






© 作者|张高玮
研究方向 | 推荐系统
近年来跨域推荐方法逐渐受到人们的关注,为解决推荐系统中数据稀疏以及冷启动这两个问题提供了新的思路。本文聚焦于跨域推荐,依据解决方法的不同将跨域推荐模型分为基于共享实体表示的模型、基于域间映射的模型、基于异构图嵌入的模型、基于多领域协同训练的模型四大类进行整理介绍,文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
目录
1. 总体介绍
1.1 什么是跨域推荐
1.2 为什么需要跨域推荐
2. 模型分类
2.1 基于共享实体表示的模型
2.2 基于域间映射的模型
2.3 基于异构图嵌入的模型
2.4 基于多领域协同训练的模型
3. 总结与展望
4. 参考文献
1. 总体介绍
1.1 什么是跨域推荐?
在传统的推荐系统中,我们通过分析单一领域内的用户历史交互行为来进行用户兴趣的预测,从而进行推荐,比如说通过用户在抖音app上的历史观看视频来为用户进行后续的视频推荐。而跨域推荐旨在结合多个领域的数据,引入其它领域(源领域)的信息来进行辅助,使得在目标领域甚至多个领域上都能进行更好的推荐。当然,不是随便拿来几个领域都能直接进行跨域推荐,不同领域间一般要存在一些重叠的信息,例如抖音和西瓜视频的公共用户,或者抖音和西瓜视频的相同视频等等都属于重叠信息的范畴,一般需要存在这样的重叠信息,才能进行不同领域间信息的迁移。比如通过公共用户在西瓜视频上的记录建模用户的兴趣,从而在抖音上进行更好的推荐。
1.2 为什么需要跨域推荐?
传统的推荐系统中一方面存在着数据稀疏问题,如用户的观看视频数相比抖音短视频总数来说非常少,存在数据稀疏问题;另一方面存在冷启动问题,如对于新加入app的用户或是新上传的短视频来说,很难进行精确推荐。
而跨域推荐可以有效地解决上述两个推荐系统的痛点,我们可以通过对用户在其它领域的交互信息进行分析,从而捕捉到用户在一定方面的偏好。这样就可以用来丰富目标领域的数据,或者在对新用户启动时增加可供利用的信息,从而在一定程度上解决这两个问题。
