







一、重新理解知识工程与知识获取
1、知识工程的诞生
知识工程包括知识库和推理引擎,1977年正式诞生,是以知识为处理对象,研究知识系统的
知识表示、处理和应用的方法和开发工具的学科
缺点是规则明确、边界清晰、应用封闭,一旦涉及到开放事件便难以实现
2、知识获取的瓶颈问题
3、挑战机器自主获取知识的极限
首先在感知层面,机器应具备对事物、对象基本的感知与识别能力
深度学习的贡献就是做到了对事物、对象的正确识别
但仅仅识别是远远不够的,还需要理解其内部的关联关系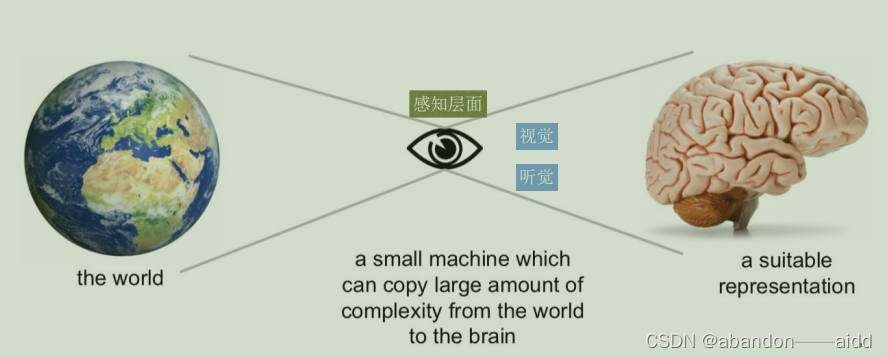
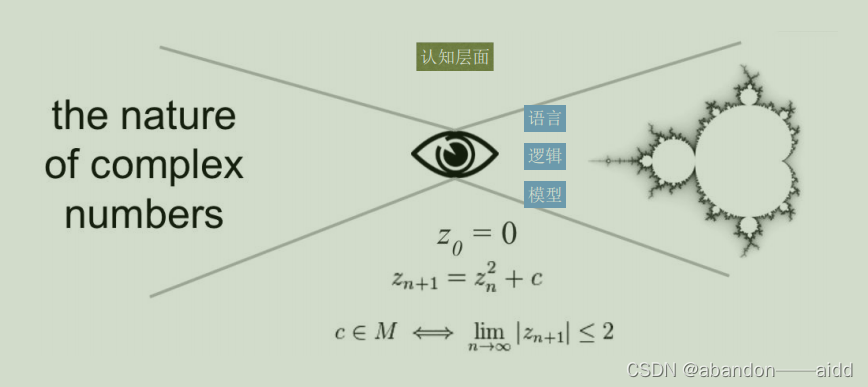
