







目录
5、分析综合(Run Synthesis)(针对tb代码,有时候也会跳过tb代码的分析综合)
6、功能仿真(Run Behavioral Simulation)
7、布局布线(Run Implementation)(使用中经常省略跳过)
8、时序仿真(Run Post-Implementation Timing Simulation)(使用中经常省略跳过)
11、下载(Open Target / Auto Connect)
----------------------------------------------------分--------------割-------------线--------------------------------------------------------------------
1、建立工程
(1)双击软件Vivado 2018.3,启动软件;

(2)选择Create Project,创建工程;

(3)在New Project界面,选next项,并给工程命名为decoder_3_8,选择工程存储路径(最好是不包含中文字符的路径),并勾选创建工程子目录选项;
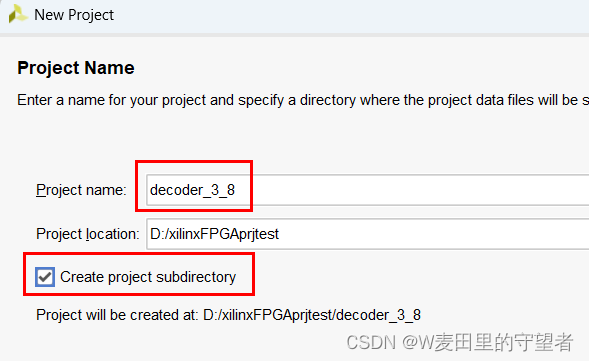
(4)选则RTL Project项;

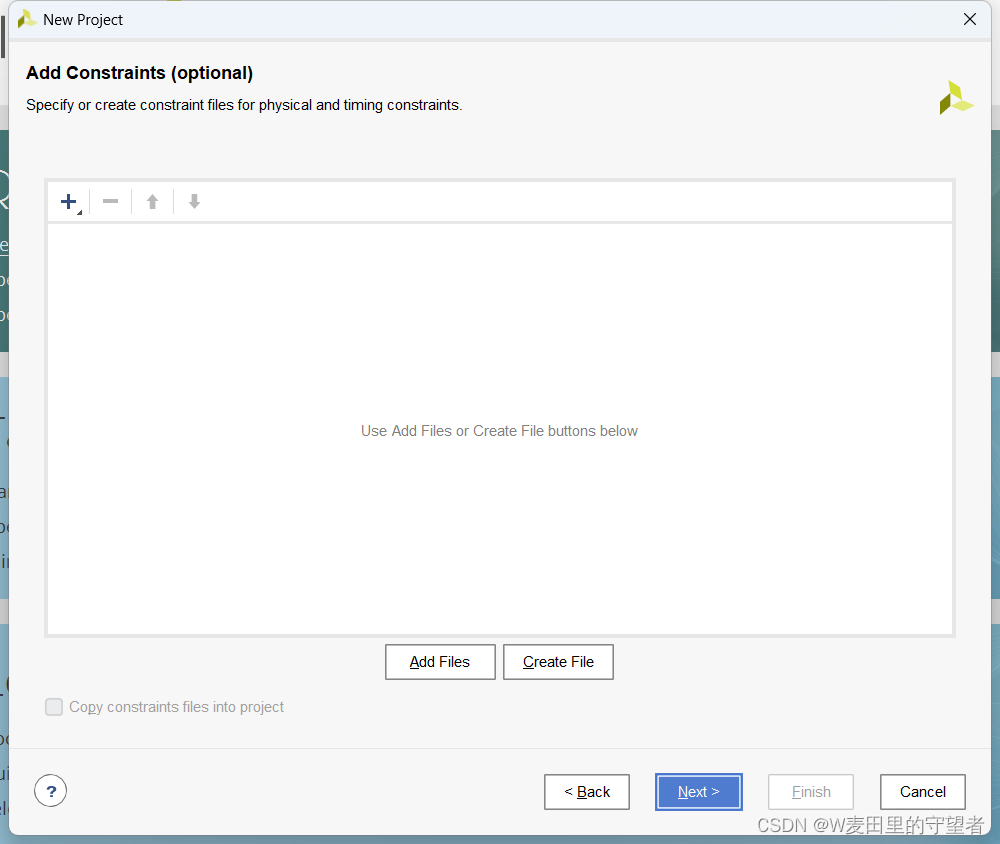