当然,跨域推荐系统相比一般的推荐系统要更加复杂。在传统推荐系统中,我们只需要考虑建立当前领域内的一个推荐模型进行分析;而在跨域推荐中,我们更要关心在不同领域间要选择何种信息进行迁移,以及如何迁移这些信息,这是跨域推荐系统中非常关键的问题。那么根据迁移信息的不同以及迁移方法的不同,可以对跨域推荐模型进行分类,也可以根据不同领域间重叠信息的种类进行分类。
2. 模型分类
对于跨域推荐有很多分类标准,不失一般性,这里以两个域(源领域和目标领域)的情况进行说明。比如根据重叠信息的种类进行分类,可以分为四种场景[1]:
1. 两个领域间没有任何重叠(No Overlap)
2. 两个领域间包含重叠用户(User Overlap)
3. 两个领域间包含重叠物品(Item Overlap)
4. 两个领域间既包含重叠用户又包含重叠物品(Full Overlap)
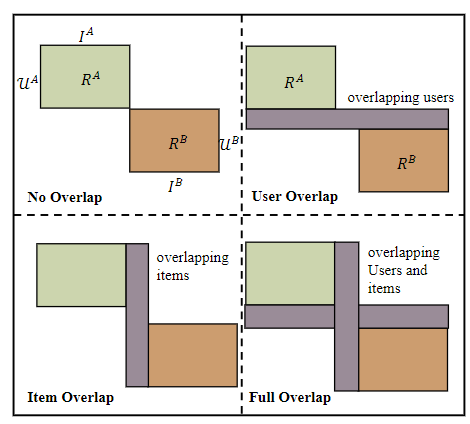
甚至可以更详细地继续划分为九种场景![2]
而由于不同场景中有很多解决方法的思路是非常相似的,这里我将其按照方法进行分类,大致可以分为以下四种:
基于共享实体表示的模型
基于域间映射的模型
基于异构图嵌入的模型
基于多领域协同训练的模型
下面对每一类进行分别介绍,并列举代表方法进行说明。
2.1 基于共享实体表示的模型
适用场景:存在多个推荐领域,领域之间存在重叠实体(用户或物品),实体间的特征一般较为相似,想要提高多个领域上的推荐性能。
核心方法:该类模型关注不同领域间的重叠实体,通过共享或结合重叠实体在不同领域间的表示来融合不同领域的信息,建立领域之间的联系,提高多个领域的推荐性能。一般来说该类模型的结构可以分为三层,首先在embedding层获得用户以及物品在每个域的embedding向量;之后通过结合层将重叠实体(这里以重叠用户为例)的embedding以某种方式进行结合,这样重叠实体的表示向量中就会包含每个领域的信息;最后在预测层训练一个推荐模型,根据用户和物品的embedding表示进行推荐。
