







完整项目源码获取:
点击下载
1、资源项目源码均已通过严格测试验证,保证能够正常运行;
2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通;
3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于人工智能、计算机科学与技术等相关专业,更为适合;
4、下载使用后,可先查看README.md文件(如有),本项目仅用作交流学习参考,请切勿用于商业用途。
部分内容来源于网络搜集,如有侵权请联系作者删除
1、项目介绍
本项目是基于卷积神经网络模型开展表情识别的研究,为了尽可能的提高最终表情识别的准确性,需要大量的样本图片训练,优化,所以采用了 FER2013 数据集用来训练、测试,此数据集由 35886 张人脸表情图片组成,其中,测试图 28708 张,公共验证图和私有验证图各 3589 张,所有图片中共有7种表情。在预处理时把图像归一化为 48×48 像素,训练的网络结构是基于 CNN 网络结构的优化改进后的一个开源的网络结构,下文中会具体介绍到,通过不断地改进优化,缩小损失率,最终能达到较准确的识别出人的面部表情的结果。
2、项目数据集介绍及数据预处理
FER2013数据集由28709张训练图,3589张公开测试图和3589张私有测试图组成。每一张图都是像素为48*48的灰度图。FER2013数据库中一共有7中表情:愤怒,厌恶,恐惧,开心,难过,惊讶和中性。该数据库是2013年Kaggle比赛的数据,由于这个数据库大多是从网络爬虫下载的,存在一定的误差性。这个数据库的人为准确率是65% 士 5%。
给定的数据集train.csv,我们要使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情。在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过,(5)惊讶和(6)中立(即面无表情,无法归为前六类)。因此,项目实质上是一个7分类问题。

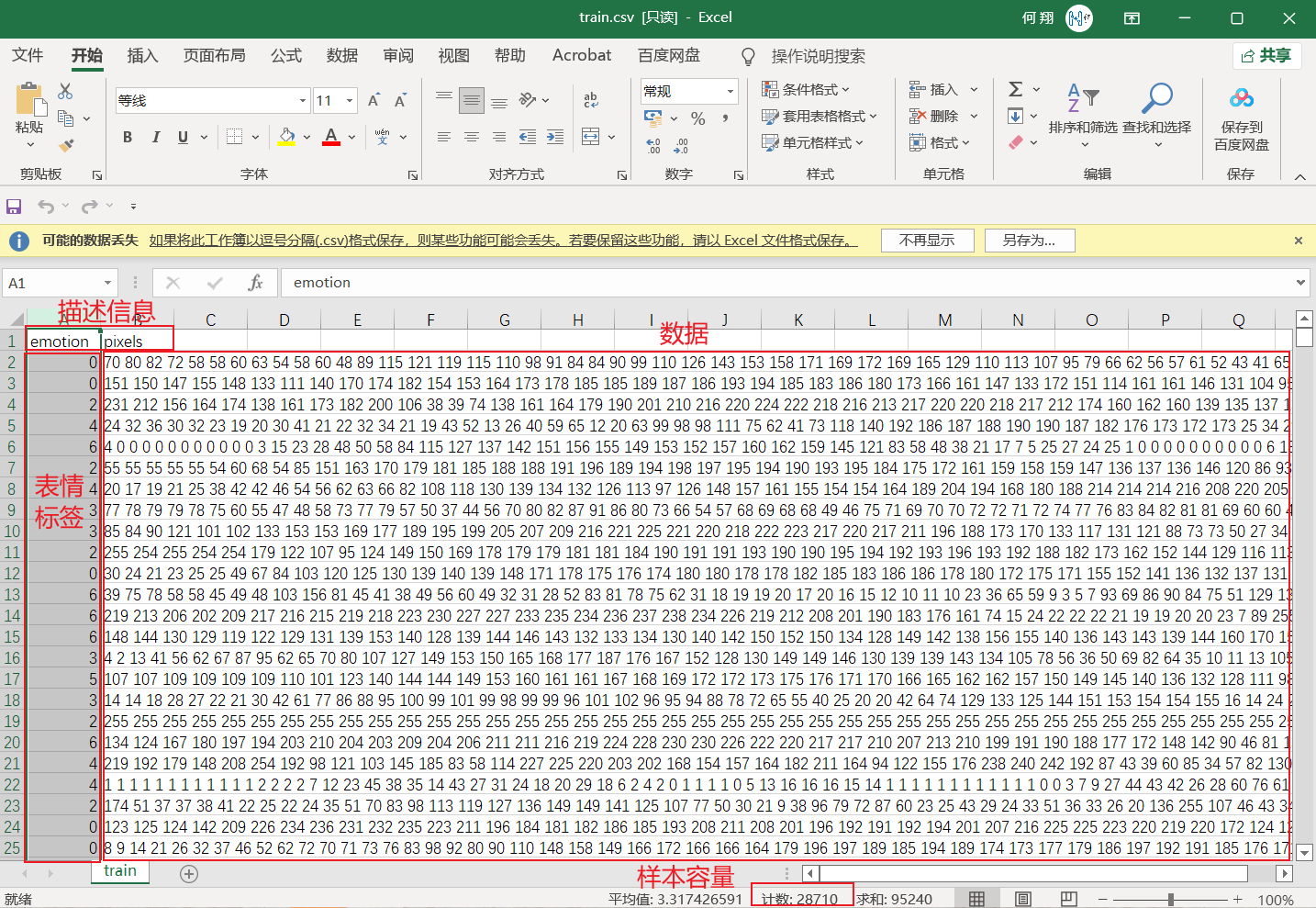
train.csv文件说明:
(1)CSV文件,大小为28710行X2305列;
(2)在28710行中,其中第一行为描述信息,即“emotion”和“pixels”两个单词,其余每行内含有一个样本信息,即共有28709个样本;
(3)在2305列中,其中第一列为该样本对应的emotion,取值范围为0到6。其余2304列为包含着每个样本大小为48X48人脸图片的像素值(2304=48X48),每个像素值取值范围在0到255之间;
在原文件中,emotion和pixels人脸像素数据是集中在一起的。为了方便操作,决定利用pandas库进行数据分离,即将所有emotion读出后,写入新创建的文件emotion.csv;将所有的像素数据读出后,写入新创建的文件pixels.csv。
数据集分离的代码如下:
# 将emotion和pixels像素数据分离
import pandas as pd
# 注意修改train.csv为你电脑上文件所在的相对或绝对路劲地址。
path = 'dataset/train.csv'
# 读取数据
df = pd.read_csv(path)
# 提取emotion数据
df_y = df[['emotion']]
# 提取pixels数据
df_x = df[['pixels']]
# 将emotion写入emotion.csv
df_y.to_csv('dataset/emotion.csv', index=False, header=False)
# 将pixels数据写入pixels.csv
df_x.to_csv('dataset/pixels.csv', index=False, header=False)
以上代码执行完毕后,在dataset的文件夹下,就会生成两个新文件emotion.csv以及pixels.csv。在执行代码前,注意修改train.csv为你电脑上文件所在的相对或绝对路劲地址。
给定的数据集是csv格式的,考虑到图片分类问题的常规做法,决定先将其全部可视化,还原为图片文件再送进模型进行处理。
在python环境下,将csv中的像素数据还原为图片并保存下来,有很多库都能实现类似的功能,如pillow,opencv等。这里我采用的是用opencv来实现这一功能。
将数据分离后,人脸像素数据全部存储在pixels.csv文件中,其中每行数据就是一张人脸。按行读取数据,利用opencv将每行的2304个数据恢复为一张48X48的人脸图片,并保存为jpg格式。在保存这些图片时,将第一行数据恢复出的人脸命名为0.jpg,第二行的人脸命名为1.jpg…,以方便与label[0]、label[1]…一一对应。
import cv2
