







完整源码、数据集获取可联系博主
一、引言
随着社交媒体的普及和互联网技术的飞速发展,人们越来越倾向于在社交媒体平台上表达自己的观点和情感。这些海量的用户生成内容(User-Generated Content, UGC)为企业决策、舆情分析、品牌管理等提供了丰富的数据资源。因此,如何有效地分析社交媒体用户的情感倾向,成为了一个重要的研究课题。近年来,深度学习技术,特别是循环神经网络(Recurrent Neural Networks, RNN)及其变体长短时记忆网络(Long Short-Term Memory, LSTM),在自然语言处理领域取得了显著的进展。本文旨在综述基于LSTM的社交媒体用户情感倾向分析及检测系统的设计与实现。
二、LSTM概述
LSTM是一种特殊的RNN,它通过引入记忆细胞、输入门、输出门和遗忘门的概念,解决了传统RNN在处理长序列数据时存在的梯度消失和梯度爆炸问题。LSTM能够学习并记忆序列数据中的长期依赖关系,因此在处理文本、语音等序列数据方面表现出色。在情感分析任务中,LSTM能够有效地捕捉文本中的上下文信息,提高情感分析的准确性。
三、基于LSTM的社交媒体用户情感倾向分析
社交媒体用户情感倾向分析主要涉及文本情感分类、观点提取、情绪识别等任务。基于LSTM的情感分析方法主要包括以下几个步骤:
数据预处理:对社交媒体文本进行清洗、分词、去除停用词等预处理操作,以提高数据质量。
特征提取:利用LSTM模型对预处理后的文本进行特征提取。LSTM能够自动学习文本中的语义特征和情感特征,为后续的情感分类提供有力的支持。
情感分类:将提取到的特征输入到分类器中进行情感分类。可以采用多种分类算法,如softmax回归、支持向量机等。在训练过程中,需要使用已标注的情感倾向数据集进行模型训练。
结果评估:通过准确率、召回率、F1值等指标对模型进行评估,以检验模型的性能。
四、检测系统设计与实现
基于LSTM的社交媒体用户情感倾向检测系统主要包括以下几个部分:
数据采集:通过API接口或爬虫技术从社交媒体平台上获取用户生成的文本数据。
实时处理:对采集到的文本数据进行实时处理,包括文本预处理、特征提取和情感分类等步骤。为了提高系统的实时性,可以采用并行计算和分布式计算等技术。
结果展示:将情感分类的结果以可视化的形式展示给用户,如柱状图、饼图等。同时,系统还可以提供交互功能,允许用户根据需要对结果进行筛选和查询。
反馈机制:建立用户反馈机制,收集用户对系统性能的评价和建议,以便对系统进行优化和改进。
五、结论与展望
本文综述了基于LSTM的社交媒体用户情感倾向分析及检测系统的设计与实现。该系统能够有效地分析社交媒体用户的情感倾向,为企业决策、舆情分析、品牌管理等提供有力的支持。未来,可以进一步探索LSTM与其他深度学习技术的结合,如注意力机制、Transformer等,以提高系统的性能和泛化能力。同时,也可以关注跨领域和跨模态的情感分析问题,如文本与图像、音频等多模态数据的情感分析。
数据集介绍:
包括neutral.csv(中性)、pos.csv(积极)、neg.csv(消极)三部分,总计共十万多条评论信息。

核心源码:
模型训练部分:
import pandas as pd
import numpy as np
import jieba
import multiprocessing
import keras.utils
from gensim.models.word2vec import Word2Vec
from gensim.corpora.dictionary import Dictionary
from keras.preprocessing import sequence
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Embedding
from keras.layers import LSTM
from keras.layers import Dense, Dropout,Activation
# from keras.models import model_from_yaml
np.random.seed(1337) # For Reproducibility
import sys
# 设置程序最大的递归深度
sys.setrecursionlimit(1000000)
import yaml
# set parameters:
cpu_count = multiprocessing.cpu_count() # 4
vocab_dim = 100
n_iterations = 1 # ideally more..
