







1 RDD 、DataFrame 和DataSet之间的区别
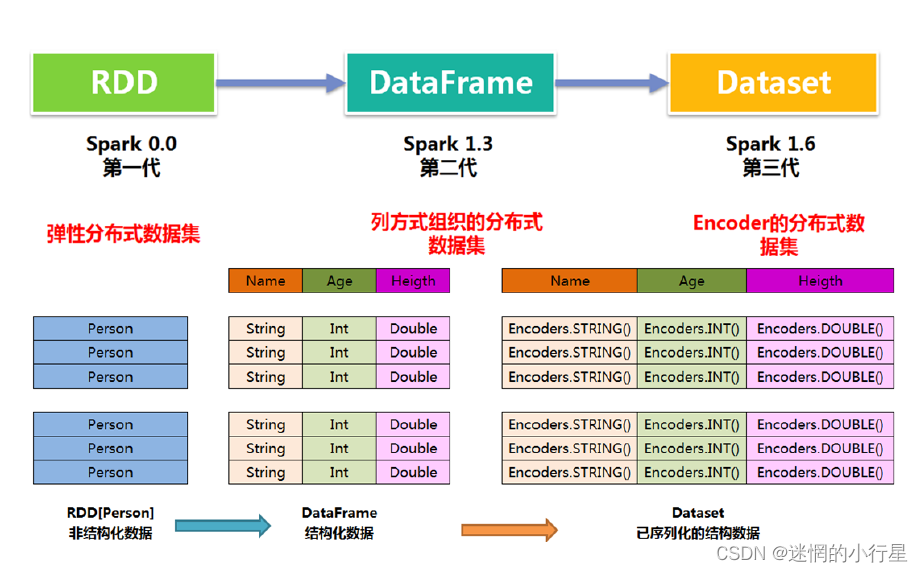
其中从Spark2.0开始: DataFrame = DataSet[row]
DataFram = RDD[row] + schema
DataFrame 每一行的类型固定为Row
DataSet = RDD[case class].toDS
Dataset 每一行的类型都是一个case class
2 Row 和 schmea
row 是一个泛化的无类型Jvm对象
示例:
import org.apache.spark.sql.Row
val row1 = Row(1,"abc", 1.2)
// Row 的访问方法
row1(0)
row1(1)
row1(2)
row1.getInt(0)
row1.getString(1)
row1.getDouble(2)
row1.getAs[Int](0)
row1.getAs[String](1)
row1.getAs[Double](2)
DataFrame 中的数据结构信息(如:数据集中包含哪些列,每列的名称和类型各是什么),即为 schema
定义schema:
import org.apache.spark.sql.types._
val schema = (new StructType).
add("id", IntegerType, false,"id").
add("name", StringType, false,"名字").
add("height", DoubleType, false,"身高")
3 SparkSession创建
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
//通过sparksession可以获得sparkcontext
val sc =spark.sparkContext
//用完关闭sparksession
spark.close()
4 DataFrame和DataSet创建
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{
DataFrame, Row, SparkSession}
import org.apache.spark.sql.types._
object DF_DS_Demo {
def main(args: Array[String]): Unit = {
//获取sparksession和sparkcontext对象
val spark: SparkSession = SparkSession.builder().appName("df_and_ds_test").master("local").getOrCreate()
val sc: SparkContext = spark.sparkContext
//设置日志打印级别
sc.setLogLevel("warn")
//1.通过case class样例类集合直接生成dataset
val seq1 = Seq(Person("Jack", 28, 184),
Person("Tom", 10, 144),
Person("Andy", 16, 165))
//对df和ds进行相应操作时必须先引入,否则在idea里有些方法无法使用
import spark.implicits._
val numDs = spark.createDataset(seq1)
//使用desc函数需要先引入import org.apache.spark.sql.functions._
numDs.orderBy(desc("age")).show()
//打印schema信息
numDs.printSchema()
//2.列表生成dataframe
val lst = List(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val df1: DataFrame = spark.createDataFrame(lst).toDF("name","age","height")
df1.orderBy("age").show()
//为每个字段单独指定名称,改单个字段名时方便
val df2: DataFrame = spark.createDataFrame(lst)
.withColumnRenamed("_1", "name2")
.withColumnRenamed("_2", "age2")
.withColumnRenamed("_3", "height2")
df2.orderBy(desc("height2")).show()
//3.通过RDD[row]和schema对象创建DataFrame
val arr = Array(("Jack", 28, 184.3), ("Tom", 10, 144.2), ("Andy", 16, 165.6))
val rdd1: RDD[Row] = sc.makeRDD(arr).map(f => Row(f._1, f._2, f._3))
val schema1: StructType = new StructType()
.add("name", StringType, false, "姓名")
.add("age", IntegerType, false, "年龄")
.add("height", DoubleType, false, "身高")
val rddToDF: DataFrame = spark.createDataFrame(rdd1, schema1)
rddToDF 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1606
1606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