import numpy as np
# 指定存放图片的路径
path = 'face_images'
# 读取像素数据
data = np.loadtxt('dataset/pixels.csv')
# 按行取数据
for i in range(data.shape[0]):
face_array = data[i, :].reshape((48, 48)) # reshape
cv2.imwrite(path + '//' + '{}.jpg'.format(i), face_array) # 写图片
以上代码虽短,但涉及到大量数据的读取和大批图片的写入,因此占用的内存资源较多,且执行时间较长(视机器性能而定,一般要几分钟到十几分钟不等)。代码执行完毕,我们来到指定的图片存储路径,就能发现里面全部是写好的人脸图片。

创建image图片名和对应emotion表情数据集的映射关系表。
首先,我们需要划分一下训练集和验证集。在项目中,共有28709张图片,取前24000张图片作为训练集,其他图片作为验证集。新建文件夹train_set和verify_set,将0.jpg到23999.jpg放进文件夹train_set,将其他图片放进文件夹verify_set。
在继承torch.utils.data.Dataset类定制自己的数据集时,由于在数据加载过程中需要同时加载出一个样本的数据及其对应的emotion,因此最好能建立一个image的图片名和对应emotion表情数据的关系映射表,其中记录着image的图片名和其emotion表情数据的映射关系。
这里需要和大家强调一下:大家在人脸可视化过程中,每张图片的命名不是都和emotion的存放顺序是一一对应的。在实际操作的过程中才发现,程序加载文件的机制是按照文件名首字母(或数字)来的,即加载次序是0,1,10,100…,而不是预想中的0,1,2,3…,因此加载出来的图片不能够和emotion[0],emotion[1],emotion[2],emotion[3]…一一对应,所以建立image-emotion映射关系表还是相当有必要的。
建立image-emotion映射表的基本思路就是:指定文件夹(train_set或verify_set),遍历该文件夹下的所有文件,如果该文件是.jpg格式的图片,就将其图片名写入一个列表,同时通过图片名索引出其emotion,将其emotion写入另一个列表。最后利用pandas库将这两个列表写入同一个csv文件。
3、构建网络模型
传统CNN模型
卷积神经网络(CNN)是一种前馈神经网络,它包括卷积计算并具有较深的结构,因此是深度学习的代表性算法之一。随着科技的不断进步,人们在研究人脑组织时受启发创立了神经网络。神经网络由很多相互联系的神经元组成,并且可以在不同的神经元之间通过调整传递彼此之间联系的权重系数 x 来增强或抑制信号。标准卷积神经网络通常由输入层、卷积层、池化层、全连接层和输出层组成,如下图所示:
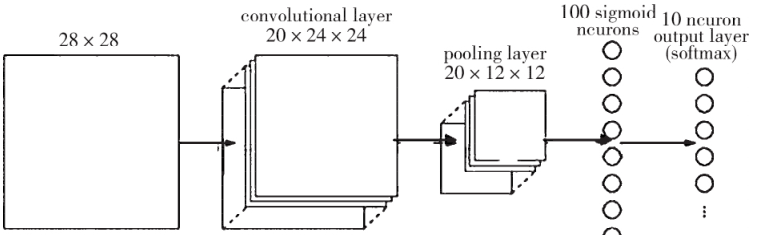
上图中第一层为输入层,大小为 28×28,然后通过 20×24×24 的卷积层,得到的结果再输入池化层中,最后再通过图中第四层既全连接层,直到最后输出。
下图为CNN常见的网络模型。其中包括 4 个卷积层,3 个池化层,池化层的大小为 3×3,最终再通过两个全连接层到达输出层。网络模型中的输入层一般是一个矩阵,卷积层,池化层和全连接层可以当作隐藏层,这些层通常具有不同的计算方法,需要学习权重以找到最佳值。

从上述中可知,标准卷积神经网络除了输入和输出外,还主要具有三种类型:池化层,全连接层和卷积层。这三个层次是卷积神经网络的核心部分。
卷积层
卷积层是卷积神经网络的第一层,由几个卷积单元组成。每个卷积单元的参数可以通过反向传播算法进行优化,其目的是提取输入的各种特征,但是卷积层的第一层只能提取低级特征,例如边、线和角。更多层的可以提取更高级的特征,利用卷积层对人脸面部图像进行特征提取。一般卷积层结构如下图所示,卷积层可以包含多个卷积面,并且每个卷积面都与一个卷积核相关联。
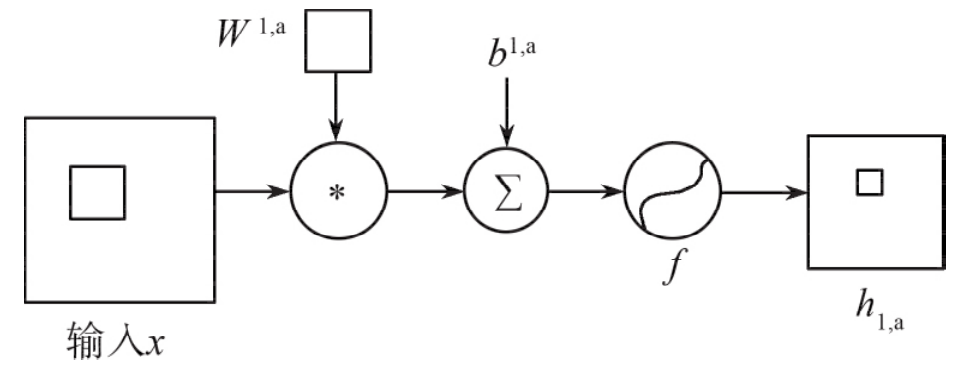
由上图可知,每次执行卷积层计算时,都会生成与之相关的多个权重参数,这些权重参数的数量与卷积层的数量相关,即与卷积层所用的函数有直接的关系。
池化层
在卷积神经网络中第二个隐藏层便是池化层,在卷积神经网络中,池化层通常会在卷积层之间,由此对于缩小参数矩阵的尺寸有很大帮助,也可以大幅减少全连接层中的参数数量。此外池化层在加快计算速度和防止过拟合方面也有很大的作用。在识别图像的过程中,有时会遇到较大的图像,此时希望减少训练参数的数量,这时需要引入池化层。池化的唯一目的是减小图像空间的大小。常用的有 mean-pooling 和max-pooling。mean-pooling 即对一小块区域取平均值,假设 pooling 窗的大小是 2×2,那么就是在前面卷积层的输出的不重叠地进行 2×2 的取平均值降采样,就得到 mean-pooling 的值。不重叠的 4 个 2×2 区域分别 mean-pooling 如下图所示。