(5)在Add Sources和Add Constraints(optional)界面不做操作,直接next跳过;

(6)选择芯片为XC7A35TFGG,按照图示搜索芯片并选择;

(7)选择Finish,完成工程创建;
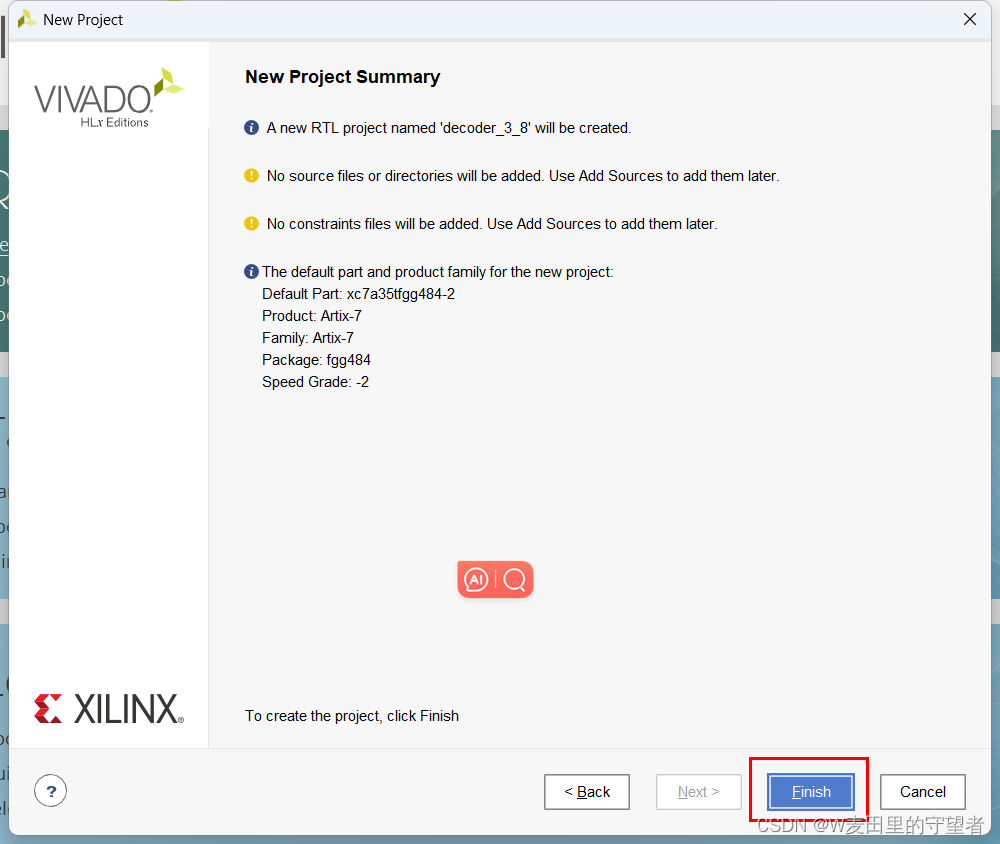
(8)工程建立完毕。
2、编写Verilog代码
(1)新建.v文件,在图示位置选择(两个功能一样,任选其一);
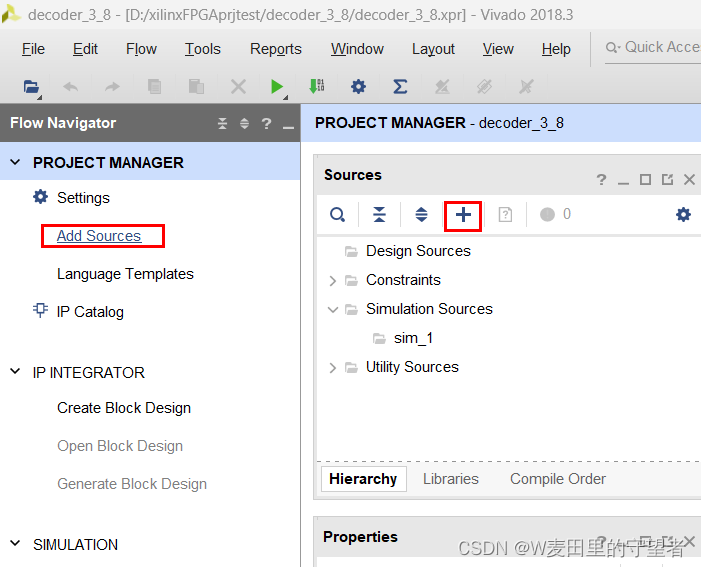
(2)选择Add or create design sources项;
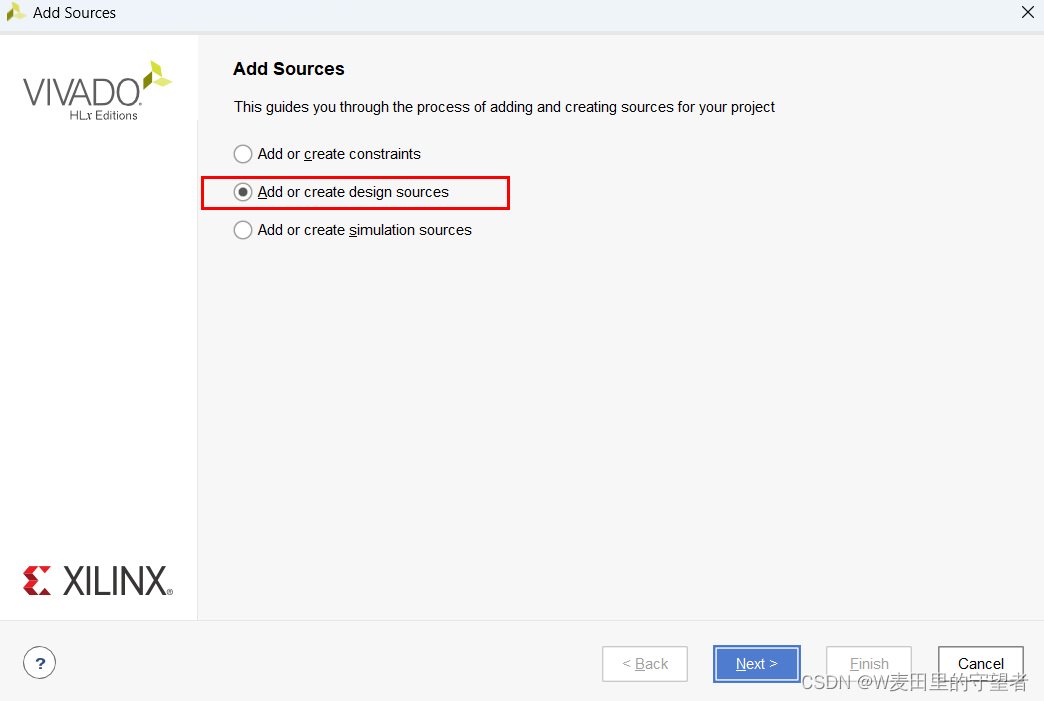
(3)选择Create File项;
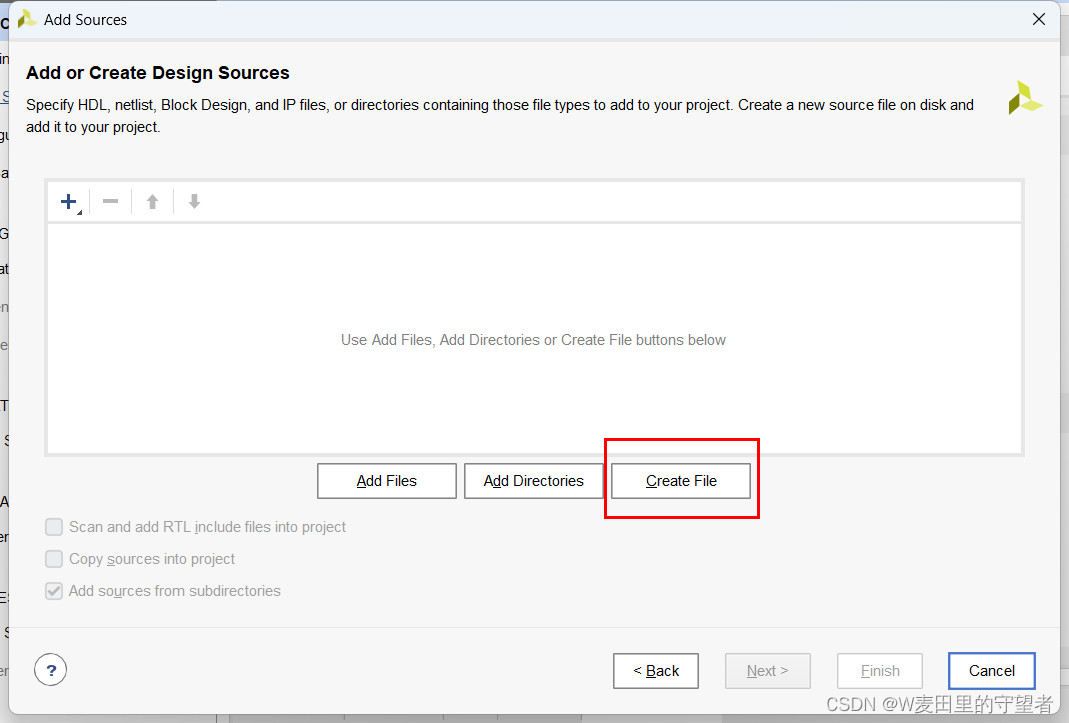
(4)给Verilog文件起名decoder_3_8;
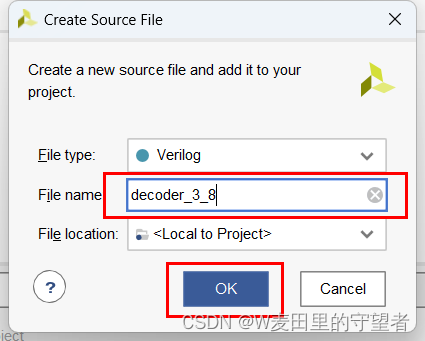
(5)选择Finish完成项;
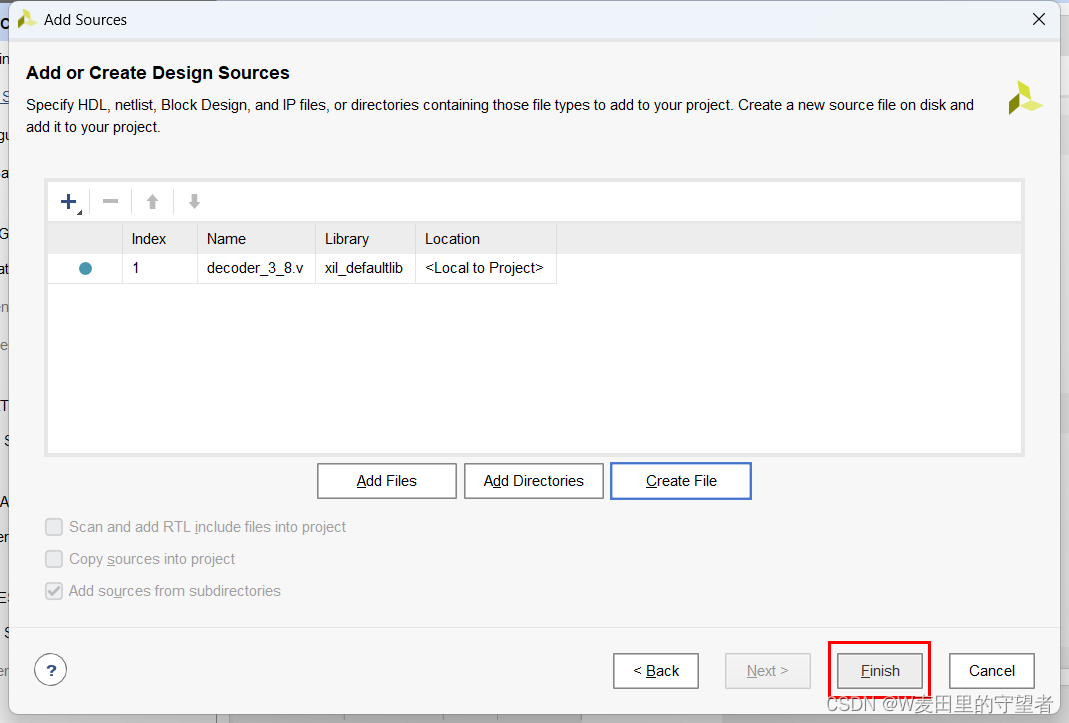
(6)在弹出的Define Module对话框不做操作,选择OK;
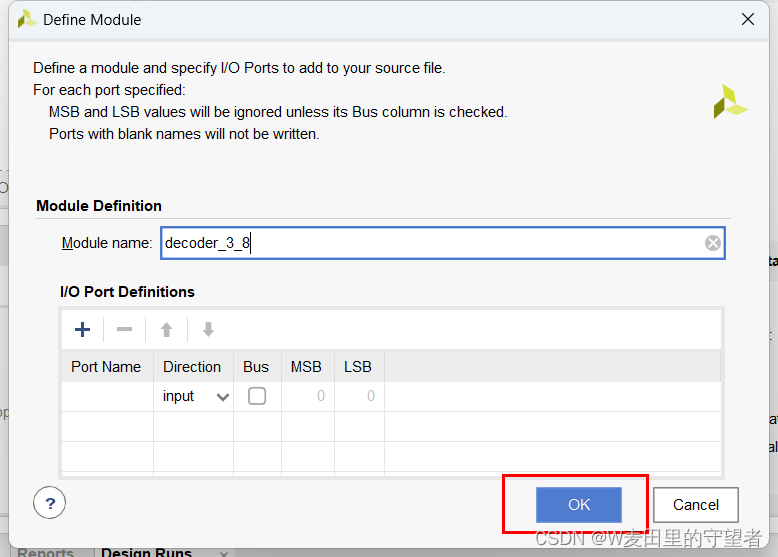
(7)至此,完成了.v文件的创建;
