






自动驾驶决策中的不确定性
在非网联环境下,自动驾驶车辆在决策过程中,最棘手的问题是不知道环境车辆下一步的动作,或者说,不能很好地预知下一步的动作。在本文中,统一将可以受我们所制定的策略所控制的车辆称为自车,环境车辆称为他车。本文主要对比和参考的两篇文献已列在下面。
传统的自动驾驶分层框架是,首先根据感知信息预测他车的行驶路径和行驶速度,以此为基础进行自身动作的决策。除此之外,可以根据感知信息同时求解他车的动作预测以及自车的动作决策。是否要同时预测和决策的问题,还是先预测再决策,是两类不同的解决方法。而要注意的是,无论是哪种方法,最终求解的他车策略并没有用于他车的控制。
附赠自动驾驶最全的学习资料和量产经验:链接
问题描述
[1]中描述这样一个问题:自车是右下角这辆车,我们认为自车的路径已经确定,需要控制的是它的速度,他车是左上角这辆车,有三种可能的轨迹。文中定义系统的状态空间为: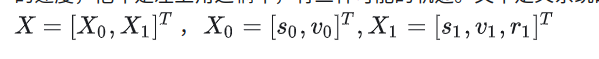
�1是系统的不可观测变量,因此建模成一个POMDP问题。他车的策略由基于规则的方法给出(考虑了自车的状态),使用ABT求解该问题得到自车的策略。

[2]中描述这样一个问题:自车是位于匝道的蓝车,同时主道有三辆他车,自车需要选择合适的时机和位置换道进入主道。通过建模成一个leader-follower博弈问题显式表示自车和他车的交互,加入对于汇入位置不确定性的轨迹,求解得到他车的策略,最后通过MPC求解得到自车策略,也是一个先预测再决策的问题。

以上的两篇文章中都将问题建模成了一个MDP问题,但是具体的解法并不相同。
基础知识
我们这里认为已知车辆的动力学模型,那么可以认为状态转移方程是可以预测的,可以认为是一个model-based的问题。

同时也不要混淆_激进_ 和_保守_。同一策略下,如果自车和他车的状态不同,那么即使是同一策略,得到的动作自然不同,这不是激进和保守的区别,策略可能没有改变。同一个驾驶员,在不同的时间策略会发生改变,如果策略变化(称为动态策略,后面会详细介绍);不同的驾驶员,策略自然也会不同。如何衡量策略的变化?如果策略变化,策略网络的参数会变化,另外在判断策略是否变化时,一定要在同一状态下进行动作的比较。
最后,不要混淆智能体和环境。在使用MDP这套模型时,认为环境内部有一个状态更新函数(状态转移概率,也可以理解成状态方程,因此环境具有马尔可夫性)。agent内部是策略函数(状态到动作的映射,也可以理解成控制方程),因此智能体和环境合起来才是MDP。如果是不完全可观的话,说明agent观测到的状态里面有分量是不确定的,因此在POMDP问题中会用一个概率分布来表示状态,求解得到的就是状态分布到动作的映射。
总结一下,我们要解决的基本问题可以这样来描述:

何为不确定性
我们要解决的问题本质上还是一个如何更好地预测他车的问题,自车不知道他车的策略是怎样的,不知道他车是否预测了我的策略,也不知道他车的策略是否会发生变化。这些都是对他车策略或者未来状态进行预测的不确定性,其实也是对于环境预测的不确定性。除了预测不确定性外,还有观测的不确定性、动力学方程不确定性等等,我们这里主要关注预测的不确定性。对于不同的不确定性,有不同的补偿方法。
在之前的讨论中,我们经常说他车意图,那么究竟什么是意图?我们这里将意图理解为相对的上层策略或者上层策略得到的动作。因为策略也是分层的,随着状态和动作的定义不同,策略这个映射也会不同。有一部分更宏观的上层动作,比如行驶的路径可以被纳入进状态空间,估计(或者即使根据规则确定)了这一部分的动作后,他车的下层策略还是需要求解的,比如行驶速度策略。被纳入状态空间的上层动作分量具有不确定性,举例来说就是,[1] 中他车会选择哪条路径来行驶,[2]中他车会选择跟在自车后面还是超到自车前面(这里没有把自车换道的时机引入进状态空间)。虽然求解出来的他车下层策略也具有不确定性,但是不再对其考虑。
用数学语言来描述,

