







由于最近入手NLP任务,需要看一些paper,本文对最近两周看的paper做个总结,适用于有deep learning背景,希望了解NLP应用的同学,主要针对NLP方向: 问答系统(QA)和翻译(Machine Translation)。本文提到的12篇paper比较有代表性,这里感谢总理和江哥提供部分参考paper和指导帮助。
论文列表:(其中QA为Question Answer的缩写)
Neural Machine Translation by Jointly Learning to Align and Translate
任务: 机器翻译
关键词:attention BiRNN
中心思想: English -> encoder -> decoder -> Chinese。其中encoder一般是一个RNN,读入一个词序列,输出一个表示该句话的vector;decoder一般也是一个RNN,输入该句话的表示vector,再以序列输出,每个时刻预测下一个词 yt 。常用优化目标:令 p(y) 最大,其中
c是encoder输出的原句vector表示,
st 是decoder RNN的 hidden state,
yt−1 是 t−1 时刻预测的翻译词,
g 是非线性函数。i.e., 基于{上一时刻预测词,当前decoder状态,输入句子(待翻译句子)的encoder vector表示} 确定当前时刻输出词。
方法:本文中,
encoder: 一个双向RNN,从前到后,从后往前各读一遍输入序列
decoder: encoder的c变成了ci
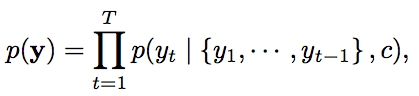
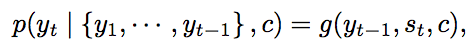
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9536
9536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