(8)双击decoder_3_8文件,编写Verilog代码;
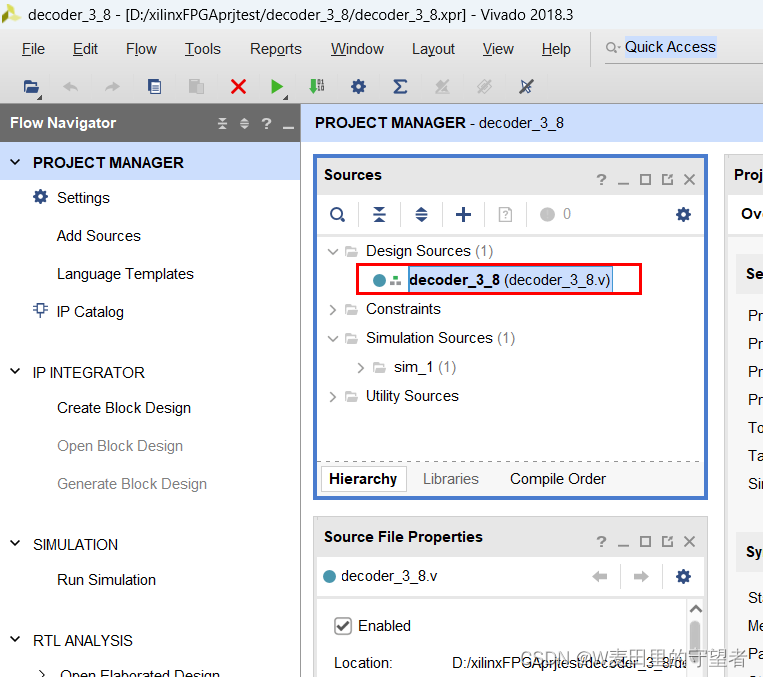
(9)删掉内部系统自动填写的代码,写入我们自己的代码,并随时按ctrl+S保存代码数据;
module decoder_3_8(
a,
b,
c,
out
);
input a;//输入端口A
input b;//输入端口B
input c;//输入端口C
output reg[7:0] out;//输出端口
//以Always块描述的信号赋值,被赋值对象必须定义为reg类型
//{a,b, c}变成了一个三位的信号,这种操作叫做位拼接
always@(a,b,c)begin
case({a,b,c})
3'b000:out = 8'b0000_0001;
3'b001:out = 8'b0000_0010;
3'b010:out = 8'b0000_0100;
3'b011:out = 8'b0000_1000;
3'b100:out = 8'b0001_0000;
3'b101:out = 8'b0010_0000;
3'b110:out = 8'b0100_0000;
3'b111:out = 8'b1000_0000;
endcase
end
endmodule3、分析综合(Run Synthesis)
