









目录
前言
第一点:导入模块
第二点:准备数据
第三点:简单的分析数据
第四点:【重点】数据透支
总结
前言
在数据分析与挖掘的领域,了解如何使用工具和方法来探索数据是至关重要的。本文将探讨如何利用Python中的Pandas库进行数据处理和分析。我们将演示如何读取Excel文件中的数据,清洗数据并进行描述性统计,以及如何利用数据透视表来帮助我们理解数据间的关系。
第一点:导入模块
import pandas as pd
第二点:准备数据
本章需要两个表,分别为:
数据分析.xlsx
座位等级表.xlsx
第三点:简单的分析数据
df=pd.read_excel("数据分析.xlsx",index_col=0)
print(df)
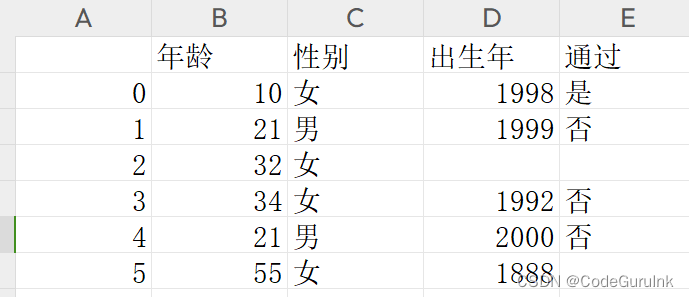
# 年龄 性别 出生年 通过
# 0 10 女 1998.0 是
# 1 21 男 1999.0 否
# 2 32 女 NaN NaN
# 3 34 女 1992.0 否
# 4 21 男 2000.0 否
# 5 55 女 1888.0 NaN
#显示数据前5条
print(df.head())
#在numpy中我们学到了聚合方法,但是操作起来太麻烦所以我们学的是pandas中的描述方法,他包含了所有聚合函数,非常实用
#描述方法
print(df.describe())
# 年龄 出生年
# count 6.000000 5.000000
# mean 28.833333 1975.400000
# std 15.484401 48.957124
# min 10.000000 1888.000000
# 25% 21.000000 1992.000000
# 50% 26.500000 1998.000000
# 75% 33.500000 1999.000000
# max 55.000000 2000.000000第四点:【重点】数据透支
# 数据透视对数据分析十分重要
#导入表
df=pd.read_excel("座位等级表.xlsx",index_col=0)
df=pd.DataFrame(df)
print(df.head())
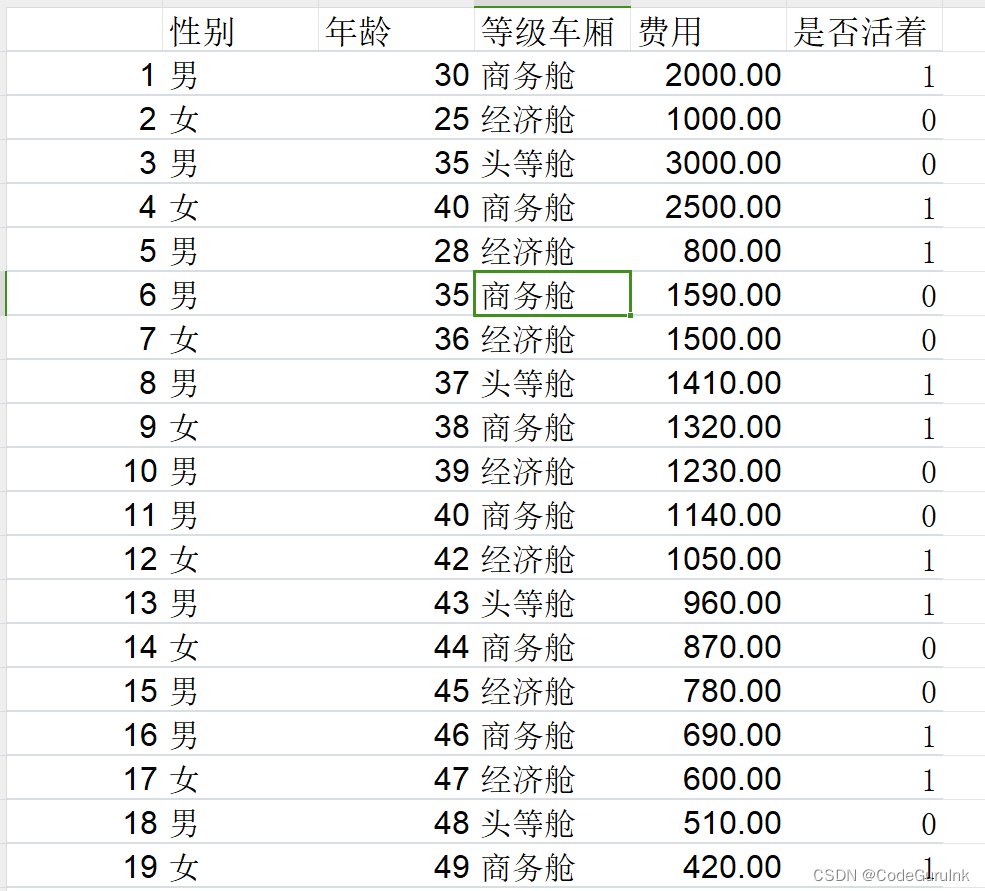
# 性别 年龄 等级车厢 费用 是否活着
# 1 男 30.0 商务舱 2000 是
# 2 女 25.0 经济舱 1000 否
# 3 男 35.0 头等舱 3000 是
# 4 女 40.0 商务舱 2500 是
# 5 男 28.0 经济舱 800 否
#我们把性别 年龄 等级车厢 费用认为是神经网络的输入特征,是否活着为输出特征
#第一步:我们先把性别作为特征,意思为性别是怎么影响是否活着的数据
# df.pivot_table默认值为mean
print(df.pivot_table("是否活着",index='性别'))
# 性别
# 女 0.6
# 男 0.5
#两个特征:性别,座位等级
