理,这种归纳偏差(inductive bias)会影响对上下文特征的学习。ResViT的生成器采用了由新型聚合残差( aggregated residual transformer–ART)块组成的中心瓶颈,该块可以协同组合 residual convolutional 和transformer模块。ART 块中的残差连接促进了捕获表征的多样性,而通道压缩模块( channel compression module)提取了与任务相关的信息。在 ART 块之间引入了权重共享策略以减轻计算负担。引入了统一的实现以避免需要为不同的源-目标模态配置重建单独的综合模型。
ResViT结合了视觉transformer对全局环境的敏感性、CNN的局部化能力以及对抗式学习的现实性,并且鉴别器使用了PatchGan
编码器-信息瓶颈-解码器路径
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation (2021.02 Arxiv) Paper
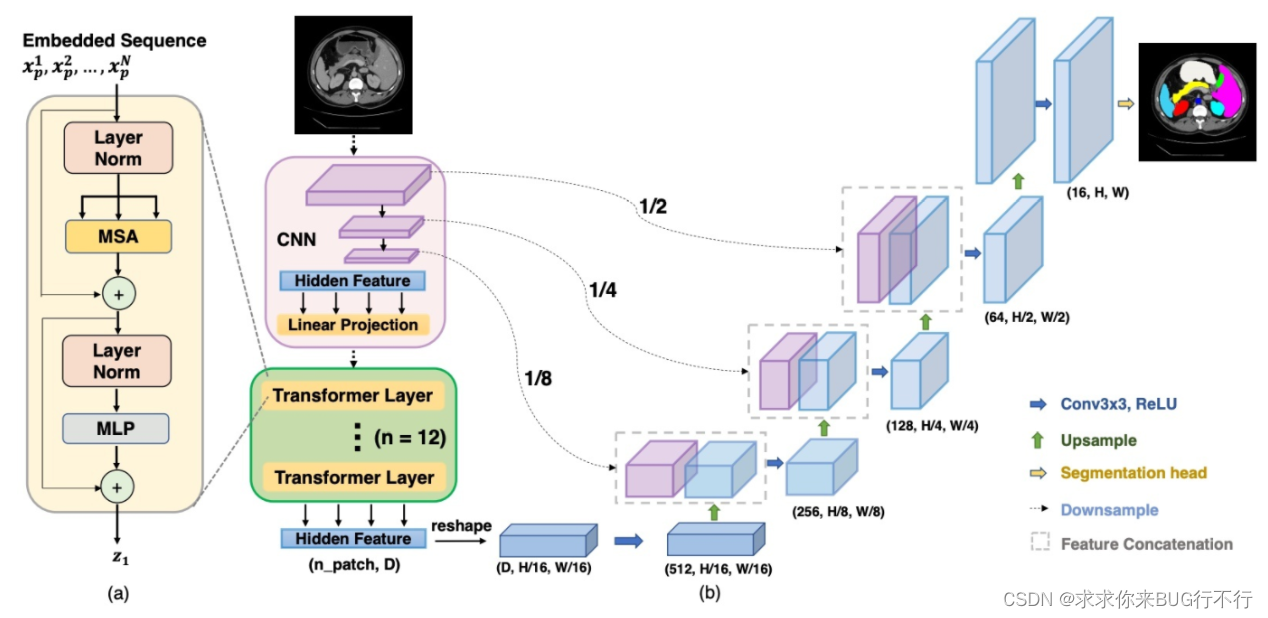
TransUNet,它兼具 Transformer 和 U-Net,作为医学图像分割的强大替代方案。一方面,Transformer 将来自卷积神经网络 (CNN) 特征映射的标记化图像块编码为用于提取全局上下文的输入序列。另一方面,解码器对编码特征进行上采样,然后将其与高分辨率 CNN 特征图相结合,以实现精确定位。
CNN:卷积的局限性. Transformer:细节把控不足。U-Net 由具有跳跃连接的对称编码器-解码器网络组成,以增强细节保留
使用Transformer对标记化的图像patch进行编码,然后直接将隐藏的特征表示上取样到一个高分辨率的密集输出中)并不能产生令人满意的结果。这是因为Transformer将输入视为1d 序列,并且在所有阶段都专注于建模全局上下文,从而导致低分辨率的特征缺乏详细的定位信息。直接上采样不能有效地恢复到完全分辨率,从而导致粗分割结果.