(1)检查语法和逻辑有没有错误,选择Run Synthesis按钮,在弹出的Launch Runs对话框选OK;
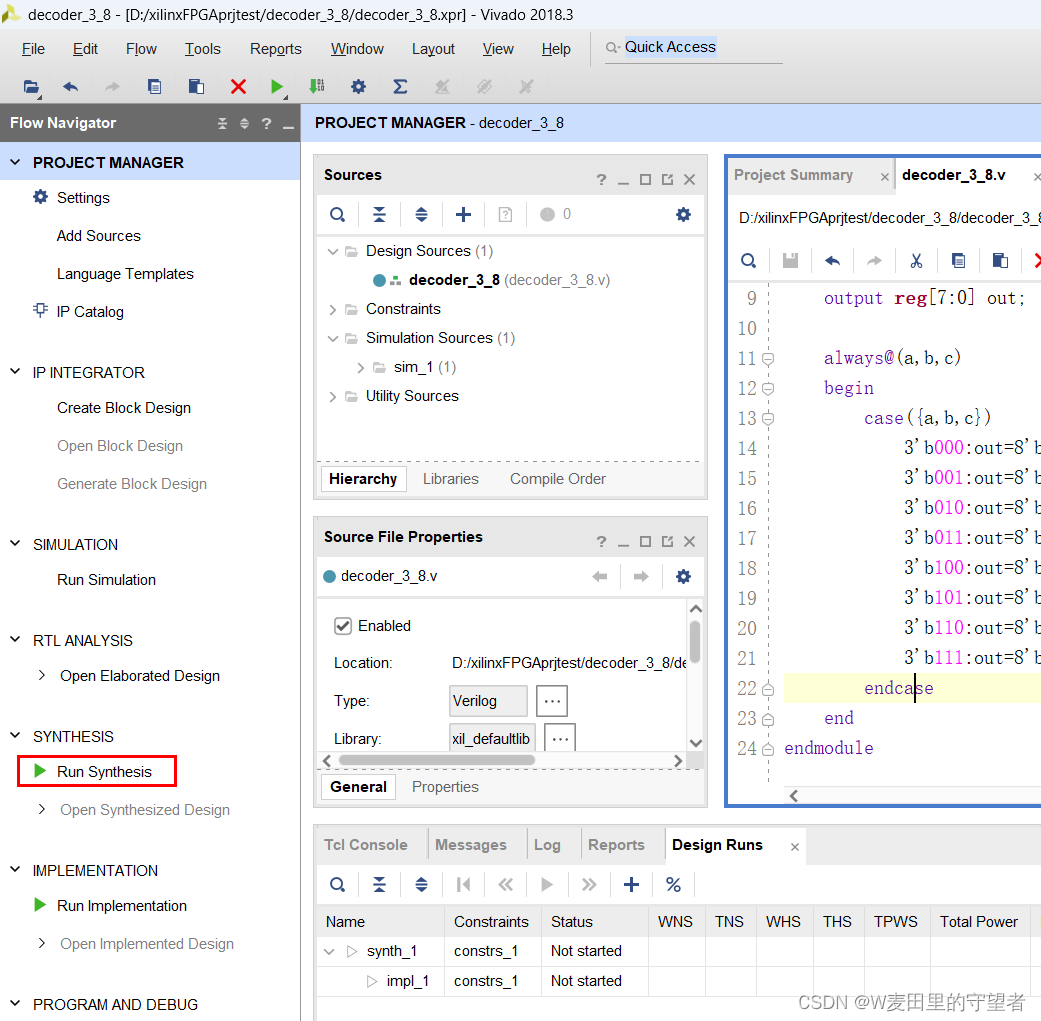
(2)可从软件右上角看到综合过程进行中;

(3)可选择上图的按钮(),查看更加详细的综合过程;
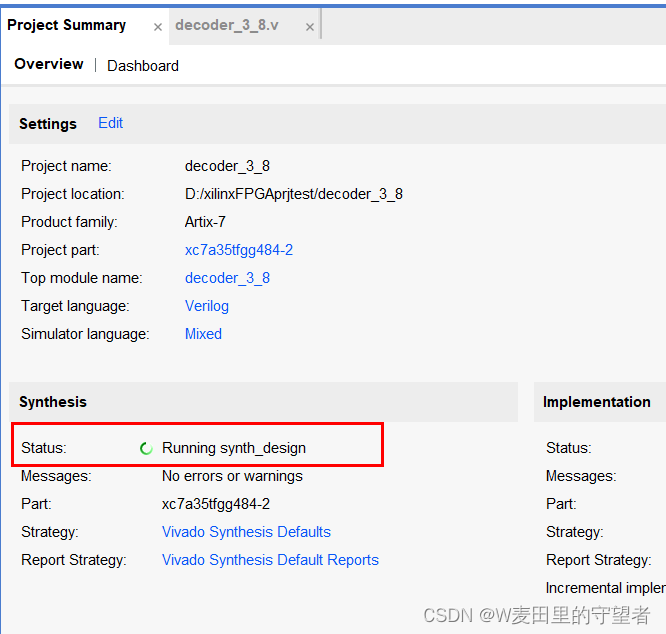
(4)综合结束后,可选择View Reports选项查看报告;
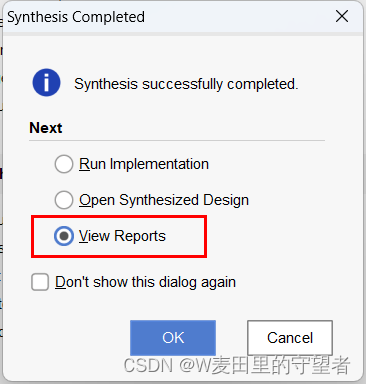
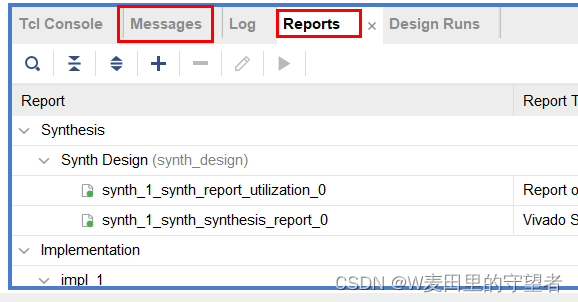
(5)Reports和Messages显示没有报错,表示可以继续,有报错要修改;
4、编写test bench代码
(1)建立tb文件
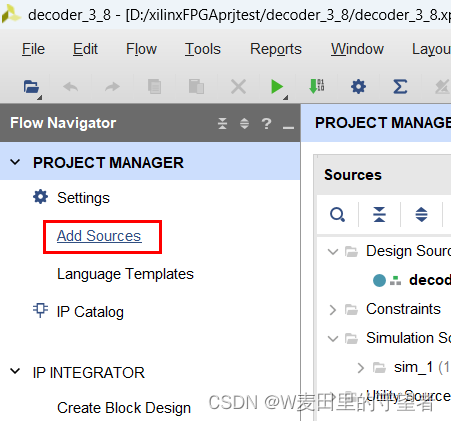
(2)选择Add or create simulation sources项目;
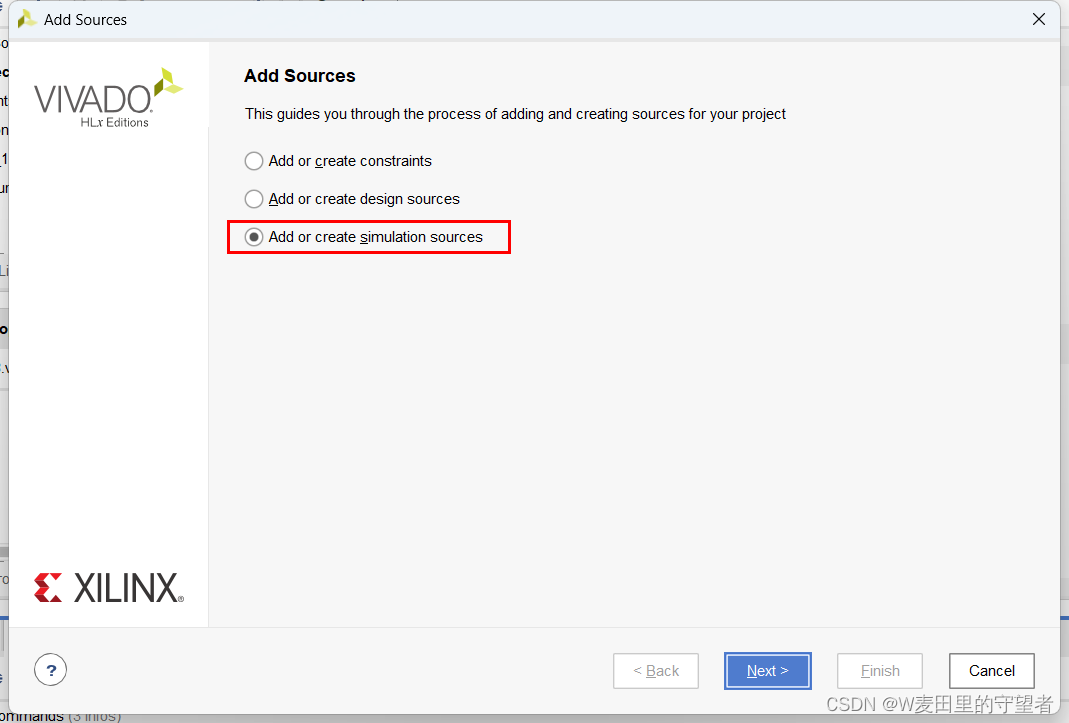
(3)选择Create File项;
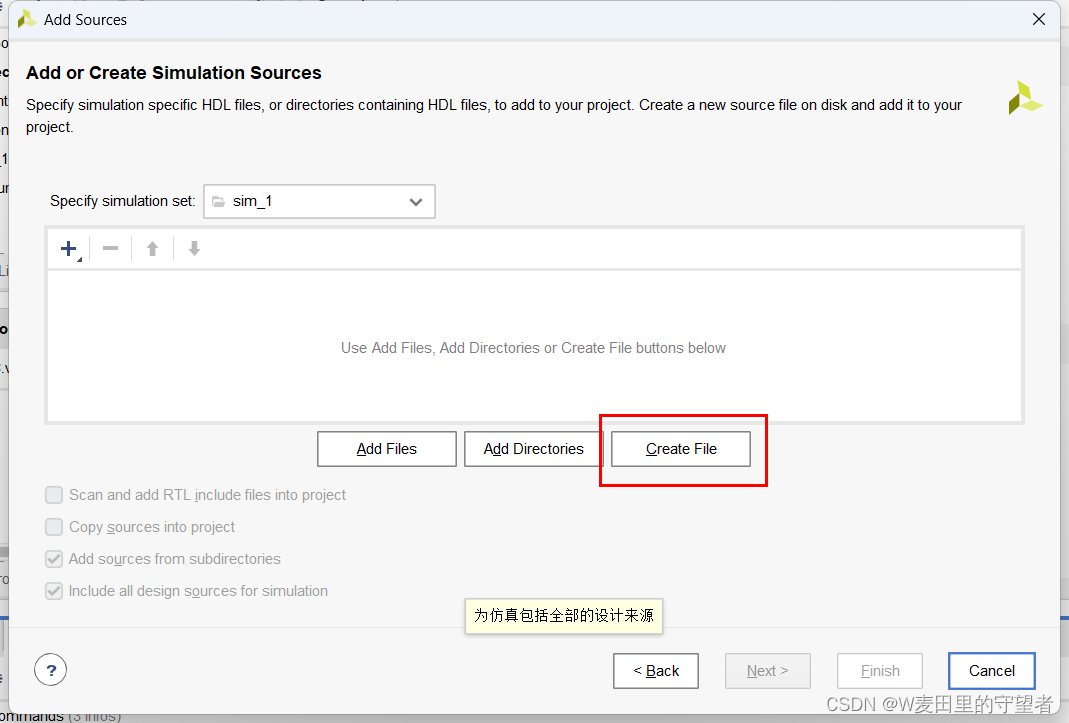
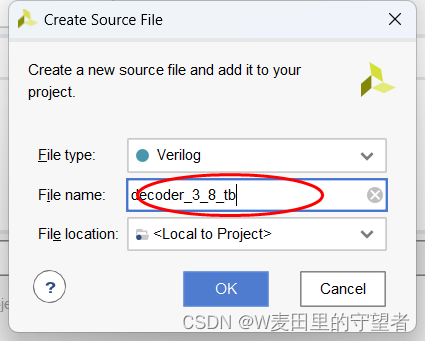
(4)给tb文件起名,一般格式为项目名_tb;