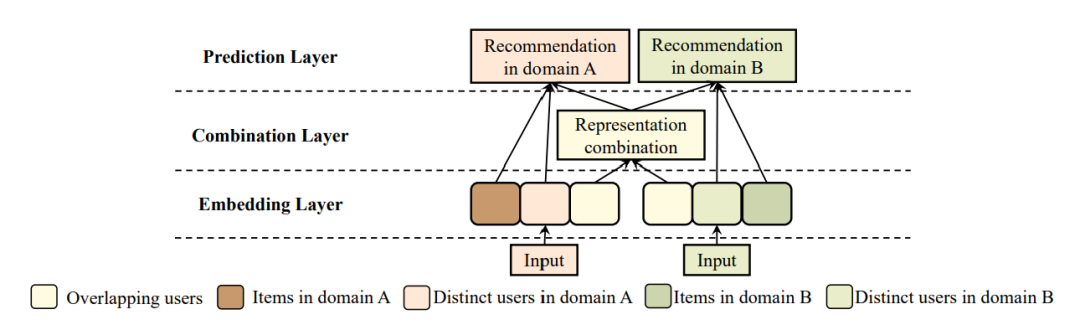
代表模型:
DTCDR(CIKM 2019)[3]
该模型的结构如下图所示,对于每个域中的实体,都根据评分信息+其它内容信息产生不同的embedding表示(如图中的U和UC/V和VC);而结合层对重叠实体来自不同领域的embedding进行了最大值池化,使其保持在每个领域上的鲜明特征(论文还进行了其它实验,如连接操作、平均池化等)。在进入预测层前,将根据评分信息和内容信息产生的不同embedding进行拼接,作为描述该实体的最终embedding表示(如concat{U, UC});在最后的预测层训练一个神经网络(MLP)进行推荐。该方法通过结合不同领域的重叠实体的表示向量,丰富对应的实体向量中包含的信息,以提高在多个领域上的推荐性能。
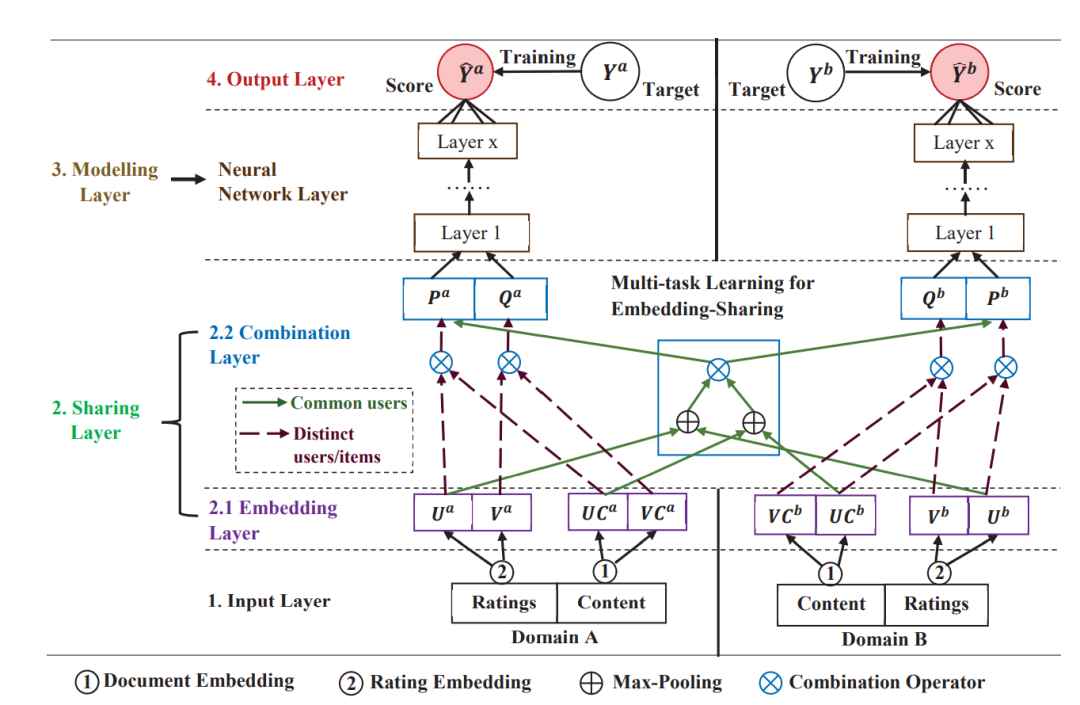
GA-DTCDR(IJCAI 2020)[4]
该方法是基于图嵌入对DTCDR进行了改进,模型结构如下图:
该方法为每个领域的实体构建了一个无向异构图,图中顶点包含用户和物品,无向边分为两种,一种是用户-物品边,另一种是用户-用户/物品-物品边;前者根据rating直接计算,后者根据内容信息利用Doc2vec生成实体向量,将实体向量间的相似性作为边的权值,如下图所示:
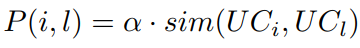
其中UC代表根据Doc2vec生成的向量,相似性计算方法为余弦相似性,α为控制比例的超参数。
得到异构图之后,根据Node2vec生成每个实体的图嵌入(Graph Embedding);在结合层中使用element-wise attention机制将重叠实体(这里是用户)的表示进行结合:
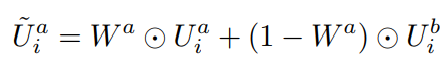
得到最终的表示,然后进入预测层预测:
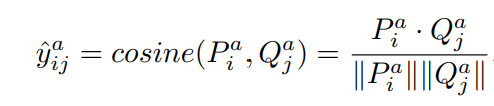