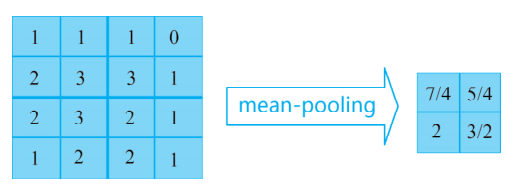
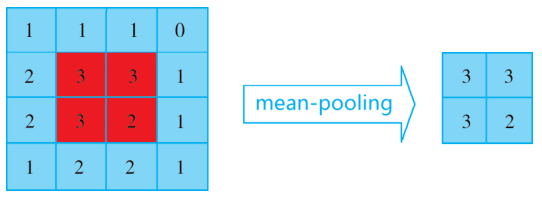
max-pooling 即对一小块区域取最大值,假设 pooling 的窗大小是 2×2,就是在前面卷积层的输出的不重叠地进行 2×2 的取最大值降采样,就得到 max-pooling 的值。不重叠的 4 个 2×2 区域分别max-pooling 如下图所示:
全连接层
卷积神经网络中的最后一个隐藏层是全连接层。该层的角色与之前的隐藏层完全不同。卷积层和池化层的功能均用于面部图像的特征提取,而全连接层的主要功能就是对图像的特征矩阵进行分类。根据不同的状况,它可以是一层或多层。
通过该层的图片可以高度浓缩为一个数。由此全连接层的输出就是高度提纯的特征了,便于移交给最后的分类器或者回归。
网络的训练
神经网络通过自学习的方式可以获得高度抽象的,手工特征无法达到的特征,在计算机视觉领域已经取得了革命性的突破。被广泛的应用于生活中的各方面。而要想让神经网络智能化,必须对它进行训练,在训练过程中一个重要的算法就是反向传播算法。反向传播算法主要是不断调整网络的权重和阈值,以得到最小化网络的平方误差之和,然后可以输出想要的结果。
CNN模型的算法评价
卷积神经网络由于强大的特征学习能力被应用于面部表情识别中,从而极大地提高了面部表情特征提取的效率。与此同时,卷积神经网络相比于传统的面部表情识别方法在数据的预处理和数据格式上得到了很大程度的简化。例如,卷积神经网络不需要输入归一化和格式化的数据。基于以上优点,卷积神经网络在人类面部表情识别这一领域中的表现要远远优于其他传统算法。
模型构建代码
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
import cv2
# 参数初始化
def gaussian_weights_init(m):
classname = m.__class__.__name__
# 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.04)
# 验证模型在验证集上的正确率
def validate(model, dataset, batch_size):
val_loader = data.DataLoader(dataset, batch_size)
result, num = 0.0, 0
for images, labels in val_loader:
pred = model.forward(images)
pred = np.argmax(pred.data.numpy(), axis=1)
labels = labels.data.numpy()
result += np.sum((pred == labels))
num += len(images)
acc = result / num
return acc
# 我们通过继承Dataset类来创建我们自己的数据加载类,命名为FaceDataset
class FaceDataset(data.Dataset):
'''
首先要做的是类的初始化。之前的image-emotion对照表已经创建完毕,
在加载数据时需用到其中的信息。因此在初始化过程中,我们需要完成对image-emotion对照表中数据的读取工作。
通过pandas库读取数据,随后将读取到的数据放入list或numpy中,方便后期索引。
'''
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
self.root = root
df_path = pd.read_csv(root + '\\image_emotion.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '\\image_emotion.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
'''
接着就要重写getitem()函数了,该函数的功能是加载数据。
在前面的初始化部分,我们已经获取了所有图片的地址,在这个函数中,我们就要通过地址来读取数据。
由于是读取图片数据,因此仍然借助opencv库。
需要注意的是,之前可视化数据部分将像素值恢复为人脸图片并保存,得到的是3通道的灰色图(每个通道都完全一样),
而在这里我们只需要用到单通道,因此在图片读取过程中,即使原图本来就是灰色的,但我们还是要加入参数从cv2.COLOR_BGR2GARY,
保证读出来的数据是单通道的。读取出来之后,可以考虑进行一些基本的图像处理操作,