# 词频超过10的词语纳入考量
n_exposures = 10 # 所有频数超过10的词语
# 在Word2Vec中,窗口大小决定了中心词与上下文词之间的最大距离。这里设置为7,意味着在训练时会考虑中心词前后各7个词作为上下文。
window_size = 7
# 训练周期数。这里设置为4,意味着整个数据集将被遍历4次来训练模型。
n_epoch = 4
input_length = 100
maxlen = 100
# 批处理大小。这里设置为32,意味着在每次迭代中,模型将使用32个样本(通常是32个文本序列)来进行一次权重更新。
batch_size = 32
def loadfile():
neg=pd.read_csv('./data/neg.csv',header=None,index_col=None)
pos=pd.read_csv('./data/pos.csv',header=None,index_col=None)
neu=pd.read_csv('./data/neutral.csv', header=None, index_col=None)
combined = np.concatenate((pos[0], neu[0], neg[0]))
y = np.concatenate((np.ones(len(pos), dtype=int), np.zeros(len(neu), dtype=int),
-1*np.ones(len(neg),dtype=int)))
return combined,y
#对句子经行分词,并去掉换行符
def tokenizer(text):
''' Simple Parser converting each document to lower-case, then
removing the breaks for new lines and finally splitting on the
whitespace
'''
text = [jieba.lcut(document.replace('\n', '')) for document in text]
return text
def create_dictionaries(model=None,
combined=None):
''' Function does are number of Jobs:
1- Creates a word to index mapping
2- Creates a word to vector mapping
3- Transforms the Training and Testing Dictionaries
'''
if (combined is not None) and (model is not None):
gensim_dict = Dictionary()
words = list(model.wv.key_to_index.keys())
gensim_dict.doc2bow(words,
allow_update=True)
# freqxiao10->0 所以k+1
w2indx = {word: index + 1 for index, word in enumerate(words)}
# w2indx = {v: k+1 for k, v in gensim_dict.items()}#所有频数超过10的词语的索引,(k->v)=>(v->k)
# f = open("./lstm/word2index.txt",'w',encoding='utf8')
# for key in w2indx:
# f.write(str(key))
# f.write(' ')
# f.write(str(w2indx[key]))
# f.write('\n')
with open("./lstm/word2index.txt", 'w', encoding='utf8') as f:
for word, index in w2indx.items():
f.write(f"{word}|{index}\n")
f.close()
w2vec = {word: model.wv[word] for word in w2indx.keys()}
# w2vec = {word: model.wv[word] for word in w2indx.keys()}#所有频数超过10的词语的词向量, (word->model(word))
def parse_dataset(combined): # 闭包-->临时使用
''' Words become integers
'''
data=[]
for sentence in combined:
new_txt = []
for word in sentence:
try:
new_txt.append(w2indx[word])
except:
new_txt.append(0) # freqxiao10->0
data.append(new_txt)
return data # word=>index
combined=parse_dataset(combined) #[[1,2,3...],[]]
combined= sequence.pad_sequences(combined, maxlen=maxlen)#每个句子所含词语对应的索引,所以句子中含有频数小于10的词语,索引为0
return w2indx, w2vec,combined
else:
print ('No data provided...')