4、从文本获取知识
命名实体识别与分类:完成从文本中识别实体
概念抽取:从语料中发现多个单词组成的相关术语

关系抽取:从句子中抽取实体间的关系
5、小结
二、实体识别与分类
1、实体识别与分类任务定义
定义:从文本中识别实体边界,并进一步判断其类别
2、最简单的实体识别方法:基于模板和规则
例如“***老师”前面代表人名,“***大学”前面代表机构

3、更为常用的实体识别方法:基于序列标注的方法(机器学习)
通过机器学习训练一个分类算法,完成整个句子的序列标注
和大多数机器学习一样,需要设计各种类型的特征,训练分类器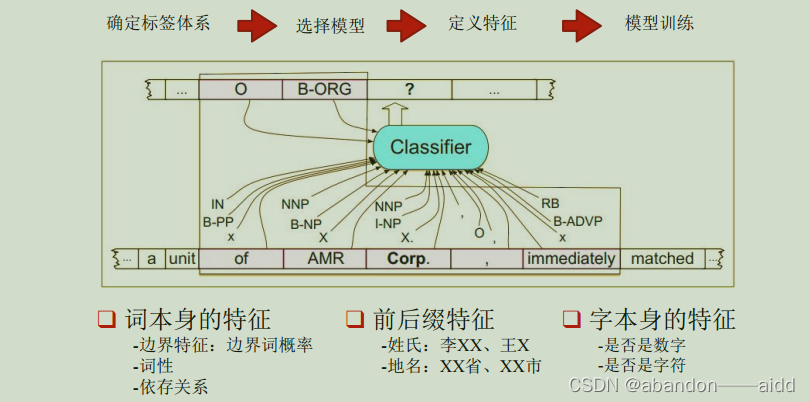