如通过高斯模糊降噪、通过直方图均衡化来增强图像等(经试验证明,在本项目中,直方图均衡化并没有什么卵用,而高斯降噪甚至会降低正确率,可能是因为图片分辨率本来就较低,模糊后基本上什么都看不清了吧)。
读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d() API所接受的数据格式是(batch_size, channel, width, higth),本次图片通道为1,因此我们要将48X48 reshape为1X48X48。
'''
# 读取某幅图片,item为索引号
def __getitem__(self, item):
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 高斯模糊
# face_Gus = cv2.GaussianBlur(face_gray, (3,3), 0)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
# 像素值标准化
face_normalized = face_hist.reshape(1, 48, 48) / 255.0 # 为与pytorch中卷积神经网络API的设计相适配,需reshape原图
# 用于训练的数据需为tensor类型
face_tensor = torch.from_numpy(face_normalized) # 将python中的numpy数据类型转化为pytorch中的tensor数据类型
face_tensor = face_tensor.type('torch.FloatTensor') # 指定为'torch.FloatTensor'型,否则送进模型后会因数据类型不匹配而报错
label = self.label[item]
return face_tensor, label
'''
最后就是重写len()函数获取数据集大小了。
self.path中存储着所有的图片名,获取self.path第一维的大小,即为数据集的大小。
'''
# 获取数据集样本个数
def __len__(self):
return self.path.shape[0]
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# 输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding
# input:(bitch_size, 1, 48, 48), output:(bitch_size, 64, 48, 48), (48-3+2*1)/1+1 = 48
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
# output(bitch_size, 64, 24, 24)
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay):
# 载入数据并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
# 构建模型
model = FaceCNN()
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
# 逐轮训练
for epoch in range(epochs):
# 记录损失值
loss_rate = 0
# scheduler.step() # 学习率衰减
model.train() # 模型训练
for images, emotion in train_loader:
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model.forward(images)
# 误差计算
loss_rate = loss_function(output, emotion)
# 误差的反向传播
loss_rate.backward()
# 更新参数
optimizer.step()
# 打印每轮的损失
print('After {} epochs , the loss_rate is : '.format(epoch+1), loss_rate.item())
if epoch % 5 == 0:
model.eval() # 模型评估
acc_train = validate(model, train_dataset, batch_size)
acc_val = validate(model, val_dataset, batch_size)
print('After {} epochs , the acc_train is : '.format(epoch+1), acc_train)