#创建词语字典,并返回每个词语的索引,词向量,以及每个句子所对应的词语索引
# 创建一个词嵌入模型
def word2vec_train(combined):
# 词长度100
# 最低词频10
# 窗口大小7
model = Word2Vec(vector_size=vocab_dim,
min_count=n_exposures,
window=window_size,
workers=cpu_count)
# iter=n_iterations)
model.build_vocab(combined) # input: list
model.train(combined,total_examples=model.corpus_count,epochs=n_iterations)
model.save('./model/Word2vec_model.pkl')
index_dict, word_vectors,combined = create_dictionaries(model=model,combined=combined)
return index_dict, word_vectors,combined
def get_data(index_dict,word_vectors,combined,y):
n_symbols = len(index_dict) + 1 # 所有单词的索引数,频数小于10的词语索引为0,所以加1
embedding_weights = np.zeros((n_symbols, vocab_dim)) # 初始化 索引为0的词语,词向量全为0
for word, index in index_dict.items(): # 从索引为1的词语开始,对每个词语对应其词向量
embedding_weights[index, :] = word_vectors[word]
x_train, x_test, y_train, y_test = train_test_split(combined, y, test_size=0.2)
y_train = keras.utils.to_categorical(y_train,num_classes=3) #转换为对应one-hot 表示 [len(y),3]
y_test = keras.utils.to_categorical(y_test,num_classes=3)
# print x_train.shape,y_train.shape
return n_symbols,embedding_weights,x_train,y_train,x_test,y_test
##定义网络结构
def train_lstm(n_symbols,embedding_weights,x_train,y_train,x_test,y_test):
print ('Defining a Simple Keras Model...')
model = Sequential() # or Graph or whatever
model.add(Embedding(output_dim=vocab_dim,
input_dim=n_symbols,
mask_zero=True,
weights=[embedding_weights],
input_length=input_length)) # Adding Input Length
model.add(LSTM(units=50, activation='tanh'))
#model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax')) # Dense=>全连接层,输出维度=3