MV-DNN(WWW 2015)[5]
该方法可以看作是DSSM双塔模型的扩展,通过搜集得到的用户特征和物品特征生成初始的embedding,将不同领域的物品作为数据的不同视图(view)输入,用户作为数据的主视图输入,其中所有视图共享相同的MLP结构,但不共享网络的参数。每个物品视图通过MLP结构获得最终的表示向量,然后与用户视图的结果计算余弦相似度作为预测。
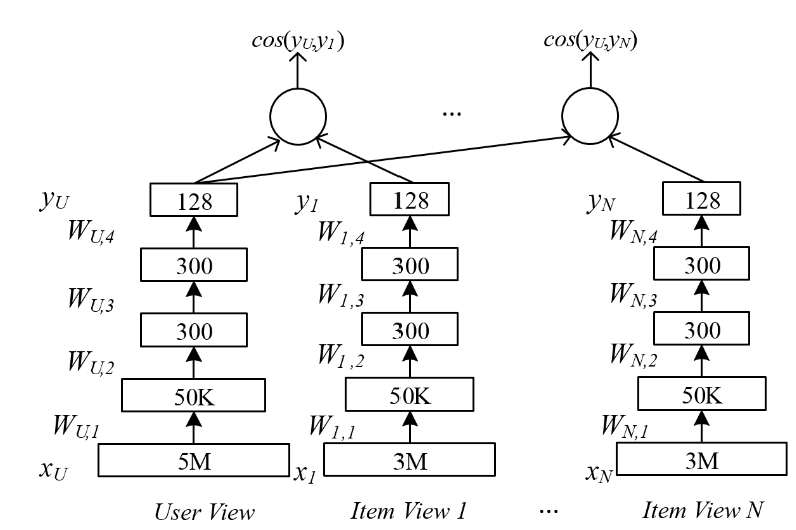
像上面展示的一样,所有物品视图是共享了相同的用户视图的。如果是传统推荐模型的话,应该在每个领域内分别构建一个双塔模型,分别包含一个用户视图和物品视图,如果有N个领域,则会对应有2N个视图。而在MV-DNN中由于共享相同用户视图,则共有N+1个视图。通过共享用户视图使得用户在不同领域内的偏好可以得到有效利用,提高推荐性能。
2.2 基于域间映射的模型
适用场景:存在多个数据较为充足的源推荐领域,以及数据较为稀疏的目标推荐领域,想要提高目标推荐领域上的冷启动推荐性能,而冷启动用户大多在源推荐领域有交互记录。
核心方法:该类模型同样着眼于不同领域间的重叠实体,其利用重叠实体学习一个映射函数(一般是由源领域到目标领域的映射),如下图所示:
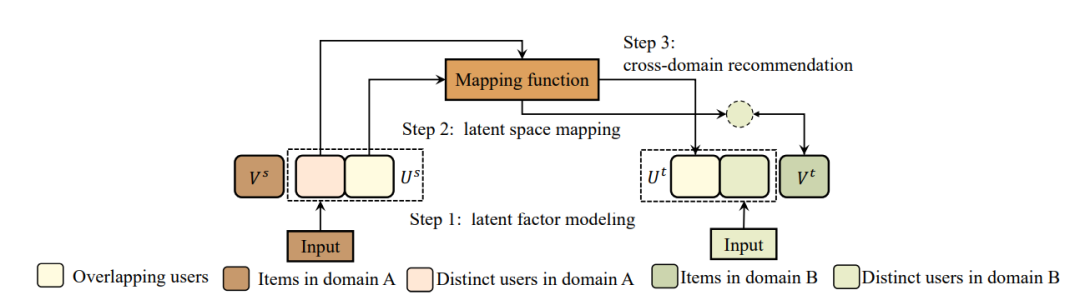
从而对于出现在源推荐领域的目标领域冷启动用户来说,通过映射函数将该用户映射到目标领域特征空间:
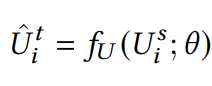
得到用户的新表示后与物品的表示通过一个推荐模型,解决冷启动问题。
代表模型:
EMCDR(IJCAI 2017)[6]
该模型是这一类模型的开山之作,如下图所示:

首先在每个领域对评分矩阵进行矩阵分解得到领域内每个实体的特征表示,即用户表示U和物品表示V;之后其利用重叠实体(以用户为例)训练一个由源领域到目标领域的映射函数,可以使用RMSE作为损失函数:
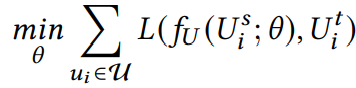
试图使映射后的用户表示接近目标领域的用户表示。
映射函数可以是线性的(图中step2 Linear mapping),也可以是非线性的(图中step2 MLP mapping)。
训练完成后利用得到的映射函数便可以将冷启动用户映射到目标领域,进行推荐。
DCDCSR(IJCAI 2018)[7]
该模型延续EMCDR的思路,不过学习的映射函数是由目标领域到标准领域的映射函数:
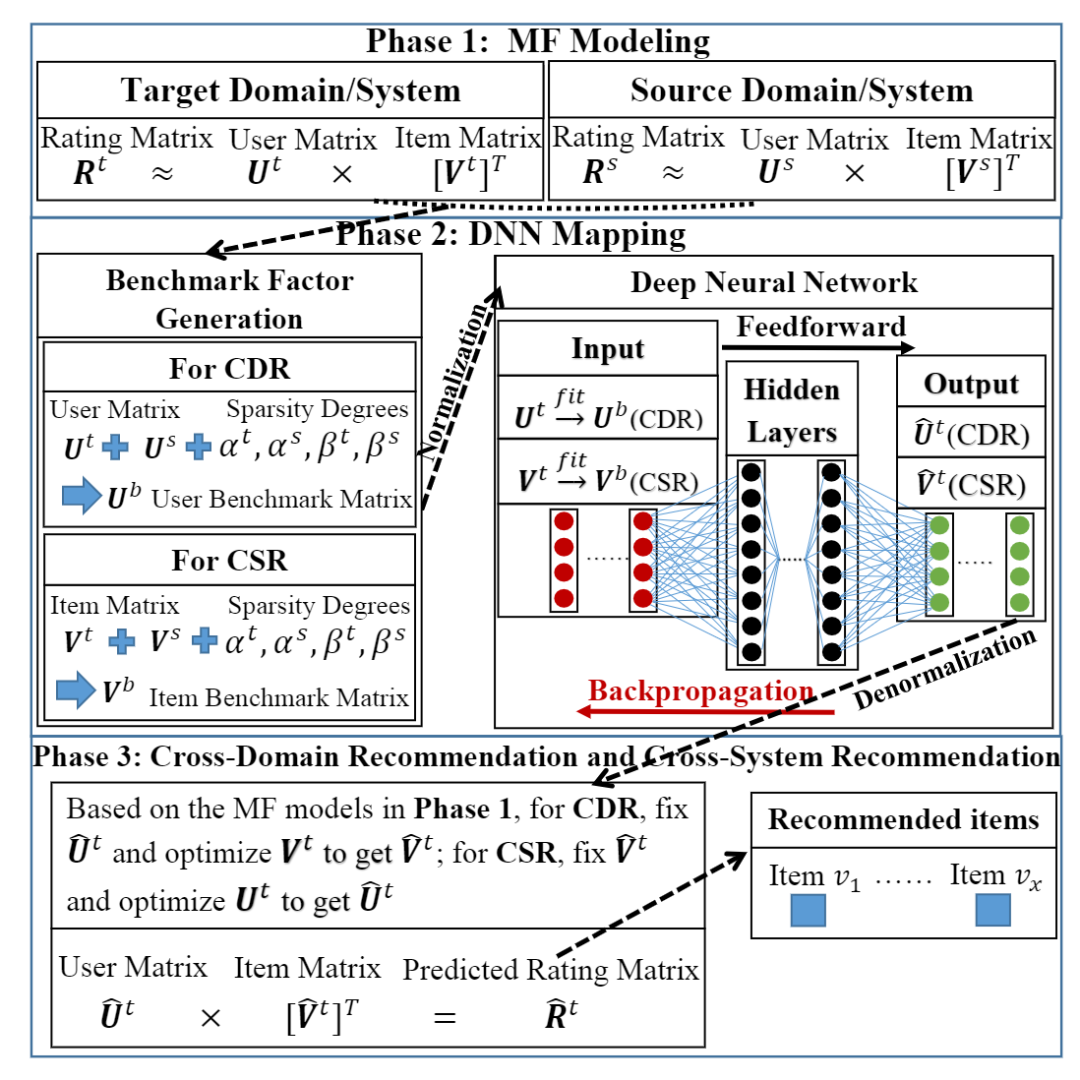
标准领域即通过矩阵稀疏度将源推荐领域和目标推荐领域融合到一起的特征空间,该特征空间被认为是融合了多个领域信息的一般化的标准领域。
同样是利用重叠实体(用户或物品)来学习映射函数,之后利用该函数对目标领域的用户映射到标准领域进行推荐。一般要求用户在目标领域有一定的交互,才能进行更好的推荐。
SSCDR(CIKM 2019)[8]
该模型的作者认为基于映射的模型中,映射函数的好坏受重叠实体比例的影响很大,现实中往往这个重叠比例是很小的,可能会导致映射函数的学习不充分,不能达到令人满意的泛化效果。而该模型通过设计无监督损失函数,将整个模型转化为半监督学习过程:
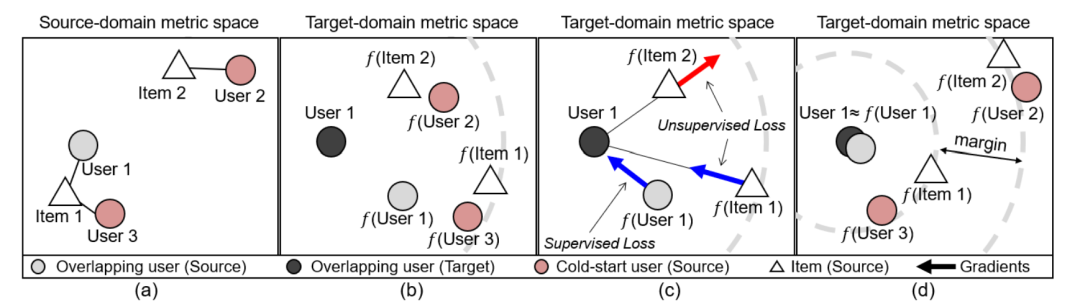
从而可以利用领域内丰富的非重叠实体数据,使得学习得到的映射函数更加鲁棒,提高推荐性能。
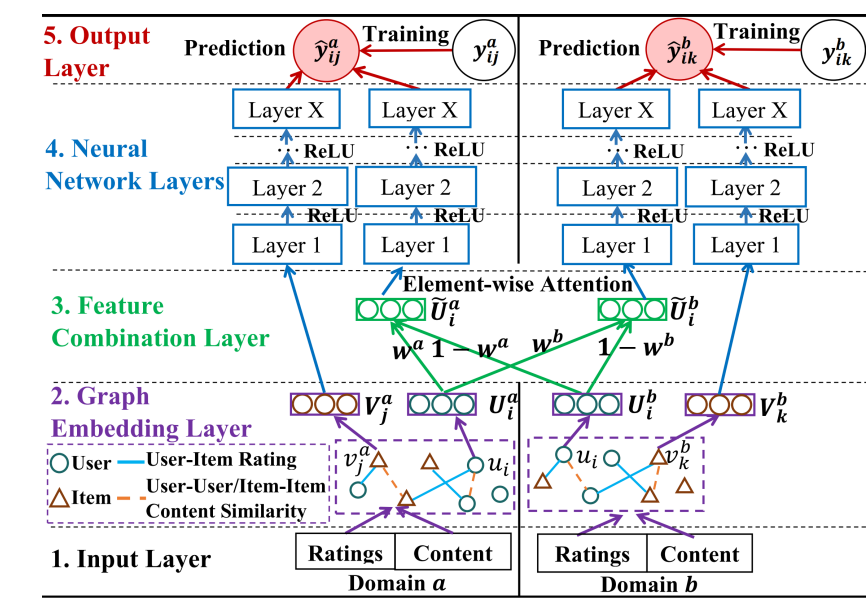
2.3 基于异构图嵌入的模型
适用场景:不同领域间有一定的重叠实体,并且除评分信息外一般要具有一些辅助内容信息,如用户评论,物品标签等等,使得用户-用户的相似性以及物品-物品的相似性可以很好地衡量,想要提高多个领域上的推荐性能。
核心方法:该类模型利用不同领域的实体建立一个所有领域共享的异构图,如下图所示:
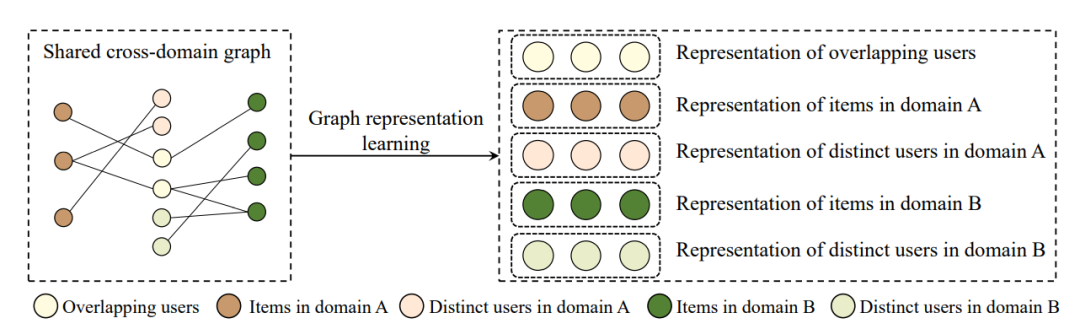