print('After {} epochs , the acc_val is : '.format(epoch+1), acc_val)
return model
def main():
# 数据集实例化(创建数据集)
train_dataset = FaceDataset(root='face_images/train_set')
val_dataset = FaceDataset(root='face_images/verify_set')
# 超参数可自行指定
model = train(train_dataset, val_dataset, batch_size=128, epochs=100, learning_rate=0.1, wt_decay=0)
# 保存模型
torch.save(model, 'model/model_cnn.pkl')
if __name__ == '__main__':
main()
VGG模型
VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,网络名称VGGNet取自该小组名缩写。VGGNet是首批把图像分类的错误率降低到10%以内模型,同时该网络所采用的3\times33×3卷积核的思想是后来许多模型的基础,该模型发表在2015年国际学习表征会议(International Conference On Learning Representations, ICLR)后至今被引用的次数已经超过1万4千余次。
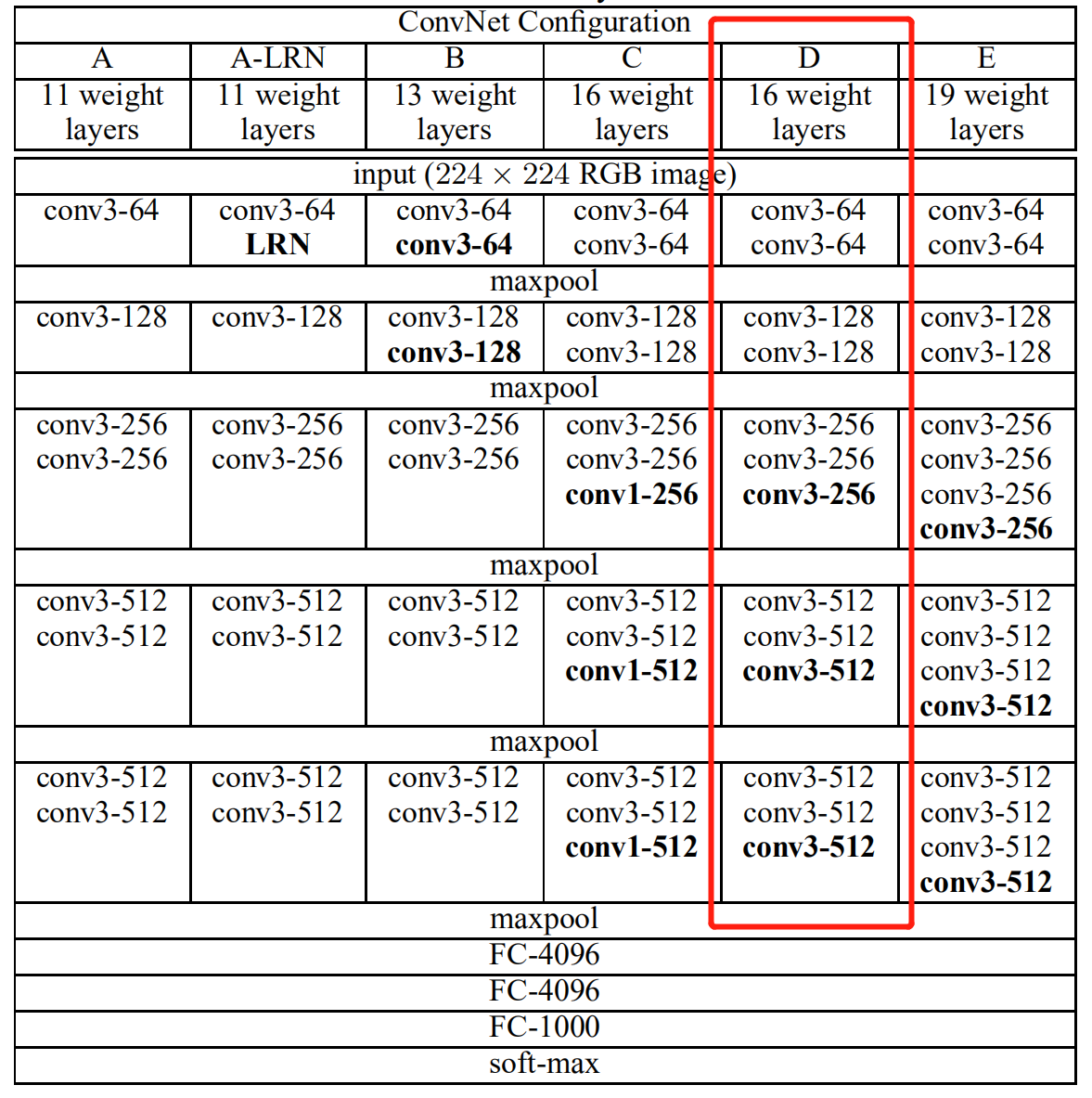
在原论文中的VGGNet包含了6个版本的演进,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数(VGG11-LRN表示在第一层中采用了LRN的VGG11,VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为 1\times11×1 ,相应的VGG16-3表示卷积核尺寸为 3\times33×3 )。下面主要以的VGG16-3为例。
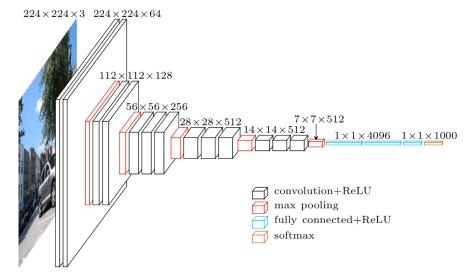
上图中的VGG16体现了VGGNet的核心思路,使用 3\times33×3 的卷积组合代替大尺寸的卷积(2个 3\times33×3 卷积即可与 5\times55×5 卷积拥有相同的感受视野)。
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。那么如果在我感受野相同的条件下,我让中间层数更多,那么能提取到的特征就越丰富,效果就会更好。
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为 3\times33×3 的卷积层后接上一个步幅为2、窗口形状为 2\times22×2 的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。
VGG模型的优点
(1)小卷积核: 将卷积核全部替换为3x3(极少用了1x1),作用就是减少参数,减小计算量。此外采用了更小的卷积核我们就可以使网络的层数加深,就可以加入更多的激活函数,更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,更多的卷积核的使用可使决策函数更加具有辨别能力。其实最重要的还是多个小卷积堆叠在分类精度上比单个大卷积要好。
(2)小池化核: 相比AlexNet的3x3的池化核,VGG全部为2x2的池化核。
(3)层数更深: 从作者给出的6个试验中我们也可以看到,最后两个实验的的层数最深,效果也是最好。
(4)卷积核堆叠的感受野: 作者在VGGnet的试验中只使用了两中卷积核大小:1*1,3*3。并且作者也提出了一种想法:两个3*3的卷积堆叠在一起获得的感受野相当于一个5*5卷积;3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。
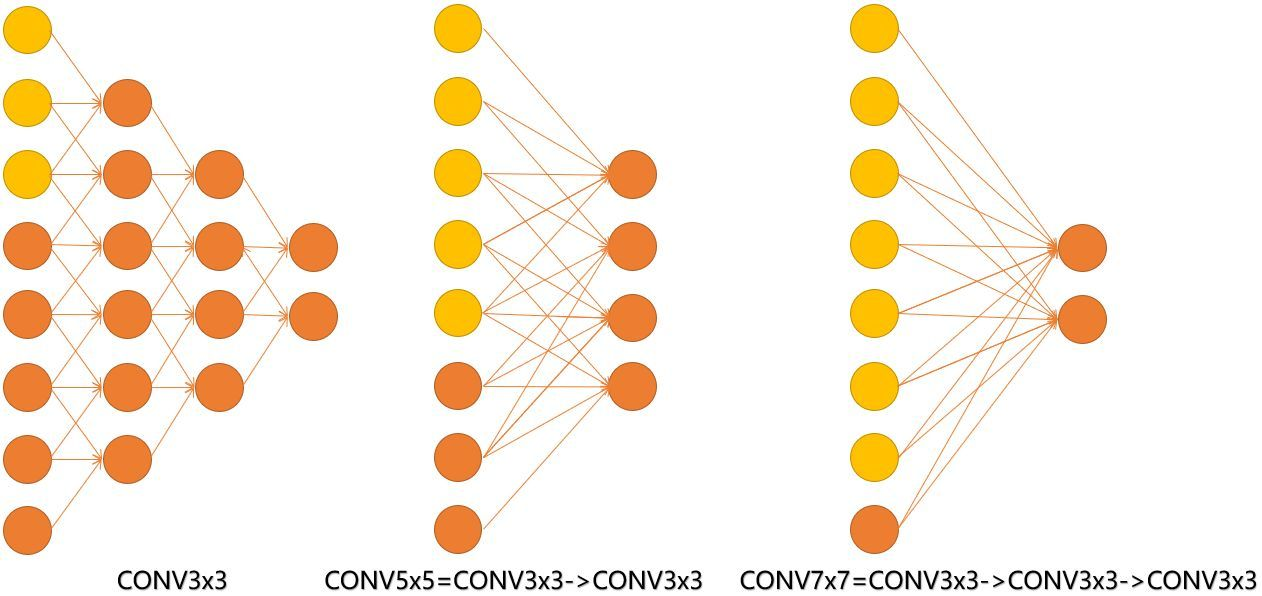
由上图可知,输入的8个神经元可以想象为feature map的宽和高,conv3 、conv5 、conv7 、对应stride=1,pad=0 。从结果我们可以得出上面推断的结论。此外,倒着看网络,也就是 backprop 的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的 conv3x3 中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层 conv3x3 的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