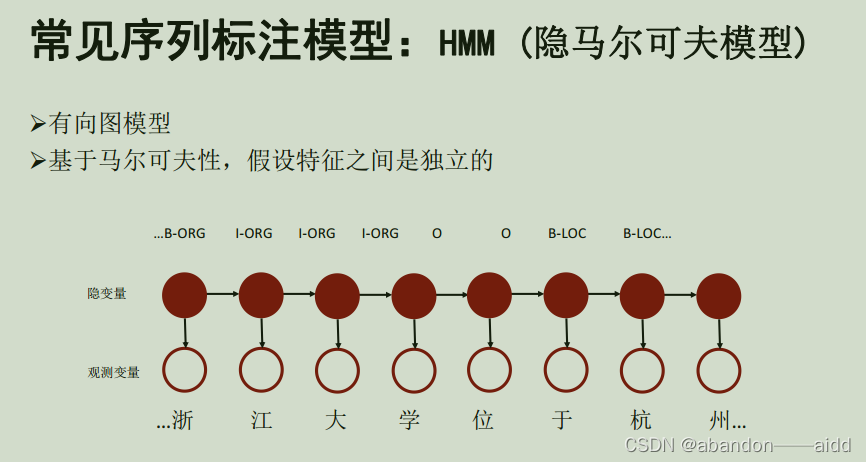
4、基于深度学习的实体识别
可以分为三部分:
a、给定输入的一句话,模型首先通过预训练的词嵌入,将句子表示为词向量
b、卷积神经网络、循环神经网络等表示器学习上下文相关的向量
c、通过条件随机函数softmax等解码器生成序列标记标签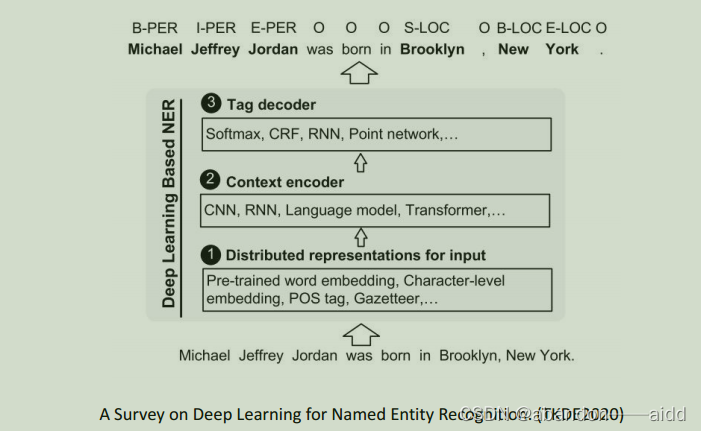
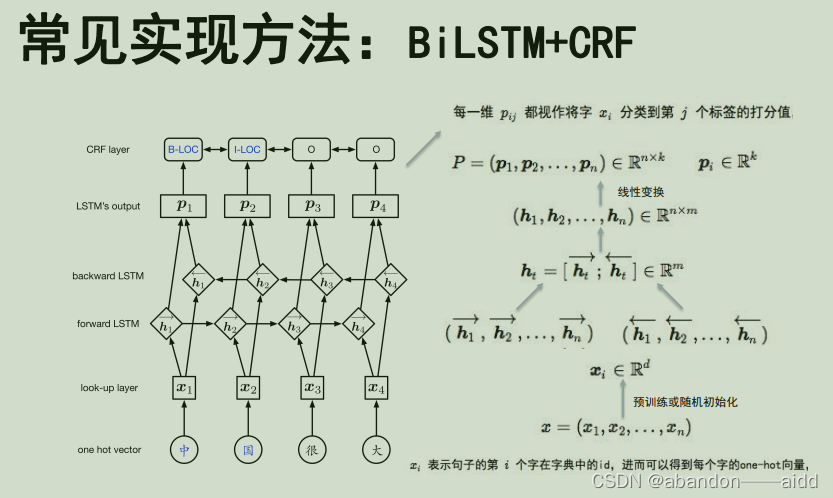
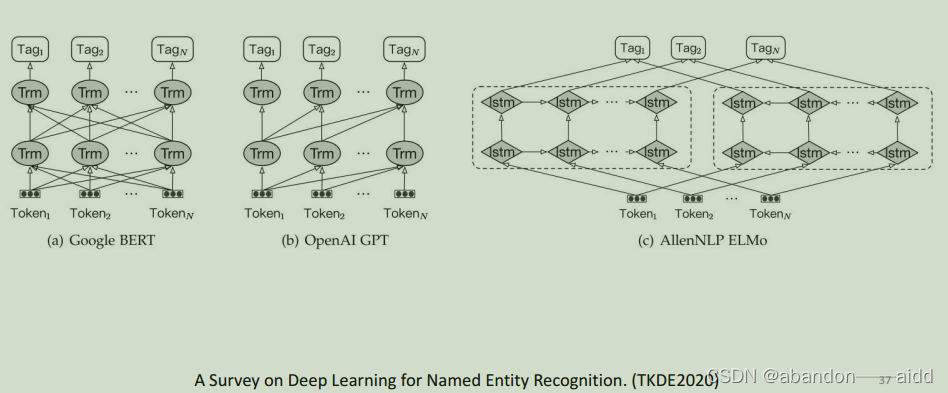