通过将全部交互信息以及内容信息整合到一个共享图中,用户以及物品在不同领域的特征可以被全面地考量,使得对用户以及物品的建模更加鲁棒。顶点之间的边一般用某种相似性进行表示,如用户-物品边可以用正则化的评分表示,用户-用户边用内容向量的相似性表示。之后利用图表示学习(如GraphSAGE)得到顶点的表示向量,通过推荐模型进行推荐。
代表模型:
HeroGraph(RecSys 2020)[9]
该模型对于每个实体分别学习两个表示向量,分别是通过embedding层得到的领域内的表示向量,以及通过异构共享图学习得到的向量:
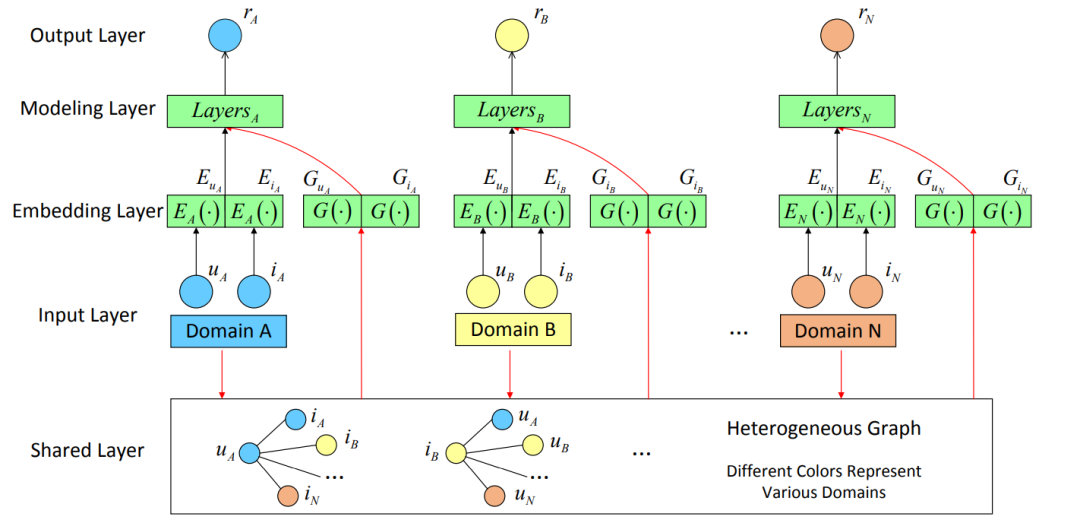
将二者以某种方式结合起来(如拼接,池化等)就得到了每个实体的表示向量。如此一来,在每个领域内,用户和物品的表示都得到了,通过一个推荐模型(如MLP,内积等)就可以得到评分预测,从而在多个领域上实现更好的推荐。
2.4 基于多领域协同训练的模型
适用场景:领域之间的关系不明显,或者不想对领域间的关系进行建模,想要直接利用多个领域的数据提高多个领域上的推荐性能。
核心思路:利用多个领域的数据同时对多个领域上的模型进行训练,通过模型间的信息交互使得每个领域的模型的推荐性能得到提高。
代表模型:
XPTRANS(AAAI 2016)[10]
该模型是一个矩阵分解模型:
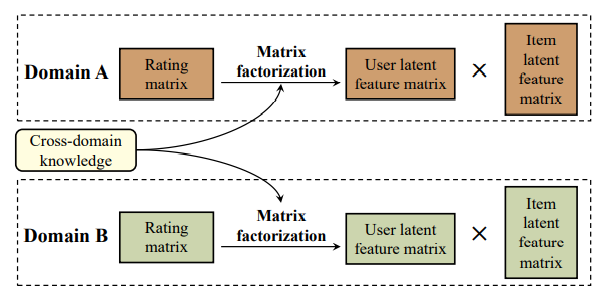
相比于一般的矩阵分解模型,其对源领域和目标领域两个领域进行联合分解,同时将跨域知识作为约束条件指导矩阵分解,使得联合分解的结果包含一定程度的域间交互知识。
其损失函数如下:
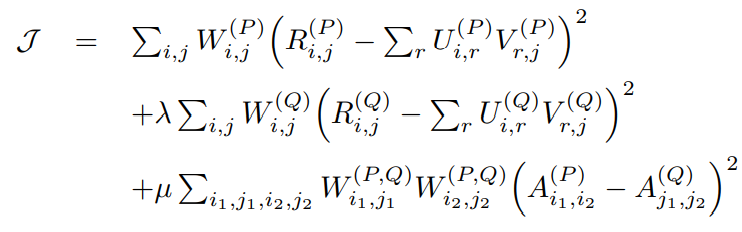
前两项分别作为目标领域(P)上的分解损失以及源领域(Q)上的分解损失,λ为控制源领域影响程度的超参数(W为指示因子矩阵)。最后一项作为跨域知识约束,其中计算目标领域上的用户相似性,计算源领域上的用户相似性,W作为指示因子使最后计算的相似性只包含在重叠用户之间。其依据的跨域知识为:“对于重叠用户来说,即使位于不同领域,重叠用户之间的相似性也是趋于一致的”。基于此假设便有了上述损失函数。