Transformer编码的自我关注特征被上采样,然后与跳过编码路径的不同高分辨率CNN特征相结合,以实现精确定位。产生更好的结果。
单纯使用Transformer作为编码器会导致局部信息的丢失,所以在之前加上一些CNN提取局部信息。
Masked Autoencoders Are Scalable Vision Learners (CVPR2021) Paper
本文为计算机视觉领域提出一种可扩展的自监督学习方法:MAE(Masked Autoencoders,掩膜自编码器)。MAE的做法是:随机遮盖输入图片的子块,然后重建丢失像素。其核心设计为:非对称的编码-解码架构:编码器的输入为没有被mask的子块;解码器为轻量级(解码器仅在图像重建的预训练中起作用,因此解码器设计可以独立于编码器,且灵活和轻量级),输入为编码器的输出和被mask部分的位置信息,输出为待重建的丢失像素的值。同时,经由MAE预训练的模型具有非常好的泛化性能。
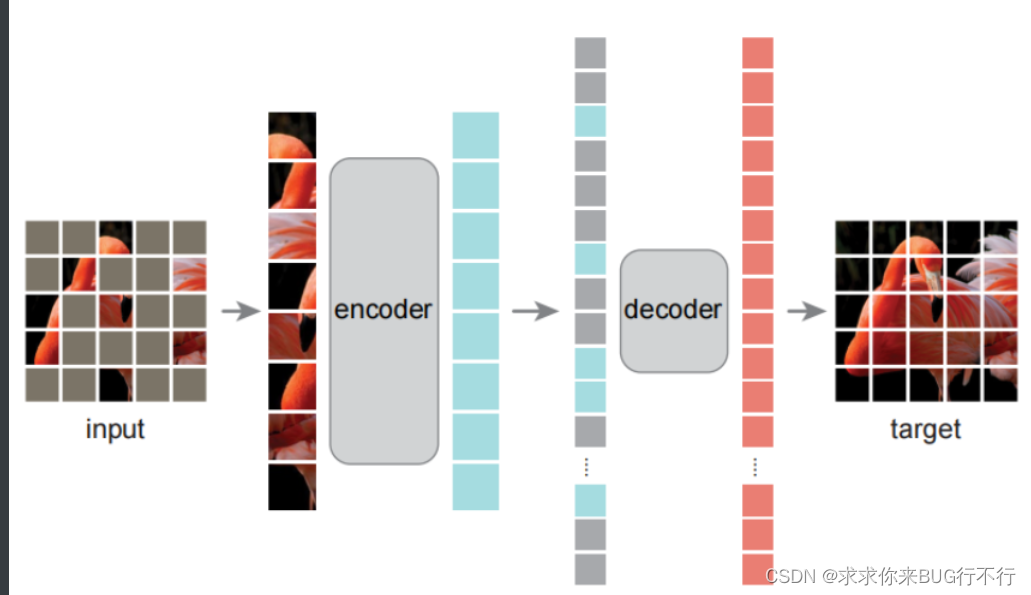
对图片切分 patch, 随机挑选少部分(比如文中25%)作为网络输入;输入通过 encoder 得到对应编码后的 encoded patches;将 encoded patches 还原到对应的原始位置,并在缺失的部分补上 masked patches;送入 decoder, 每个 decoder 预测对应 patch 的图像像素点;;计算预测的像素和原始图片的像素之间 MSE 作为 loss。取训练完的模型的 encoder 部分作为下游任务的 basemodel 并在下游任务下 finetune。服从均匀分布的无重复随机采样