5、基于与训练语言模型的实体识别
6、小结
三、关系抽取与属性补全
1、实体关系抽取的任务定义

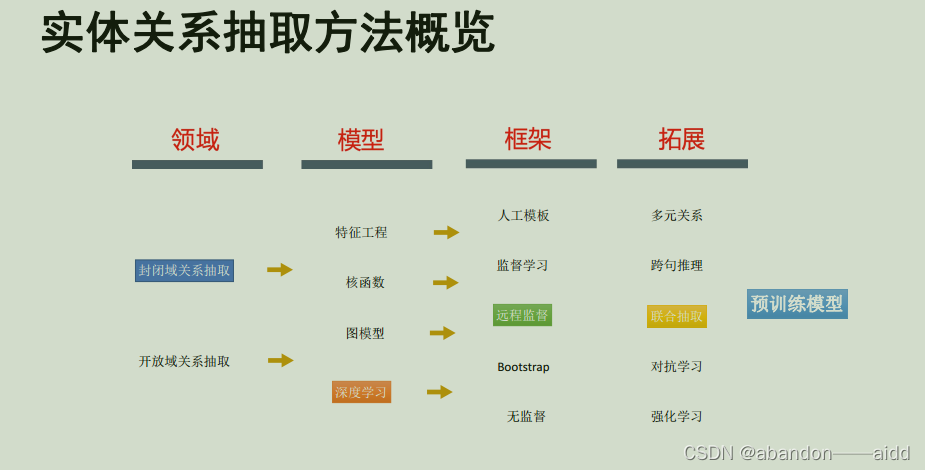
2、基于模板的方法
a、基于触发词匹配的关系抽取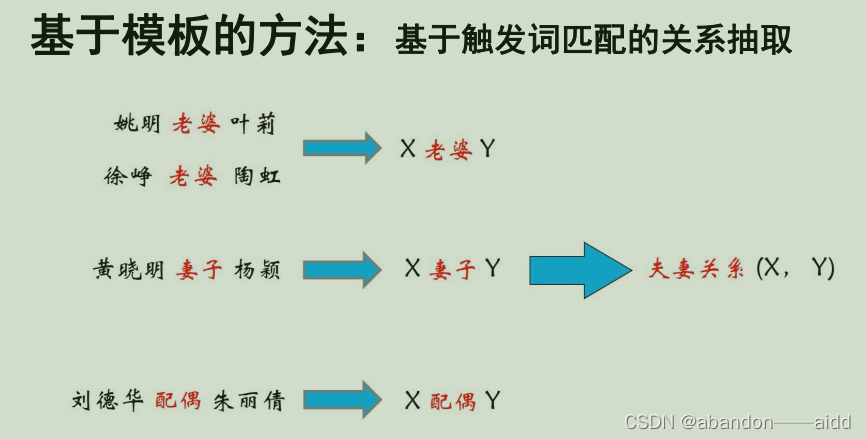
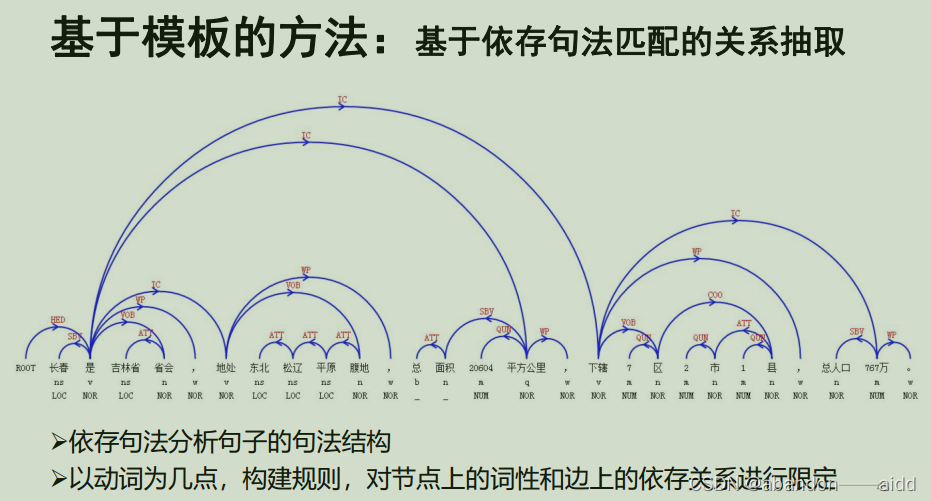
b、基于依存句法匹配的关系抽取

c、优缺点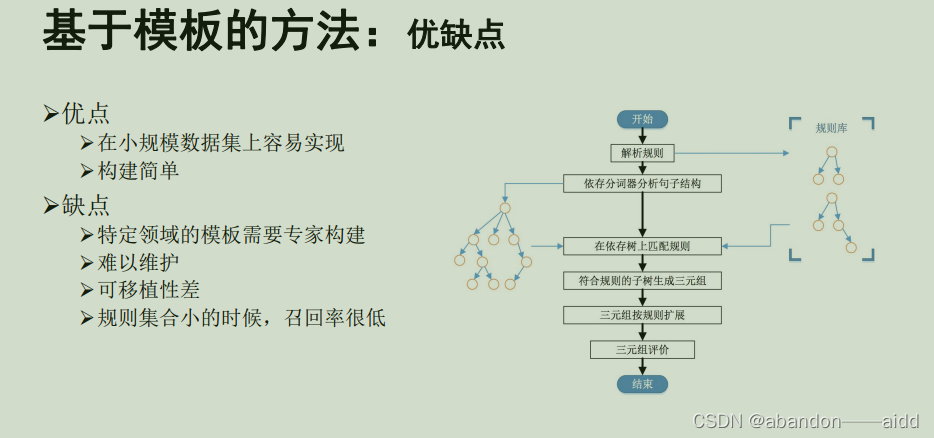
3、基于监督学习的关系抽取