CoNet(CIKM 2018) [11]
该模型为两个领域分别设计了一个前向神经网络作为推荐模型,如下图所示:
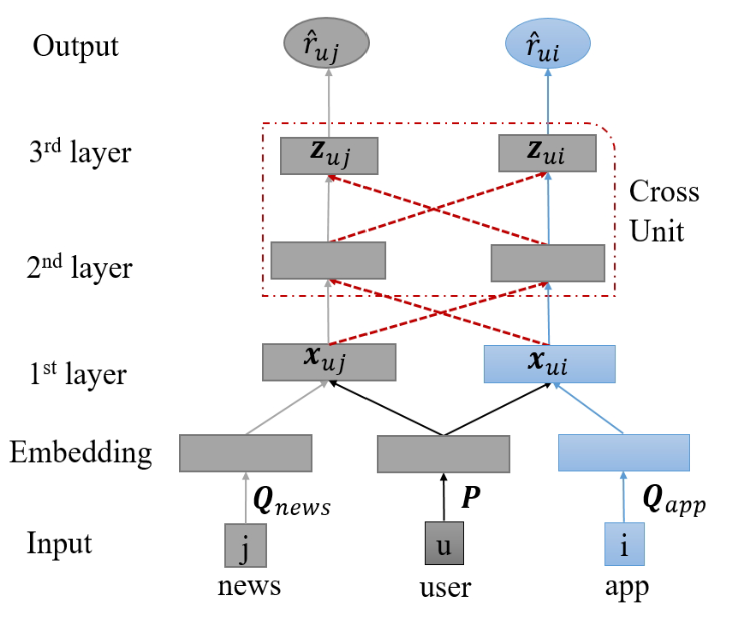
特殊的地方在于每一层接收的输入不仅包含该领域的网络前一层的输出,同时包含另一个领域前一层的输出,实现一种对偶的信息交互,这种对偶的结构(Cross Unit)如下图所示:
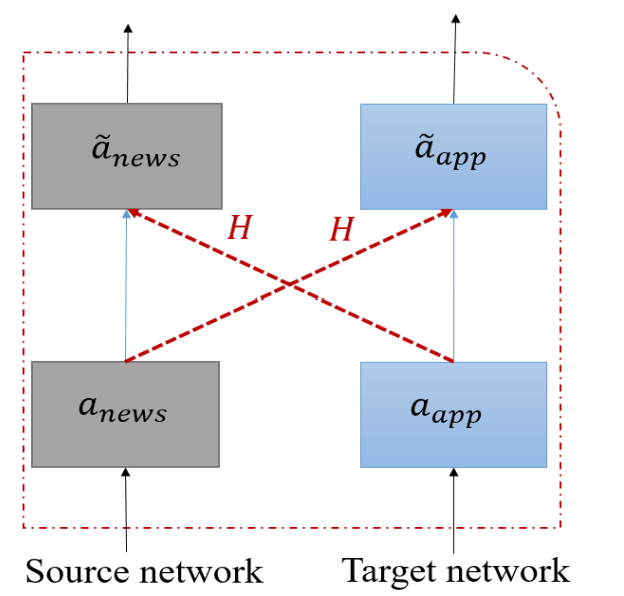
通过一个矩阵H对另一个领域前一时刻的输出进行一次线性变换,用来控制另一个领域对该领域的影响。这样每个网络中的每一层都在进行对偶的信息交互,并没有显式地建模领域之间的关系,却能使得每个领域在推荐过程中都能很好地利用其它领域的信息,提高推荐性能。
3. 总结与展望
本文总结了在跨域推荐领域一些常用的方法体系,将这些常用模型分为基于共享实体表示的模型、基于域间映射的模型、基于异构图嵌入的模型、基于多领域协同训练的模型四大类,并列举经典的代表模型进行分析。可以看到目前跨域推荐任务还并没有特别成熟,有着多样化的发展方向,从近两年的顶会文章来看,将debias与跨域推荐相结合[12]以及将元学习与跨域推荐相结合[13]是值得研究的方向。与此同时,在实际跨域推荐的应用场景中,对于用户敏感信息的隐私保护也是需要重点关注的!
4. 参考文献
[1] Cross-Domain Recommender Systems. ICDMW 2011.
[2] A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions.
[3] DTCDR: A Framework for Dual-Target Cross-Domain Recommendation. CIKM 2019.
[4] A Graphical and Attentional Framework for Dual-Target Cross-Domain Recommendation. IJCAI 2020.
[5] A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems. WWW 2015.
[6] Cross-Domain Recommendation: An Embedding and Mapping Approach. IJCAI 2017.
[7] A Deep Framework for Cross-Domain and Cross-System Recommendations. IJCAI 2018.
[8] Semi-Supervised Learning for Cross-Domain Recommendation to Cold-Start Users. CIKM 2019.
[9] HeroGRAPH: A Heterogeneous Graph Framework for Multi-Target Cross-Domain Recommendation. IJCAI 2017.
[10] Little Is Much: Bridging Cross-Platform Behaviors through Overlapped Crowds. AAAI 2016.
[11] CoNet: Collaborative Cross Networks for Cross-Domain Recommendation. CIKM 2018.
[12] Debiasing Learning based Cross-domain Recommendation. KDD2021.
[13] Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users. SIGIR 2021.















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