(5)全连接转卷积:VGG另一个特点就是使用了全连接转全卷积,它把网络中原本的三个全连接层依次变为1个conv7x7,2个conv1x1,也就是三个卷积层。改变之后,整个网络由于没有了全连接层,网络中间的 feature map 不会固定,所以网络对任意大小的输入都可以处理。
模型构建代码
class VGG(nn.Module):
def __init__(self, *args):
super(VGG, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((2, 1, 32), (3, 32, 64), (3, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
VGG(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
ResNet模型
class Reshape(nn.Module):
def __init__(self, *args):
super(Reshape, self).__init__()
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
# 残差神经网络
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
resnet = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
resnet.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
resnet.add_module("resnet_block2", resnet_block(64, 128, 2))
resnet.add_module("resnet_block3", resnet_block(128, 256, 2))
resnet.add_module("resnet_block4", resnet_block(256, 512, 2))
resnet.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
resnet.add_module("fc", nn.Sequential(Reshape(), nn.Linear(512, 7)))
模型对比分析:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import pandas as pd
from PIL import Image
import os
import matplotlib.pyplot as plt
from tqdm import tqdm
BATCH_SIZE = 128
LR = 0.01
EPOCH = 60
DEVICE = torch.device('cpu')
path_train = '你选定模型的数据集'
path_vaild = '你选定模型的验证集'
transforms_train = transforms.Compose([
transforms.Grayscale(),#使用ImageFolder默认扩展为三通道,重新变回去就行
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5),#随机调整亮度和对比度
transforms.ToTensor()
])
transforms_vaild = transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
data_train = torchvision.datasets.ImageFolder(root=path_train,transform=transforms_train)
data_vaild = torchvision.datasets.ImageFolder(root=path_vaild,transform=transforms_vaild)
train_set = torch.utils.data.DataLoader(dataset=data_train,batch_size=BATCH_SIZE,shuffle=True)
vaild_set = torch.utils.data.DataLoader(dataset=data_vaild,batch_size=BATCH_SIZE,shuffle=False)
class Reshape(nn.Module):
def __init__(self, *args):
super(Reshape, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
CNN = nn.Sequential(