print(df.pivot_table("是否活着",index='性别',columns='等级车厢'))
# 等级车厢 商务舱 头等舱 经济舱
# 性别
# 女 0.666667 1.000000 0.500000
# 男 0.500000 0.571429 0.428571前面的实列只涉及到两个特征,有时候需要考察更多特征与输出特征的关系,这里,我讲把年龄和费用都加进去,但是这两个特征的数值很分散,不能像性别和车辆等级可以按照类分别,因此,需要涉及到数据透视表配套的两个重要函数,pd.cut()和pd.qcut。
#重置年龄列
age=pd.cut(df['年龄'],[0,50,120]) #以50为分水岭
print(age)
#三个特征
print(df.pivot_table("是否活着",index=["性别",age],columns="等级车厢",observed=False))
# 等级车厢 商务舱 头等舱 经济舱
# 性别 年龄
# 女 (0, 50] 0.75 NaN 0.500000
# (50, 120] 0.50 1.000000 0.500000
# 男 (0, 50] 0.50 0.500000 0.333333
# (50, 120] 0.50 0.666667 0.500000
#重置费用列
fare=pd.qcut(df['费用'],2) #自动分割成两部分
print(fare)
#四个特征
print(df.pivot_table('是否活着',index=['等级车厢',fare],columns=["性别",age],observed=False))
# 性别 女 男
# 年龄 (0, 50] (50, 120] (0, 50] (50, 120]
# 等级车厢 费用
# 商务舱 (419.999, 870.0] 0.500000 0.000000 1.000000 0.333333
# (870.0, 3300.0] 1.000000 1.000000 0.333333 1.000000
# 头等舱 (419.999, 870.0] NaN 1.000000 0.000000 0.666667
# (870.0, 3300.0] NaN NaN 0.666667 NaN
# 经济舱 (419.999, 870.0] 1.000000 0.333333 0.500000 0.000000
# (870.0, 3300.0] 0.333333 1.000000 0.000000 0.666667总结
通过本文,我们学习了如何利用Pandas库进行数据分析的基本步骤,包括数据的读取、清洗和描述性统计分析,以及如何利用数据透视表来探索数据间的关联。在实际的数据分析工作中,这些步骤是非常常见且必要的。通过不断练习和探索,我们可以更加熟练地运用这些技能,从而更好地理解和利用数据。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