关于要不要引入不确定的上层动作到状态空间中,如果引入,就能够在求解过程中进行考虑,在奖励函数中或其他地方显式地体现,能够得到比最保守的策略更拟人的策略,在估计了这部分上层动作或上层策略后,可以认为对环境的理解更充分了,这是POMDP的思路;如果不引入,可以做一个完全可观测的状态变量到动作的映射,但是这样对于环境的理解不够充分,预测状态转移的不确定性太高。举例来说,同样位置下的他车,下一时刻可能会变化到完全不同的位置,而一旦能够较好地估计他车的路径,对于他车的状态转移就比较确定了。
有一个问题是,对于他车上层策略的估计其实也是包含在历史数据里的,所以这样做是否有效还存疑。
何为交互式问题
组里的师兄在解决交互式问题的时候是这样说的:A的决策会受到B的影响,并且A知道B的决策会受到A的影响,也就是双方都知道他们的交互是双向的。引入交互式是对他车策略制定时会预测了自车策略或状态的假设。这里更数学地将这种交互式问题表示如下:
求解这一模型,可以同时得到对自车的决策和对他车的预测。博弈的建模体现了“交互”,“交互”的关键是我在做决策时会预测交互者的策略,交互者在做决策时会也预测自车的策略。这里用博弈建模来预测他车策略(其实同时也会求解出自车的策略),这部分是多智能体问题。求解单智能体问题,一般得到的是确定性策略,求解多智能体/博弈,得到的是随机策略。
博弈问题中也可能暗含着不确定性,在[2]的leader-follower模型中,因为增加了对于leader和follower这层关系(可以看作是汇入位置的不确定性),通过贝叶斯方法估计了这一不确定性后,才能进行他车策略的预测,进而进行自车策略的求解。这一不确定性可以不引入,比如可以根据规则来制定。
有一个问题是,是否需要显式建模交互这一概念,因为即使使用了多智能体,求解的也是静态策略。自车肯定会考虑他车,他车是否考虑自车以及他车如何考虑自车,这个已经包含在训练过程中了,那么是否必要显式表示出交互还存疑。
静态策略与动态策略
我们之前已经提及了静态策略与动态策略的问题,是为了考虑他车的策略是否会发生变化的问题。所谓动态策略,就是指策略网络参数会随着时间变化,或者说同样状态下对应的动作会随着时间变化而改变,这样一个问题是很难求解的。因为如果认为他车的策略是静态策略,状态转移方程是确定的。如果他车的策略是动态策略,是会随时间改变的,那么环境不再具有马尔可夫性,没有办法把它建模成一个MDP问题。只要是在状态有变化下对应的动作变化,不能算策略变化。

[1]C. Hubmann, J. Schulz, M. Becker, D. Althoff, and C. Stiller, “Automated Driving in Uncertain Environments: Planning With Interaction and Uncertain Maneuver Prediction,” IEEE Transactions on Intelligent Vehicles, vol. 3, no. 1, pp. 5–17, Mar. 2018, doi: 10.1109/TIV.2017.2788208.
[2]K. Liu, N. Li, H. E. Tseng, I. Kolmanovsky, and A. Girard, “Interaction-Aware Trajectory Prediction and Planning for Autonomous Vehicles in Forced Merge Scenarios,” arXiv:2112.07624 [cs, eess], Dec. 2021, Accessed: Mar. 14, 2022. [Online]. Available: http://arxiv.org/abs/2112.07624















 1079
1079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









