







关注我们,一起学习~
标题:CL4CTR: A Contrastive Learning Framework for CTR Prediction
地址:https://arxiv.org/pdf/2212.00522.pdf
代码:https://github.com/cl4ctr/cl4ctr
会议:WSDM 2023
学校,公司:复旦,微软
1. 导读
现有点击率建模忽略了特征表征学习的重要性,例如,为每个特征采用简单的embedding层,这导致了次优的特征表征,从而降低了CTR预测性能。例如,在许多CTR任务中占大多数特征的低频特征在标准监督学习设置中较少被考虑,导致次优特征表示。本文引入了自监督学习来直接生成高质量的特征表征,并提出了一个模型不可知的CTR对比学习(CL4CTR)框架,该框架由三个自监督学习信号组成,以规范特征表征学习:对比损失、特征对齐和域一致性。对比模块首先通过数据增强构造正特征对,然后通过对比损失最小化每个正特征对的表征之间的距离。特征对齐约束迫使来自同一域的特征的表征接近,而域一致性约束迫使来自不同域的特征表征远离。
感觉本文更多的是将旧方法应用于新领域,可能之前没有将这种想法应用于推荐领域的,域一致性和对其约束这些在其他领域(图像等)还是蛮多的。
2. CL4CTR
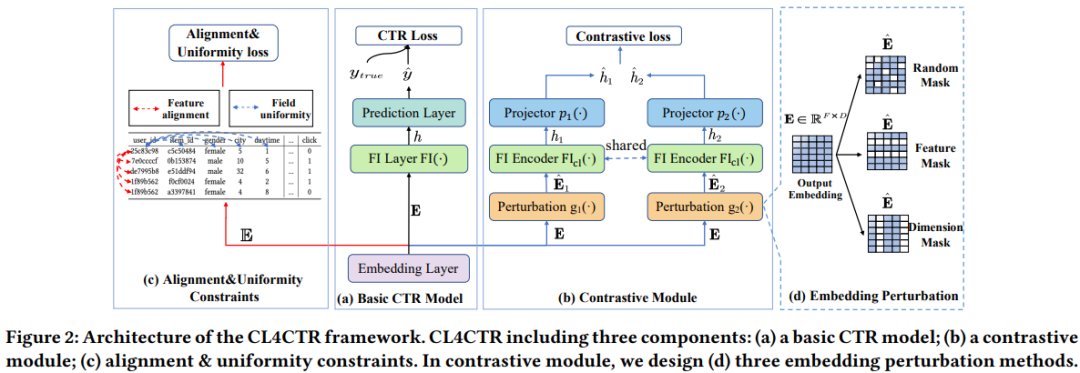
2.1 CTR预测任务
CTR预测是一项二分类任务。假设训练CTR预测模型的数据集包含N个实例 (x, y), (点击与否)是用户点击行为的真正标签。输入实例x通常是多字段表格数据记录,其中包含F个不同的领域和M个特征,如图2(a)所示,许多CTR预测模型遵循共同的设计范式:embedding层、FI层(即特征交互层)和预测层。
embedding层将输入的稀疏特征转换成稠密的embedding矩阵,,D为embedding维度。用表示所有特征的表征矩阵,其中表示属于域f的特征的表征矩阵,,表示属于域f的特征数。
特征交互层,FI层通常包含各种类型的交互操作,以捕获任意顺序的特征交互,例如MLP、Transformer等。将这些结构称为特征交互编码器,表示为可以生成紧凑的特征交互表征。
预测层通过MLP和sigmoid得到预测分数,通常采用交叉熵损失函数计算损失,
对比学习,如图2所示,除了上述组件,本文提出了三个对比学习方式:对比损失、特征对齐约束和embedding层顶部的域一致性约束,以正则化表征学习。由于这些信号在模型推断过程中是不必要的,因此这些方法不会增加推断时间。
2.2 对比模块
2.2.1 数据增强
在序列推荐的场景中,有三种常用的数据增强方法:商品屏蔽、重新排序和裁剪。然而,这些方法适用于增强行为序列,并且没有适当地部署在基于FI的CTR预测模型中。因此,本文首先提出了三种面向任务的增强方法,旨在干扰基于FI的模型的特征embedding。如图2(d)所示,使用函数表示数据增强过程。