nn.Conv2d(1,64,3),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(64,256,3),
nn.ReLU(True),
nn.MaxPool2d(3,3),
Reshape(),
nn.Linear(256*7*7,4096),
nn.ReLU(True),
nn.Linear(4096,1024),
nn.ReLU(True),
nn.Linear(1024,7)
)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((2, 1, 32), (3, 32, 64), (3, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
Reshape(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
# 残差神经网络
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
resnet = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
resnet.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
resnet.add_module("resnet_block2", resnet_block(64, 128, 2))
resnet.add_module("resnet_block3", resnet_block(128, 256, 2))
resnet.add_module("resnet_block4", resnet_block(256, 512, 2))
resnet.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
resnet.add_module("fc", nn.Sequential(Reshape(), nn.Linear(512, 7)))
# 用那个模型就切换注释即可
model = CNN
#model = resnet
#model = vgg(conv_arch, fc_features, fc_hidden_units)
model.to(DEVICE)
optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
#optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
print(model)
train_loss = []
train_ac = []
vaild_loss = []
vaild_ac = []
y_pred = []
def train(model,device,dataset,optimizer,epoch):
model.train()
correct = 0
for i,(x,y) in tqdm(enumerate(dataset)):
x , y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
loss = criterion(output,y)
loss.backward()
optimizer.step()
train_ac.append(correct/len(data_train))
train_loss.append(loss.item())
print("Epoch {} Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(epoch,loss,correct,len(data_train),100*correct/len(data_train)))
def vaild(model,device,dataset):
model.eval()
correct = 0
with torch.no_grad():
for i,(x,y) in tqdm(enumerate(dataset)):
x,y = x.to(device) ,y.to(device)
output = model(x)
loss = criterion(output,y)
pred = output.max(1,keepdim=True)[1]
global y_pred
y_pred += pred.view(pred.size()[0]).cpu().numpy().tolist()
correct += pred.eq(y.view_as(pred)).sum().item()
vaild_ac.append(correct/len(data_vaild))
vaild_loss.append(loss.item())