将关系抽取建模为分类问题:首先预定义好所有的关系类别,然后人工标注一些包含这些关系描述的句子,设计特征表示, 选择机器学习模型,利用标注好的数据训练机器学习模型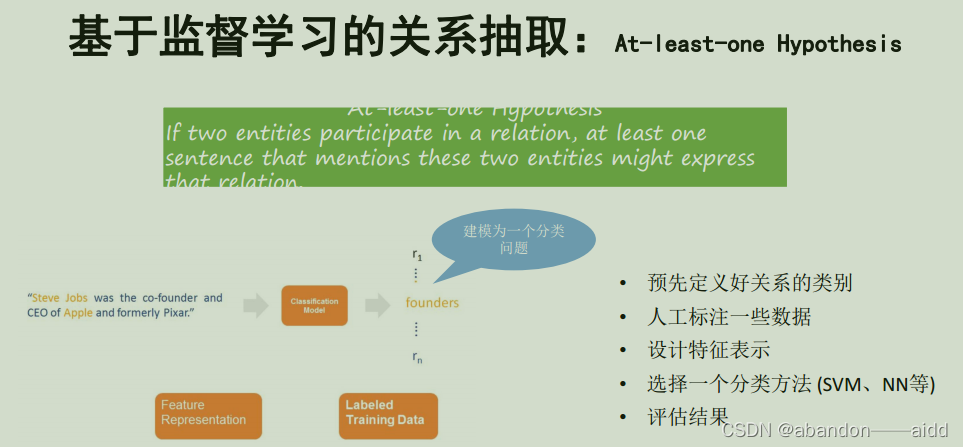
四、属性补全
1、定义
对实体拥有的属性和属性值进行补全
现实世界的任何事物都需要若干属性来描述和修饰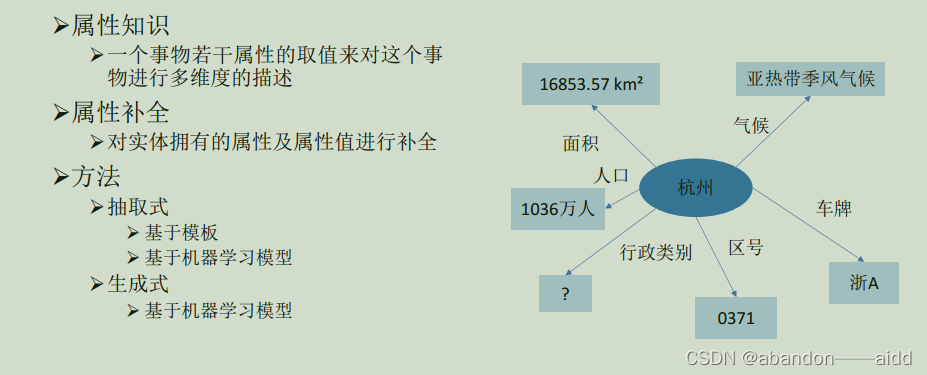
2、抽取式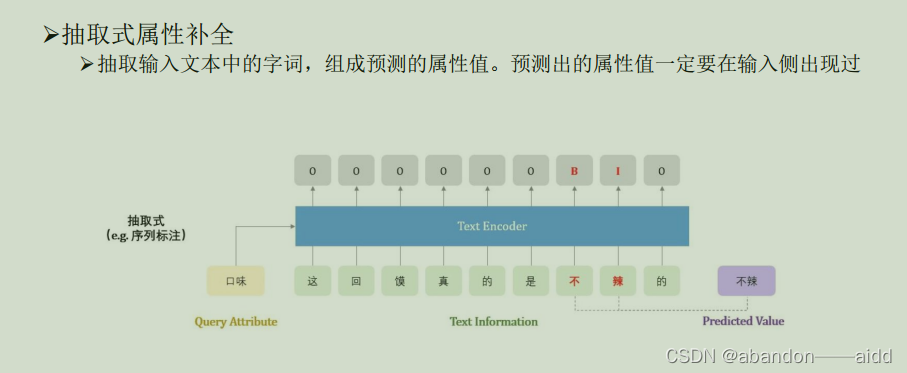
3、生成式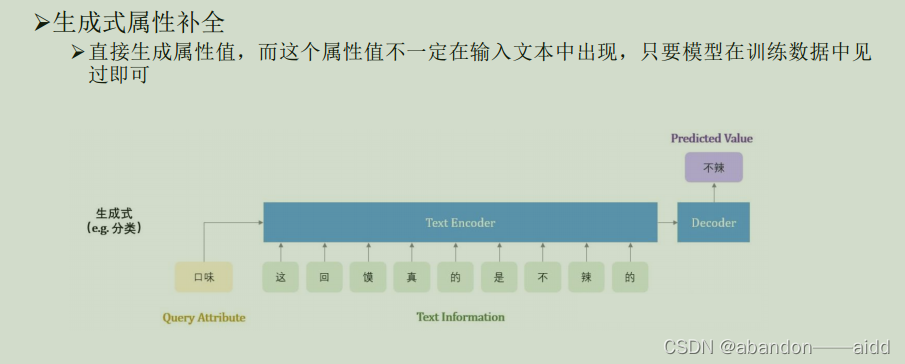
4、小结
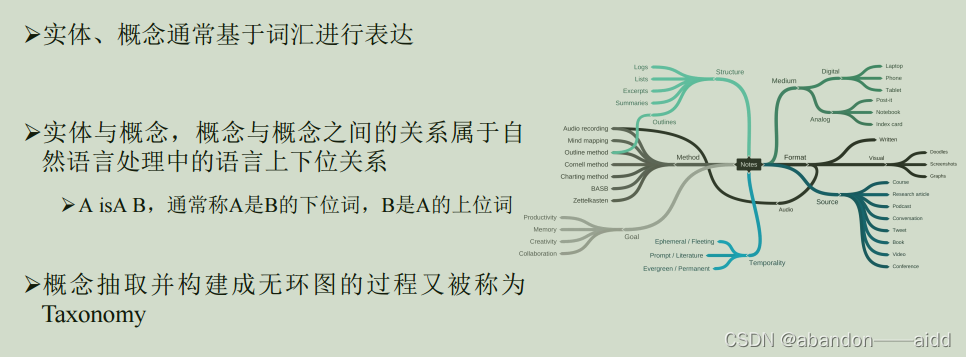
