









第1关:基于支持向量机模型的应用案例
任务描述
本关任务:编写一个基于支持向量机模型的应用案例。
相关知识
在本应用案例中,我们借助一个具体的实际问题,来完整地实现基于支持向量机模型的开发应用。在此训练中,我们会介绍如何加载数据集、训练集与测试集的划分,以及如何利用sklearn构建支持向量机模型。
SVM应用案例之数据加载
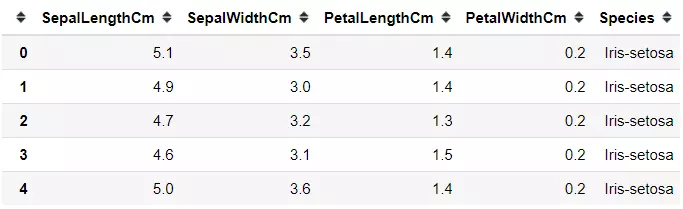
Iris数据集是机器学习任务中常用的分类实验数据集,由Fisher在1936收集整理。 Iris中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set,是一类多重变量分析的数据集。Iris一共包含150个样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
样本局部截图:
我们可以通过以下方法从sklearn库加载该数据集。
dataset = load_iris()
SVM应用案例之数据划分
我们通常使用 train_test_split() 函数来随机划分样本数据为训练集和测试集,这样做的好处是随机客观的划分数据,减少人为因素。
其中该函数中包含的参数为:
train_data:待划分样本数据
train_target:待划分样本数据的结果(标签)
test_size:测试数据占样本数据的比例,若整数则样本数量
random_state:设置随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样 具体实现如下:
x_train,x_test,y_train,y_test = train_test_split(data_x,data_y,test_size=0.3)
SVM核心算法实现
sklearn库是机器学习领域当中最知名的 python 模块之一。他包含了很多种机器学习的内容,如分类,回归,数据处理,模型选择等等,用途广泛且非常方便,其中就包括了支持向量机模型,我们可以轻松地调用sklearn库中封装好的svm函数实现操作,具体操作如下:
from sklearn import svm;//调用sklearn库中的svm函数clf = svm.SVC();//调用svm函数中的SVC核心算法
SVM应用案例之评价指标
在分类任务中,常有的评价指标如下图所示。
针对二分类问题,即将实例分成正类(positive)或负类(negative),在实际分类中会出现以下四种情况: (1)若一个实例是正类,并且被预测为正类,即为真正类(True Positive TP) (2)若一个实例是正类,但是被预测为负类,即为假负类(False Negative FN) (3)若一个实例是负类,但是被预测为正类,即为假正类(False Positive FP) (4)若一个实例是负类,并且被预测为负类,即为真负类(True Negative TN)
我们常用准确率来衡量分类器正确的样本与总样本数之间的关系。 具体公式为
Accuracy =TP+TN+FP+FNTP+TN
在本次应用案例中,我们通过比较预测值与真实值来统计预测正确的数目,具体实现如下:
cnt = 0 //初始化为零for i in range(len(y_test)): //通过循环来遍历寻找预测正确的数目if y_predict[i] == y_test[i]:cnt +=1print(cnt/len(y_predict)) //由预测正确的数目除以总数目得到准确率accuracy。
第1关任务——代码题
from sklearn import svm # 加载sklearn库来调用svm算法
from sklearn.datasets import load_iris #加载sklearn库中的数据集
from sklearn.model_selection import train_test_split #划分测试集训练集
#1.加载数据集
################# Begin #################
datas = load_iris()
################# End #################
data_x = datas.data #定义数据
data_y = datas.target #定义标签
#2.划分训练集和测试集
################# Begin #################
x_train,x_test,y_train,y_test = train_test_split(data_x,data_y,test_size=0.3)
################# End #################
#3.调用svm函数
################# Begin #################
from sklearn import svm;
clf = svm.SVC();
################# End #################
clf = clf.fit(x_train,y_train) #开始训练svm模型
a = clf.predict(x_test) #开始测试
cnt = 0
for i in range(len(y_test)): #评价预测的结果
if a[i] == y_test[i]:
cnt +=1
print(cnt/len(a))

















 2083
2083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