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(2021) Paper
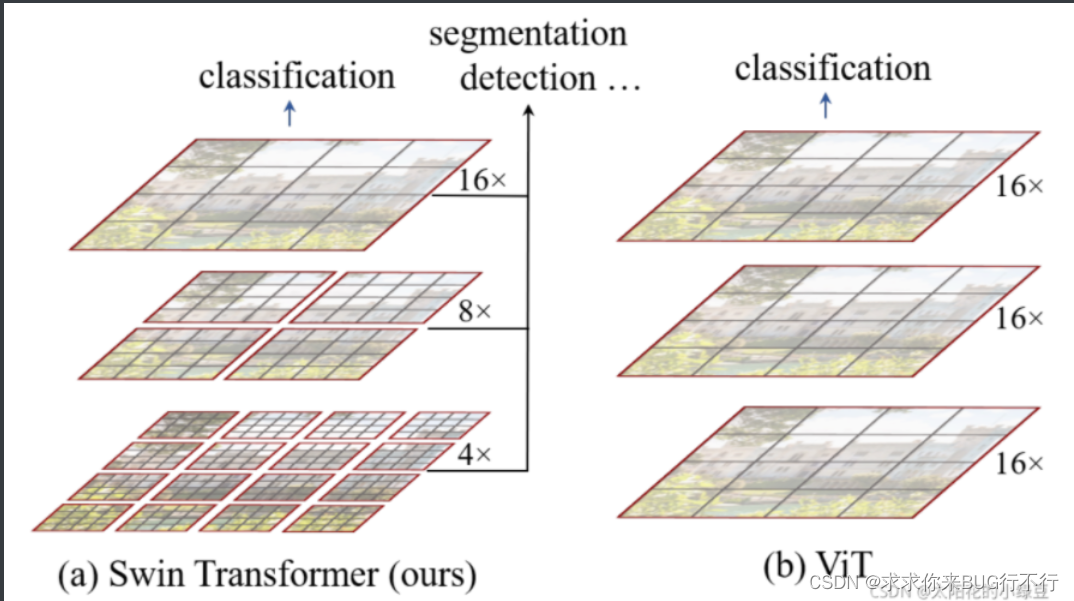
Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递,后面会细讲。
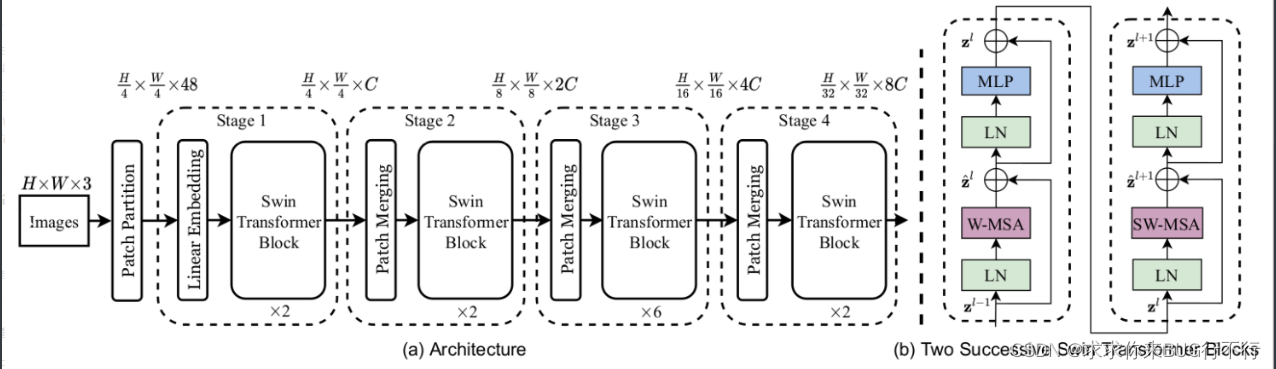
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation (2021) Paper
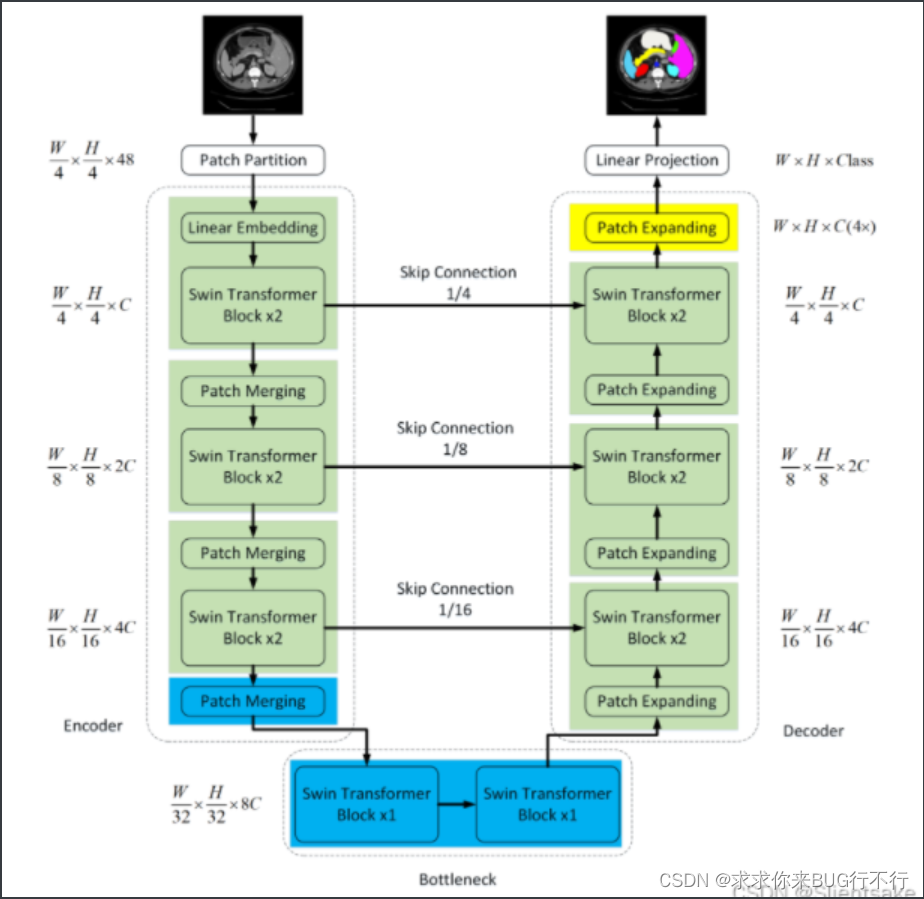
在Swin Transformer成功的激励下,作者提出Swin- unet来利用Transformer实现2D医学图像分割。它由编码器、瓶颈、解码器和跳跃连接组成。编码器、瓶颈和解码器都是基于Swin-transformer block构建的。将输入的医学图像分割成不重叠的图像patch。每个patch都被视为一个token,并被输入到基于transformer的编码器中,以学习深度特征表示。提取的上下文特征由带补丁扩展层的解码器上采样,通过跳跃连接与编码器的多尺度特征融合,恢复特征图的空间分辨率,进一步进行分割预测。开发了patch扩展层,无需卷积或插值操作即可实现上采样和特征维数的增加。