五、概念抽取
1、任务定义
概念是人类在认识过程中把所感知事物的共同本质特点抽象出来加以概括的表达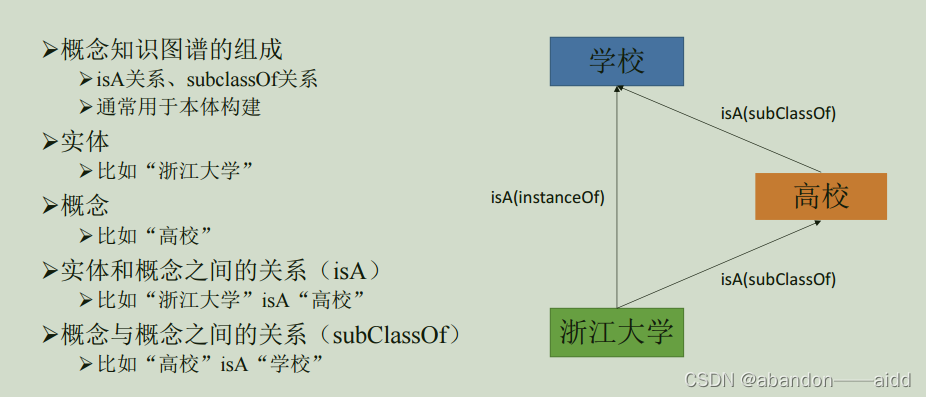

2、基于百科的概念抽取方法
百科中是半结构化概念知识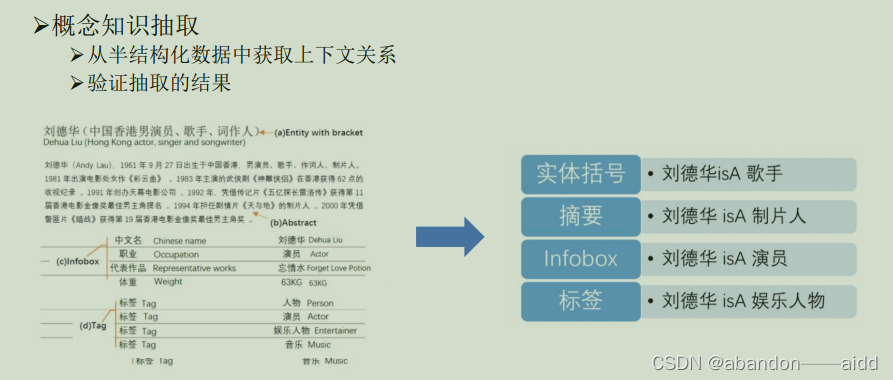
由于互联网中存在大量的噪声,还需要对抽取的知识进行知识验证,知识验证的目标就是判断抽取的知识是否合法
















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