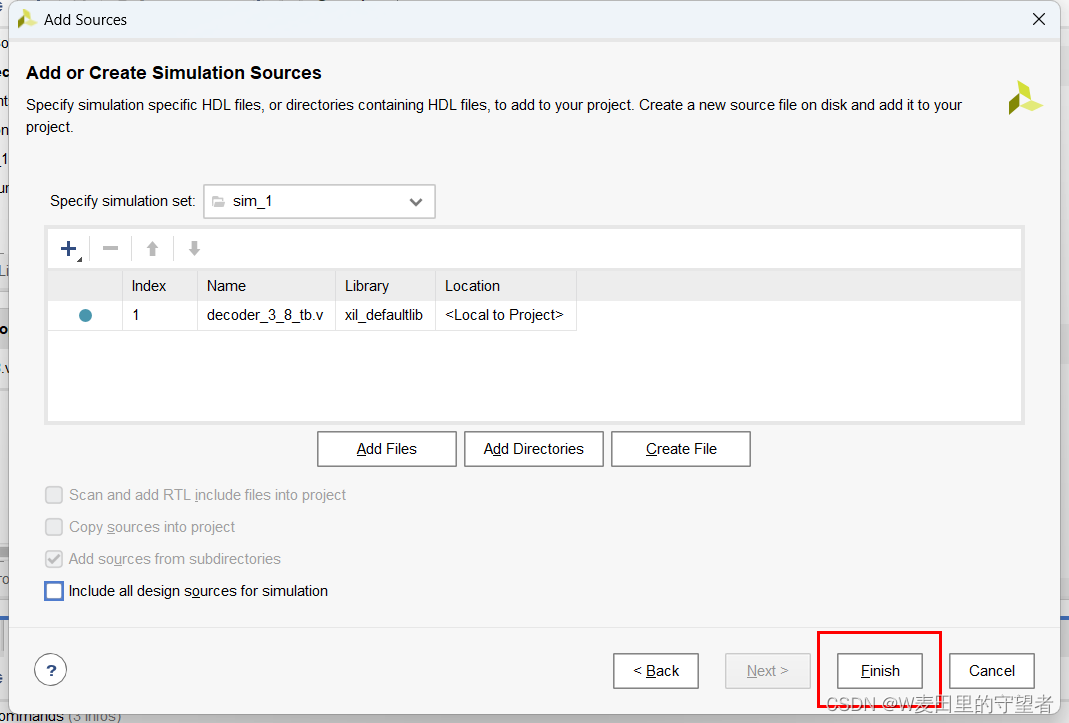
(5)选择Finish项;
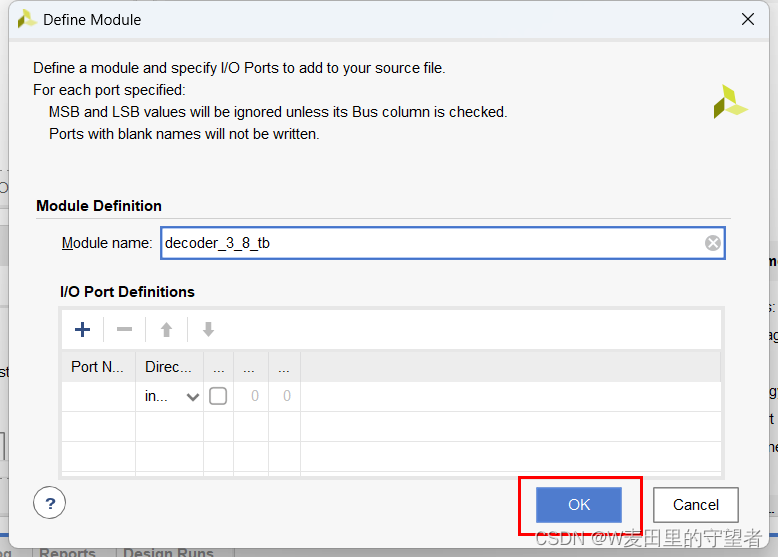
(6)在Define Module界面,不做操作,选择OK;
(7)至此,完成了tb文件的创建;
(8)双击打开tb文件,写入tb代码;
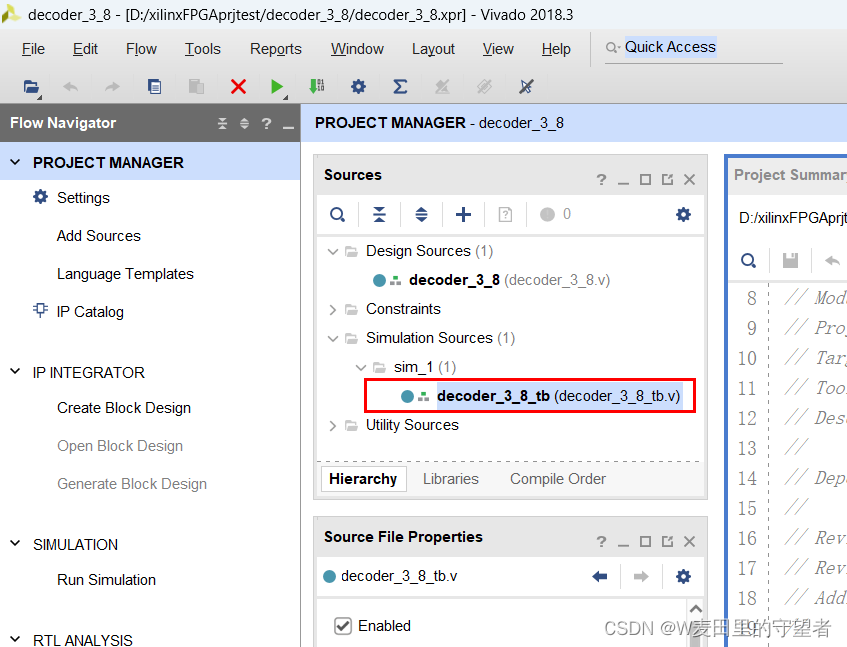
(9)删掉内部系统自动填写的tb代码,写入我们自己的tb代码,并随时按ctrl+S保存代码数据;
`timescale 1ns/1ns
module decoder_3_8_tb();
reg s_a;
reg s_b;
reg c;
wire [7:0] out;
decoder_3_8 decoder_3_8_inst0(
.a(s_a),
.b(s_b),
.c(c),
.out(out)
);
initial begin
s_a=0;s_b=0;c=0;
#200;
s_a=0;s_b=0;c=1;
#200;
s_a=0;s_b=1;c=0;
#200;
s_a=0;s_b=1;c=1;
#200;
s_a=1;s_b=0;c=0;
#200;
s_a=1;s_b=0;c=1;
#200;
s_a=1;s_b=1;c=0;
#200;
s_a=1;s_b=1;c=1;
#200;
$stop;
end