随机屏蔽(Random Mask):该方法类似于Dropout。该方法以一定概率p随机屏蔽初始embeddingE中的一些元素。随机屏蔽生成如下,Bernoulli(·)是伯努利分布,是伯努利随机变量矩阵。
特征屏蔽(Feature Mask):在初始embedding中屏蔽特征信息,其中特征屏蔽方式如下,设定一个比例p 特征 长度为. 是E中特征的索引。如果一个特征被屏蔽,则该特征的表示将被替换为[mask],这是一个零向量。
维度屏蔽(Dimension Mask):特征表征的维度影响深度学习模型的有效性。受FED的启发,FED试图通过捕获维度关系来提高预测性能,本文通过替换特征表征的维度信息的特定比例来扰动初始embedding,如下所示,d是伯努利随机变量。
通过上述方法中的其中一种生成两个扰动后的embedding,,然后进行后续的对比学习
2.2.2 特征交互编码
使用特征编码器对上述得到的两个embedding矩阵进行编码,进行特征交互可以表示为下式,
任何FI编码器都可以部署在CL4CTR中,例如Cross Network,自注意力等。本文选择Transformer层作为主要FI编码器,广泛用于提取特征之间的向量级关系。
经过FI后的h的位数可能很大,所以这里做了一个降维操作,用MLP降维,,p是MLP。
2.2.3 对比损失
最后,应用对比损失函数来最小化上述两个扰动表征之间的期望距离,如下所示,B是batch大小。
2.3 特征对齐和域一致性
为了确保低频特征和高频特征被同等地训练,一种简单的方法是在训练期间增加低频特征的频率或减少高频特征的频率。可以通过引入两个关键属性(称为对齐和一致性约束)来实现类似的目标,但他们需要构建正样本对和负样本对来优化这两个约束。在CTR预测任务中,发现同一域的特征类似于正样本对,而不同场的特征则类似于负样本对。因此,本文提出了CTR预测中对比学习的两个新特性,即特征对齐和场均匀性,它们可以在训练过程中正则化特征表征。具体而言,特征对齐会将同一字段中的特征表征拉得尽可能接近。相比之下,域一致性将不同场的特征表征推得尽可能远。
2.3.1 特征对齐
首先,引入了特征对齐约束,该约束旨在最小化来自同一域的特征之间的距离。通过添加特征对齐约束,同一域中的特征表示应在低维空间中更紧密地分布。特征对齐的损失函数如下,两个e是来自同一域的两个特征embedding。
2.3.2 域一致性
最小化以下损失函数来保证域一致性,使用余弦相似度来约束负样本对的embedding之间的相似性。
2.4 多任务训练
结合上述的所有损失函数,总损失函数如下
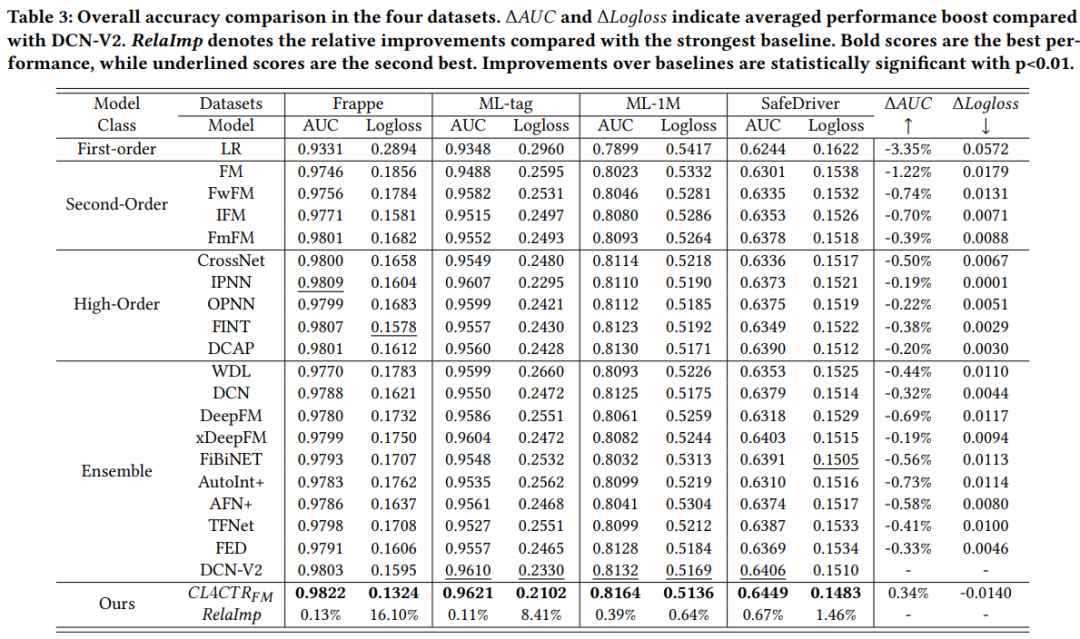
3. 结果















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