print("Test Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(loss,correct,len(data_vaild),100.*correct/len(data_vaild)))
def RUN():
for epoch in range(1,EPOCH+1):
'''if epoch==15 :
LR = 0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
if(epoch>30 and epoch%15==0):
LR*=0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
'''
#尝试动态学习率
train(model,device=DEVICE,dataset=train_set,optimizer=optimizer,epoch=epoch)
vaild(model,device=DEVICE,dataset=vaild_set)
torch.save(model,'m0.pth')
RUN()
#vaild(model,device=DEVICE,dataset=vaild_set)
def print_plot(train_plot,vaild_plot,train_text,vaild_text,ac,name):
x= [i for i in range(1,len(train_plot)+1)]
plt.plot(x,train_plot,label=train_text)
plt.plot(x[-1],train_plot[-1],marker='o')
plt.annotate("%.2f%%"%(train_plot[-1]*100) if ac else "%.4f"%(train_plot[-1]),xy=(x[-1],train_plot[-1]))
plt.plot(x,vaild_plot,label=vaild_text)
plt.plot(x[-1],vaild_plot[-1],marker='o')
plt.annotate("%.2f%%"%(vaild_plot[-1]*100) if ac else "%.4f"%(vaild_plot[-1]),xy=(x[-1],vaild_plot[-1]))
plt.legend()
plt.savefig(name)
#print_plot(train_loss,vaild_loss,"train_loss","vaild_loss",False,"loss.jpg")
#print_plot(train_ac,vaild_ac,"train_ac","vaild_ac",True,"ac.jpg")
import seaborn as sns
from sklearn.metrics import confusion_matrix
emotion = ["angry","disgust","fear","happy","sad","surprised","neutral"]
sns.set()
f,ax=plt.subplots()
y_true = [ emotion[i] for _,i in data_vaild]
y_pred = [emotion[i] for i in y_pred]
C2= confusion_matrix(y_true, y_pred, labels=["angry","disgust","fear","happy","sad","surprised","neutral"])#[0, 1, 2,3,4,5,6])
#print(C2) #打印出来看看
sns.heatmap(C2,annot=True ,fmt='.20g',ax=ax) #热力图
ax.set_title('confusion matrix') #标题
ax.set_xlabel('predict') #x轴
ax.set_ylabel('true') #y轴
plt.savefig('matrix.jpg')
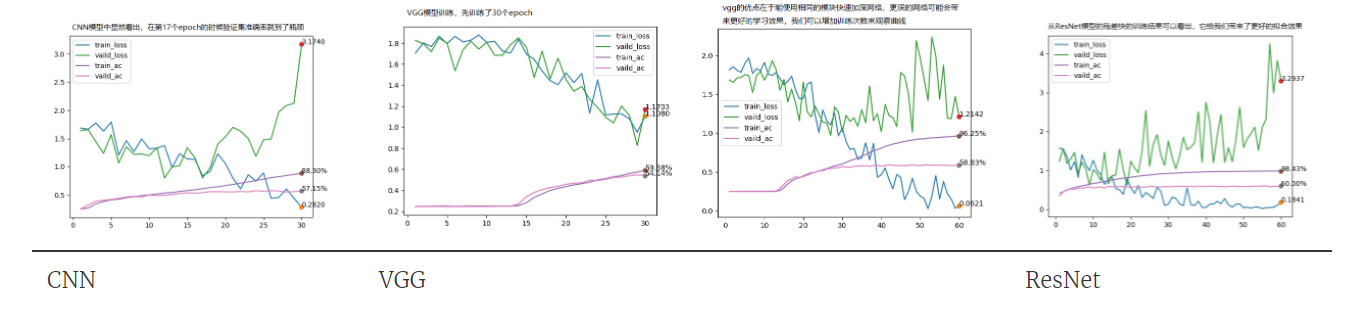
识别效果

完整项目源码获取:
点击下载
1、资源项目源码均已通过严格测试验证,保证能够正常运行;
2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通;
3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于人工智能、计算机科学与技术等相关专业,更为适合;
4、下载使用后,可先查看README.md文件(如有),本项目仅用作交流学习参考,请切勿用于商业用途。
部分内容来源于网络搜集,如有侵权请联系作者删除
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











