









个人学习记录,有参考博文。初学阶段对知识的学习与理解必定会有谬误或误解,希望路过的前辈不吝赐教。
前馈神经网络(Feed-forward Neural Networks)
前向NN是最常见的一种神经网络。他第一层是输入,最后一层是输出,中间是隐藏层。其中,如果隐藏层多于一层,则称为DNN深层神经网络
该种网络的作用就是从输入到输出之间做一系列的变换,所以会在每一层获得一个关于输入的新表征。这个新表征与相邻的层之间既有相似又有不同
举例语音识别:不同的人说相同的话识别更相似,同一个人说不同的话识别更不同

循环神经网络(Recurrent Neural Network)
1、在连接图中有许多的循环,这就代表当你在一个神经元跟随箭头方向走时会回到原点
2、有着非常复杂的动态,所以训练会非常困难
3、更符合生物现实

RNN的特殊之处在于他有着多个隐藏层之间的连接缺失(?难道是类似于人类的健忘)

RNN在对序列模型数据的解决方式上也是非常自然的
我们需要做的就是在隐藏单元之间做出连接,这就需要我们有一个在时间上深入的网络,上一个隐藏单元决定了下一个时间步的隐藏单元的状态(very deep net with one hidden layer per time slice)
每格时间步使用相同的权值矩阵,每时间步得到一个输入
RNN有能力将隐藏层的信息保存很久,但很难训练他使用这一能力。However现在已经有算法可以实现。
统计模式识别的标准
1、获取原始输入转换为一个激活的(?activation)特征向量或集合
2、学习如何分配各个特征的权重以获得一个支持或否认的方向
3、如果获得加权和到达一个阈值,那就说明这个输入是一个对目标类积极的(positive)
标准感知器

几何方向学习感知器(超平面与高维空间):
权值空间(weight space):
一维,空间中的点代表一个特定的权值集合。
假设我们消除了阈值,那么每个训练案例都被看作一个过原点的超平面;空间中的点代表权值,而训练案例代表一个个过原点的平面。
权值点必须在平面的一侧代表这个答案是正确的。



最末为可行解锥(the cone of feasible solution)蓝色为案例case,落在区间内的为正确解。(?但这不应该算二维吗)
感知机工作方式:假设给出一个错误案例,那么算法会移动当前的权值向量向一个可行的权值向量靠拢。表现在几何上(For Proof):
正确的区间即为当前权值点与可行权值点距离为的圆锥面中。但如上图,金色的可行点明显与权值向量移动方相反,解决方法如下:
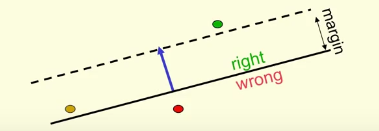
寻找一个非常可行(?generously feasible)的权值向量,并至少保证他在一定范围内是正确的,并且它的长度应当与我们的所训练的输入向量一样长。在这个区间内有一个锥形,它的内部是正确解。
每当感知器出错,所有可行权值向量都会减少至少上述更新向量距离(?a little confused)
如果可行区域存在那么经过有限次错误,权值向量一定会在可行区域中。
感知器所不能做的事:
如果你被允许手动选择特征并且有着足够的特征,那么你可以完成几乎所有事。但该种方式不够通用。
一旦手动设计特征,那么留给机器学习的空间就很少了(very limited)。(意思就是能用switch解决的事不要搞机器学习)
二元阈值神经网络所不能做的事:
二元阈值可实现或、与计算,但无法实现异或。从一个矩阵理解,或、与运算均可以一根线划分,但一根线无法区分异或
例如:区分一个被修饰的简单模式(Discrimining simple pattern under translation with warp-around),如果将像素作为特征,问能否找到一个二重阈值单元来区分有着相同像素值的两个不同模式?答案是不可以的。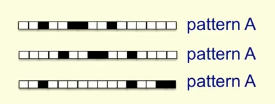
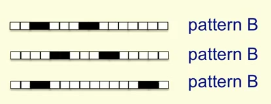
如图,模式A有四个像素,两个单个像素,一个有二像素;模式B也有四个像素,两个二像素。使用二元阈值来辨别上述两个是否为同一模式的方法是行不通的。
原因:模式A中有四个像素被激活,要描述所有的可能需要4*num(为权值总数)的输入;模式B相同。但如果要正确区分两种模式则需要A提供的训练时间多于B,但两者实际上数量等同,所以这就证明了在允许循环平移的情况下一个二值单元无法区分不同的模式。
那么为什么这个结果对于感知器是毁灭性的呢?
主要一点在于感知器应当需要无视模式的各种变换依旧能够准确辨识模式。
群不变性原理(Group Invariance Theoerm):证明了只要变化是可以循环的,同时两个模式的加和是相同的,那么感知机即无法对其进行区分。
为了突破这一缺陷,就要求感知器必须使用多重特征单元去识别变化过的模式的下属模式。这就需要我们在模式识别中较为棘手的部分手动解决。
Thus,我们必须加入隐藏层来实现输出的配对。
BTW,最后结尾老爷子还是指出没有隐藏层的学习是very limited,这个词用了很多次。以至于我现在迫切想知道隐藏层在神经网络中到底发挥了什么神奇的功效。















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