Multi-scale Transformer Network with Edge-aware Pre-training for Cross-Modality MR Image Synthesis
在现实中,我们经常有少量的配对数据,而大量的未配对数据。为了利用配对和不配对数据,在本文中,我们提出了一种具有边缘感知预训练的多尺度变换器网络(MT-Net),用于跨模态 MR 图像合成。具体来说,首先以自监督方式对边缘保留掩模自动编码器(Edge-MAE)进行预训练,以同时执行 1)每个图像中随机掩模补丁的图像插补和 2)整个边缘图估计,从而有效地学习两者上下文和结构信息。此外,还提出了一种新的 patch-wise loss,通过根据不同的掩蔽补丁各自插补的难度进行不同的处理,来增强 Edge-MAE 的性能。基于所提出的预训练,在随后的微调阶段,设计了双尺度选择性融合(DSF)模块(在我们的 MT-Net 中),通过集成从图像中提取的多尺度特征来合成缺失模态图像。预训练 Edge-MAE 的编码器。
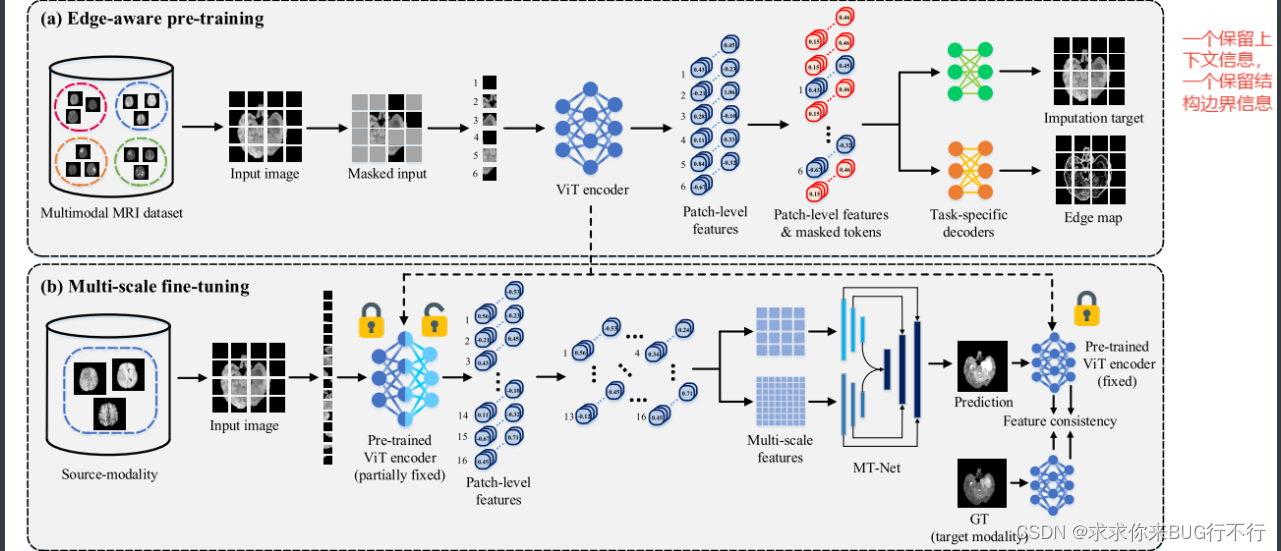
在MT-NET中,使用的是swin-unet和自定义的DSF模块。















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