endmodule5、分析综合(Run Synthesis)(针对tb代码,有时候也会跳过tb代码的分析综合)
(1)检查语法和逻辑有没有错误,选择Run Synthesis按钮,在弹出的Launch Runs对话框选OK;
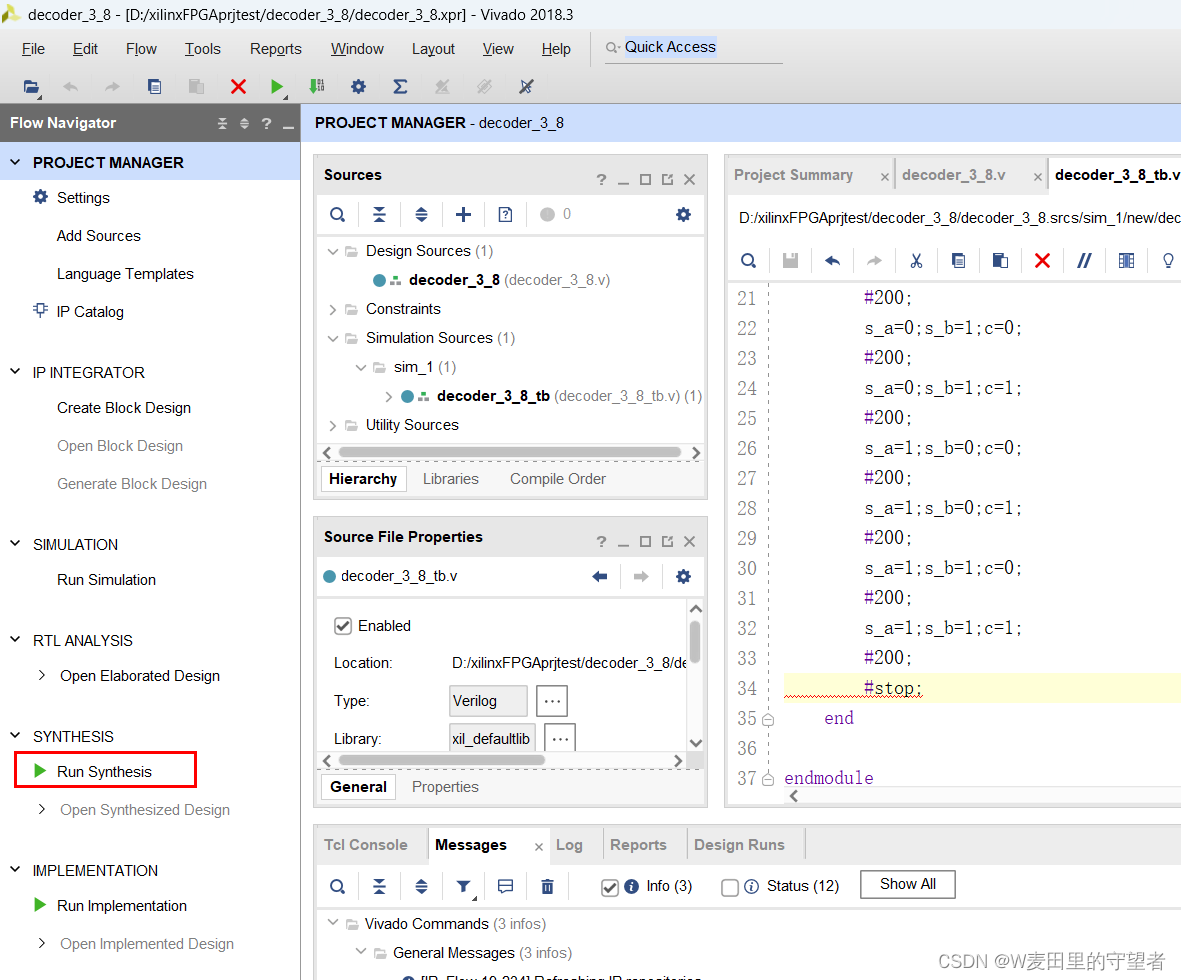
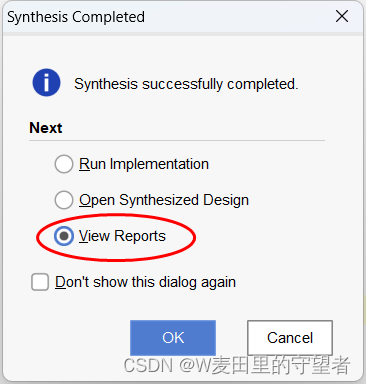
(2)综合结束后,可选择View Reports选项查看报告,便于修改错误;
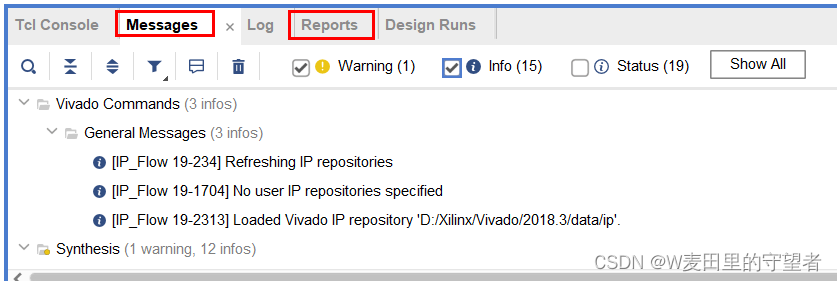
(3)Reports和Messages显示没有报错,表示可以继续,有报错要修改;
6、功能仿真(Run Behavioral Simulation)
(1)选择Run Behavioral Simulation项;
(2)出现结果,并按图示按钮,调整显示的样子;
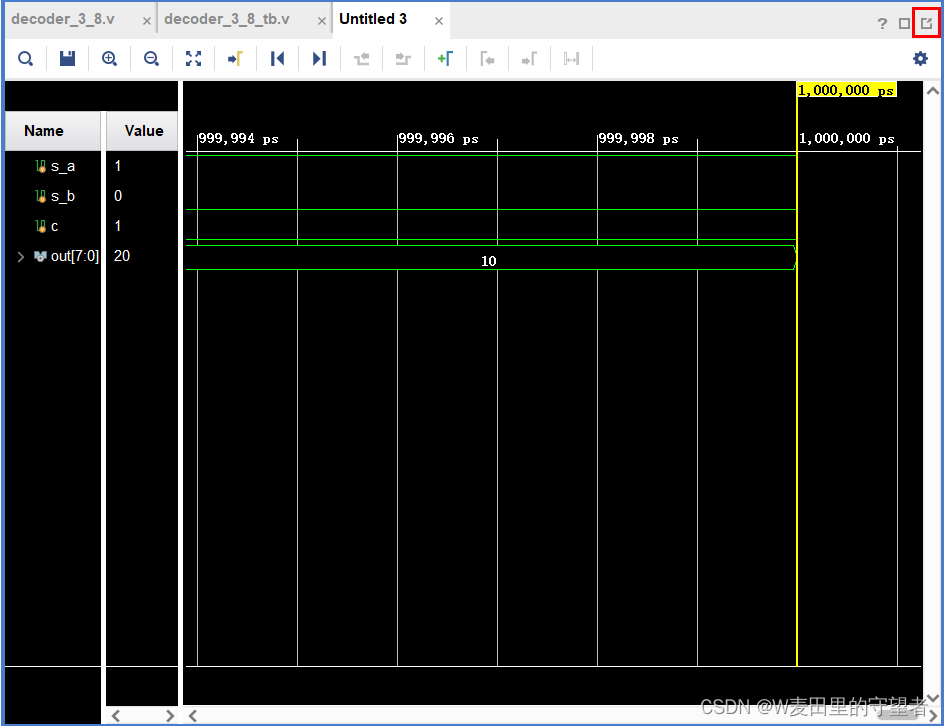
(3)选zoom fit按钮,显示全部;
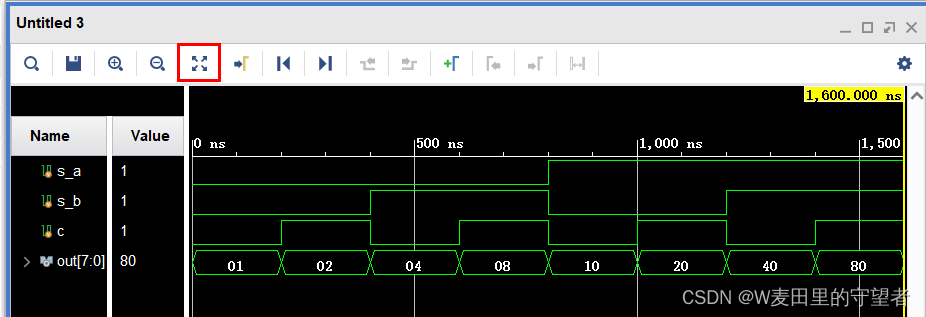
(4)系统默认跑1000ns,如果显示不全,可在vivado主界面,按三角按钮,在次仿真运行,跑出来全部仿真;
(5)查看波形,是否与功能相符;
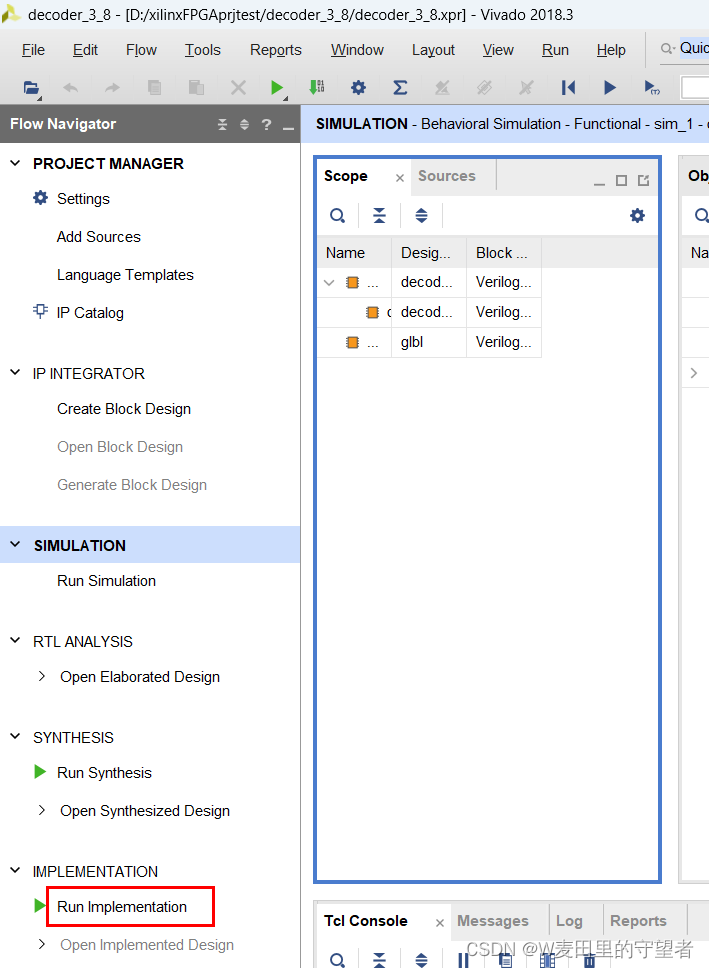