model.add(Activation('softmax'))
print ('Compiling the Model...')
model.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
print ("Train...") # batch_size=32
model.fit(x_train, y_train, batch_size=batch_size, epochs=n_epoch,verbose=1)
print ("Evaluate...")
score = model.evaluate(x_test, y_test,
batch_size=batch_size)
# yaml_string = model.to_yaml()
# with open('./model/lstm.yml', 'w') as outfile:
# outfile.write(yaml_string)
# outfile.write( yaml.dump(yaml_string, default_flow_style=True) )
json_string = model.to_json()
with open('./model/lstm.json', 'w') as outfile:
outfile.write(json_string)
model.save_weights('./model/lstm.h5')
print ('Test score:', score)
if __name__=='__main__':
#训练模型,并保存
print ('Loading Data...')
# 读取训练数据
combined,y=loadfile() #[, , ]
print (len(combined),len(y))
print ('Tokenising...')
# 对句子进行分词
combined = tokenizer(combined)#[['gao','shuangc','chao'...],[]...]
print ('Training a Word2vec model...')
# 训练一个词向量模型
index_dict, word_vectors,combined=word2vec_train(combined) #[[2,3,4...],[]...]
print ('Setting up Arrays for Keras Embedding Layer...')
n_symbols,embedding_weights,x_train,y_train,x_test,y_test=get_data(index_dict, word_vectors,combined,y)#n_sym:num_words emb:[key:embeding]
print ("x_train.shape and y_train.shape:")
print (x_train.shape,y_train.shape)
train_lstm(n_symbols,embedding_weights,x_train,y_train,x_test,y_test)
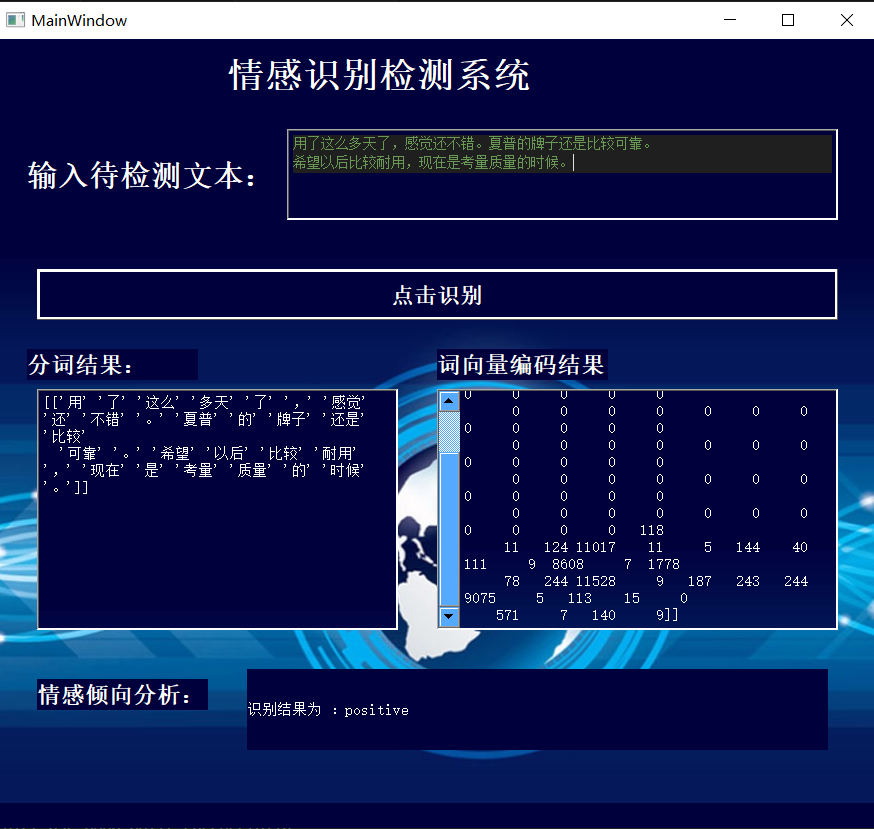
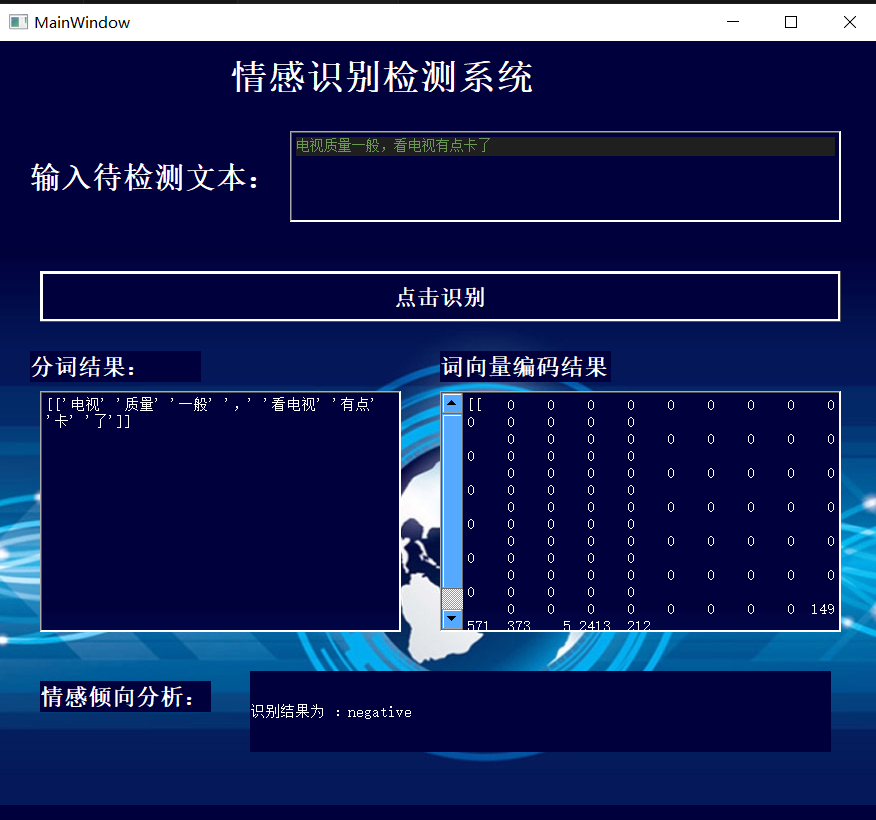
可视化方面,采用Pyqt设计实现简单的界面,对模型能力进行展示
















 4862
4862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











