







发表时间:2021
论文地址:https://arxiv.org/abs/2102.04306
代码地址:https://github.com/Beckschen/TransUNet
1 摘要
在不同的分割任务中,U-Net已经成为一个取得巨大的成功的标准结构。由于卷积操作本身的局部性,U-Net在显式建模长距离依赖时有局限。Transformer是为序列到序列的预测设计的,是具有天生全局自注意力机制的结构,但也会因为不充分的低水平细节导致有限的定位能力。
在此论文中,提出了TransUNet,兼具了Transformer和U-Net的优点。一方面,Transformer可以对来自CNN特征图的标记化特征图像patch进行编码,编码为用于提取全局背景的输入序列。另一方面,解码器上采样编码后融合了高分辨率CNN特征图的特征,用以确保精确的定位。
我们认为,融合了U-Net恢复定位的空间信息来增强细节之后,Transformer可以作为图像分割任务的一个强大的编码器。
2 相关工作
融合CNN和自注意力机制
Transformer
3 方法
通过transformer的使用,将自注意力引入编码器。
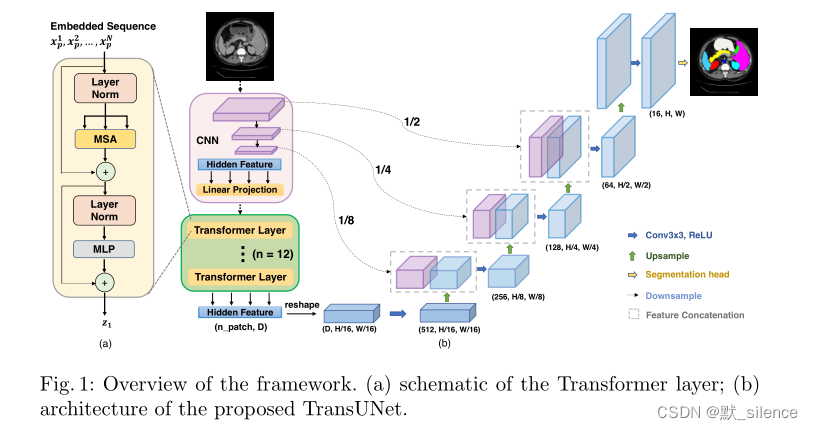
3.1 Transformer作为编码器
图像序列化
首先将输入的图像变形为一个2D的patch序列,每个patch的大小为 P×P,数量为 N = H W P 2 N=\frac{HW}{P^2} N=P2HW
patch 嵌入
我们使用一个可训练的线性投影,将向量化的patch x p x_p xp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2525
2525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