7、布局布线(Run Implementation)(使用中经常省略跳过)
(1)选择Run Implementation项,软件右上角可以看到正在进行中;
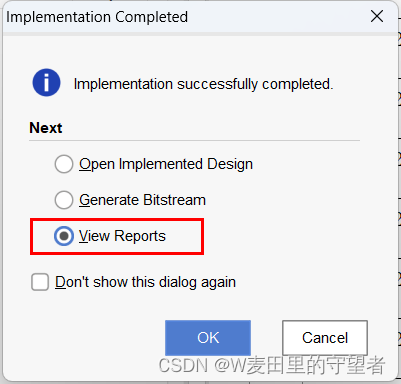
(2)完成后,可以选择View Reports查看报告;
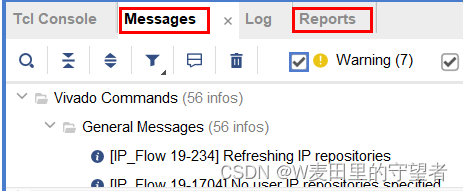
(3)在Messages和Reports中可以查看错误,并从对应位置修改;
8、时序仿真(Run Post-Implementation Timing Simulation)(使用中经常省略跳过)
(1)选择Run Post-Implementation Timing Simulation按钮;
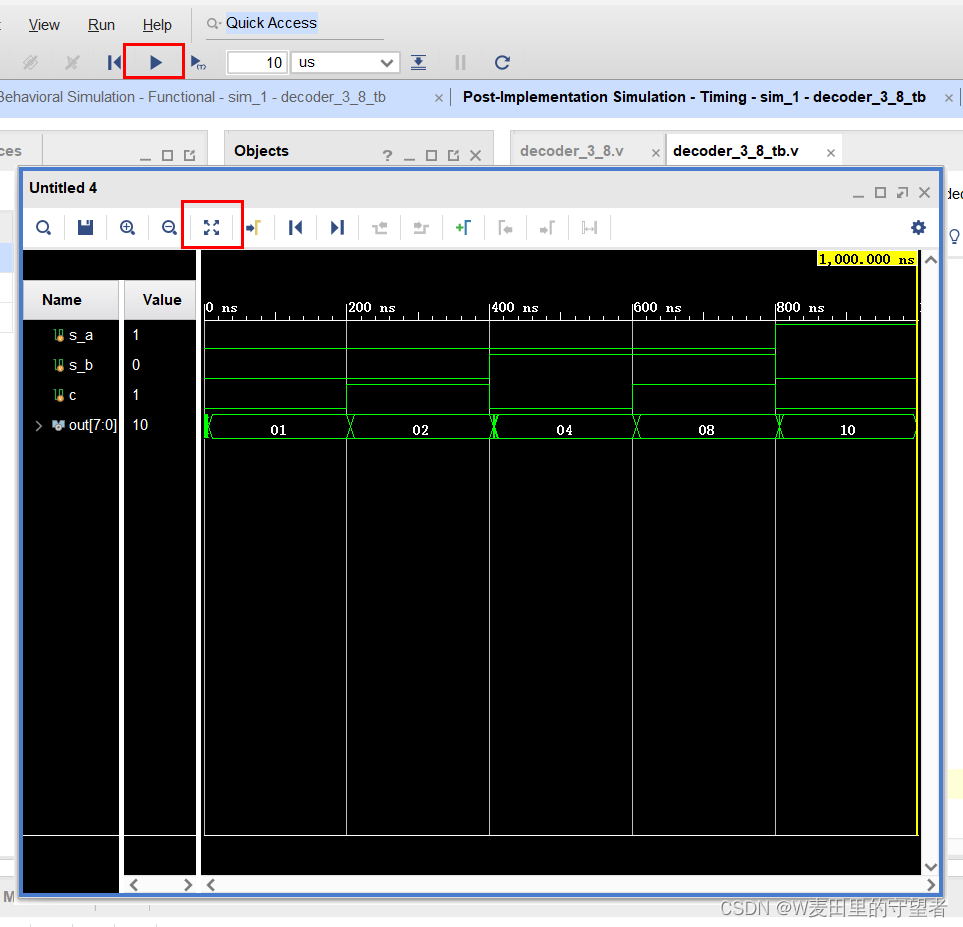
(2)在弹出的界面中,操作放大窗口,并按三角按钮,跑完全部时间波形,分析波形是否正确;
9、引脚分配(Layout / I/O Planning)
(1)双击Open Synthesized Design项;
(2)选择I/O Planning项;
(3)点击Group by Interface and Bus小符号(类似三角形的),显示出全部的引脚,并修改IO的电平,分配引脚;
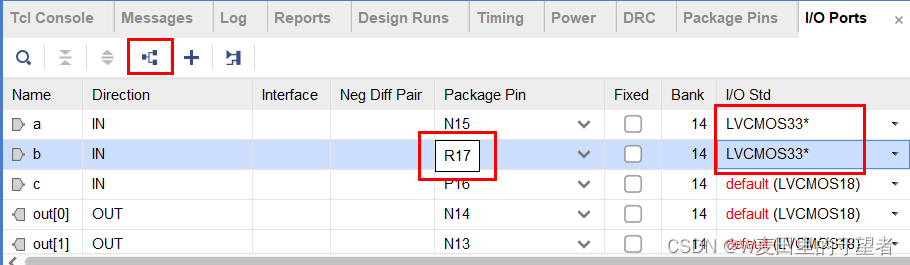
