






1 算法简介
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。经历最近的大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
-
知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
-
幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
-
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。
RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
2 算法原理
完整的RAG应用流程主要包含两个阶段:
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
数据准备阶段:
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。

数据准备
-
数据提取:
-
数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
-
数据处理:包括数据过滤、压缩、格式化等。
-
元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
-
文本分割:
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下: -
句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
-
固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
-
向量化(embedding):
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
3 算法应用
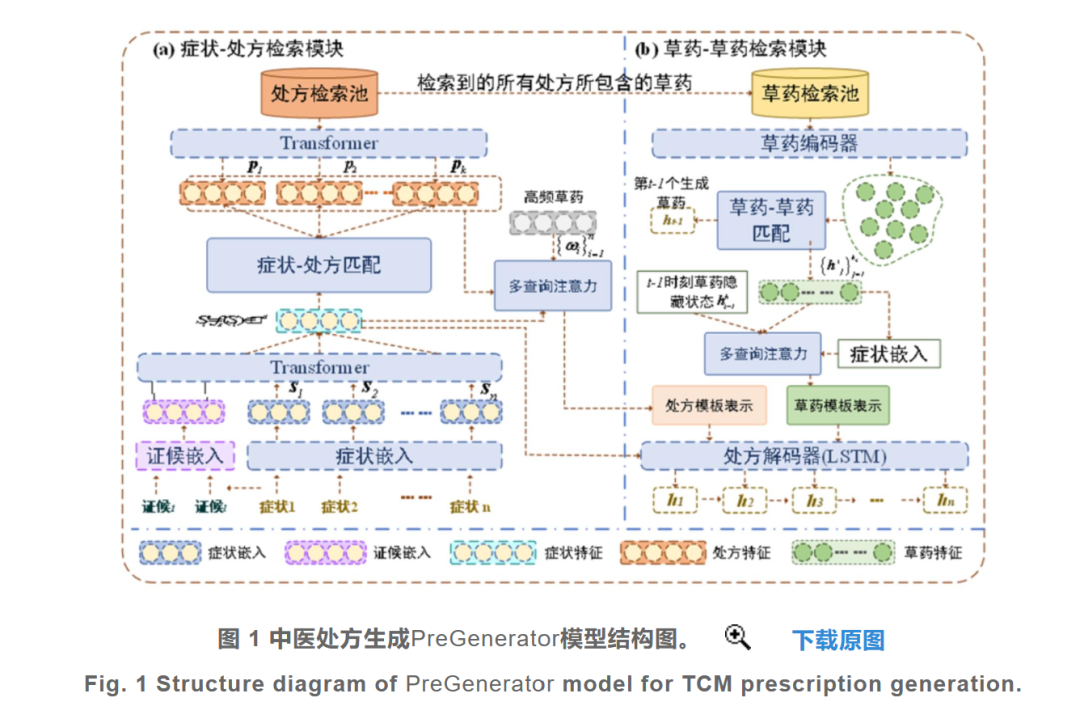
RAG在多个应用领域中都取得了很好的效果,在中医药领域的表现也引人瞩目。例如,在中医处方生成模型的研究中,研究者提出了一个基于检索增强的学习模型来生成中药处方,具体来说,我们使用三个模块来模拟这个过程:症状-处方检索模块、草药-草药检索模块和处方生成模块。首先,利用患者的症状特征结合证候推理作为查询,利用症状-处方检索模块,从经方检索池中检索最相关处方,生成处方级特征模板,学习中医方剂中的语言特征。同时,研究者设计了一种全新的多查询注意力机制来学习处方级模板表示。
其次,为了使生成的处方更加符合中医方剂配伍规则,研究者提出了草药-草药检索模块,该模块旨在通过分析检索处方中的草药间相关性来学习下一个草药生成所需的草药级模板。最后,利用处方解码器,结合症状特征、处方级和草药级模板特征表示生成更加严谨的处方。与此同时,采用覆盖机制能够保证生成不重复的草药,设计的两级记忆检索机制有助于生成准确、多样的中医处方。
4 小结
对于中医来说,保存医学知识、实验结果、医学分析结果和临床病历最广泛采用的形式是文字。利用这些文献资源是一项具有挑战性的任务,这对于在医学文献资源中应用AI模型非常重要。
AI模型催生的技术很多,每一个环节,要真正做好符合实际应用,都需要我们仔细研究很长一段时间,并需要不断去实践,才能打磨出精品。
**参考文献:
**
[1]赵紫娟,任雪婷,宋恺等.基于检索增强的中医处方生成模型[J/OL].太原理工大学学报:1-19[2024-03-21].http://kns.cnki.net/kcms/detail/14.1220.N.20230714.1922.002.html.
[2]知乎专栏. 《大模型主流应用RAG的介绍——从架构到技术细节》. 见于 2024年3月21日. https://zhuanlan.zhihu.com/p/676982074**.**
[3]知乎专栏. 《一文搞懂大模型RAG应用(附实践案例)》. 见于 2024年3月20日. https://zhuanlan.zhihu.com/p/668082024**.**
推荐阅读:
**本体–高效的知识建模工具
**

古今医案云平台
提供50余万古今医案检索服务
支持手工、语音、OCR、批量医案结构化录入
设计九大分析模块,贴近临床实际需求
支持平台海量医案与个人医案协同分析
**EDC中医科研病例采集系统
**
支持多中心、线上随机分组、数据录入
SDV、稽查轨迹、短信提醒、数据统计
**分析等功能
**
支持定制化表单设计
**用户可以登录网址:https://www.yiankb.com/edc
**
免费体验!

AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/Javachichi/article/details/140963725?spm=1001.2014.3001.5502,如有侵权,请联系删除。















 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