(4)保存,ctrl+S保存,引脚分配文件命名用工程名称;
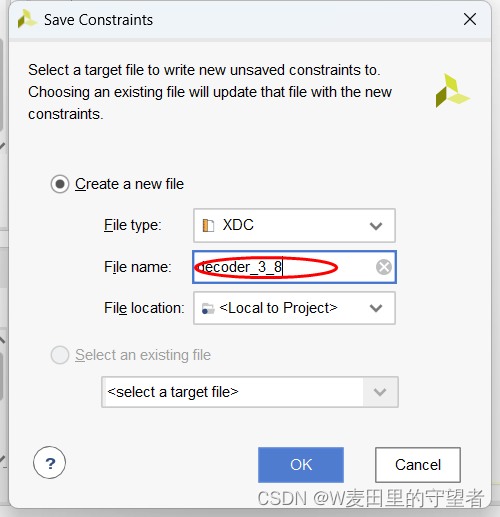
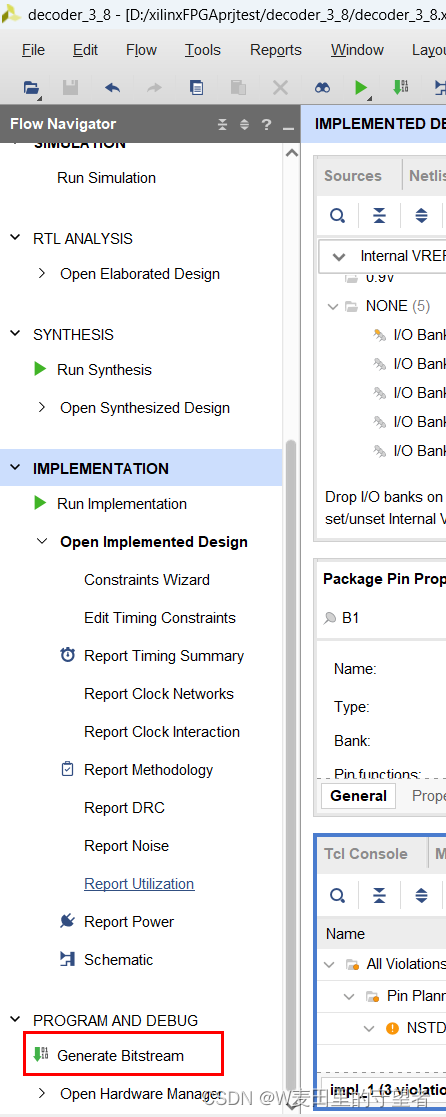
10、生成比特流(Generate Bitstream)
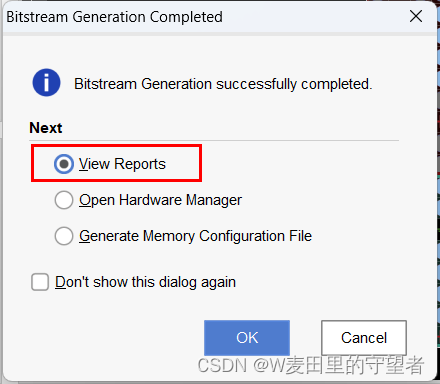
(1)选择Generate Bitstream项,在弹出的Launch Runs对话框选择OK按钮;
(2)可选择View Reports项查看报告或者关闭窗口;
11、下载(Open Target / Auto Connect)
(1)选择Open Target / Auto Connect项,连接Xilinx的FPGA和下载器;
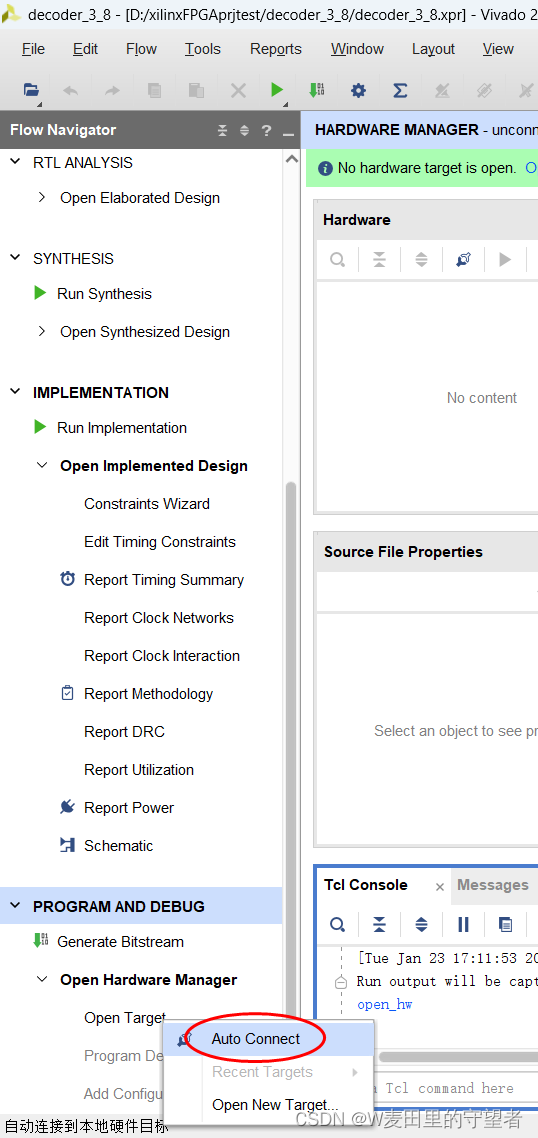
(2)在xc7a35t上面,右击,选择Program Device项;
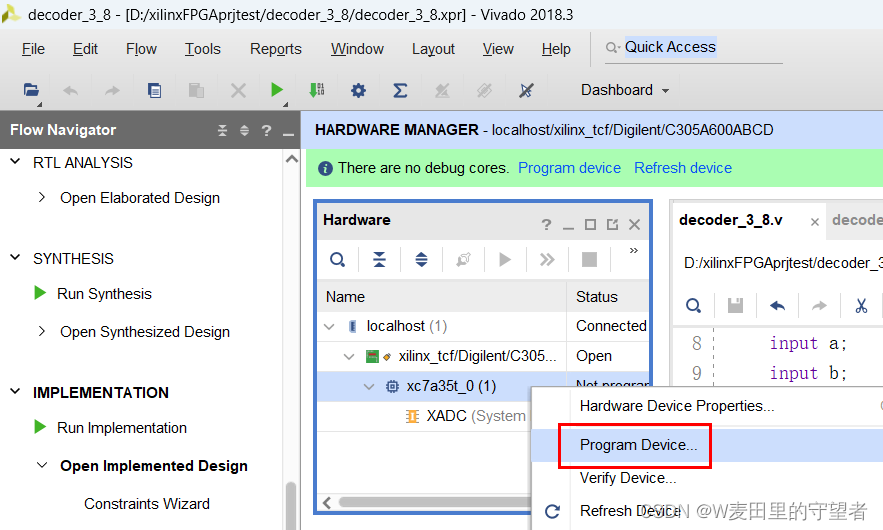
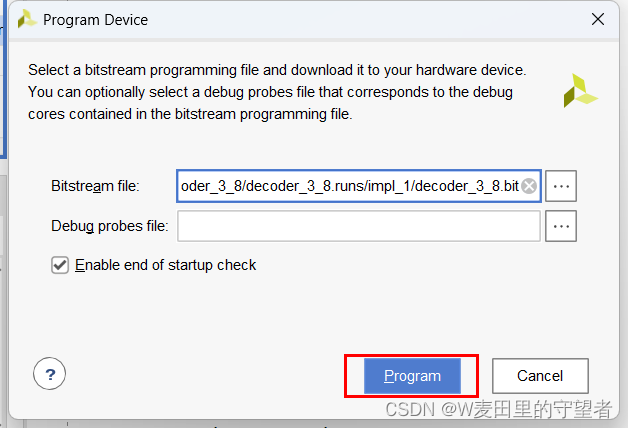
(3)软件自动找到比特流数据,单击Program完成下载;

















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









