






ParkingE2E:基于纯视觉的端到端泊车模型,从图像到规划
当前领域背景
智能驾驶涉及三大主要任务:城市驾驶、高速公路驾驶和泊车操作。自动代客泊车(AVP)和自动泊车辅助(APA)系统作为智能驾驶中的关键泊车任务,显著提升了泊车的安全性和便捷性。然而,主流的泊车方法往往基于规则,需要将整个泊车过程分解为多个阶段,如环境感知、地图构建、车位检测、定位和路径规划。由于这些复杂模型架构的精细性,它们在紧凑车位或复杂场景中更容易遇到困难。
端到端(E2E)自动驾驶算法通过将感知、预测和规划组件集成到一个统一的神经网络中进行联合优化,减少了跨模块的累积误差。将端到端算法应用于泊车场景有助于减少对人工设计特征和规则的依赖,提供全面、整体且用户友好的解决方案。
附赠自动驾驶最全的学习资料和量产经验:链接
虽然端到端自动驾驶已经显示出显著的优势,但大多数研究都集中在模拟上,而没有验证算法在现实世界中的有效性。与城市环境的复杂性和高速公路驾驶的危险性相比,泊车场景的特点是速度低、空间有限且可控性高。这些特点为在车辆中逐步部署端到端自动驾驶能力提供了一条可行的途径。我们开发了一个端到端泊车神经网络,并在现实世界的泊车场景中验证了该算法的可行性。
这项工作扩展了我们之前的工作E2E-Carla,通过提出一种基于模仿学习的端到端泊车算法,该算法已在真实环境中成功部署和评估。该算法接收车载camera捕捉的环视图像,预测未来的轨迹结果,并根据预测的路径点执行控制。一旦用户指定了一个停车位,端到端泊车网络就会与控制器协同工作,自动操控车辆进入停车位,直到完全停好。本文的主要贡献概括如下:
-
设计了一个端到端网络来执行泊车任务。该网络将环视图像转换为鸟瞰图(BEV)表示,并通过使用目标特征来查询图像特征,将其与目标停车位特征相融合。由于轨迹点的顺序性,我们采用基于Transformer解码器的自回归方法来生成轨迹点。
-
将端到端模型部署在实车上进行测试,验证了该网络模型在各种现实场景中的泊车可行性和通用性,为端到端网络的部署提供了有效解决方案。
主要方法
1)问题定义
我们使用端到端神经网络Nθ来模仿专家轨迹进行训练,定义数据集为:

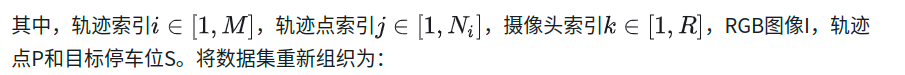


其中,Q表示预测的轨迹点的长度,R表示RGB camera的数量。
端到端网络的优化目标如下:

2)基于纯视觉的端到端规划器
如图2所示,我们开发了一个端到端神经规划器,它以RGB图像和目标停车位作为输入。所提出的神经网络包括两个主要部分:输入编码器和自回归轨迹解码器。在输入RGB图像和目标停车位后,RGB图像被转换为鸟瞰图(BEV)特征。然后,神经网络将BEV特征与目标停车位融合,并使用Transformer解码器以自回归方式生成下一个轨迹点。

编码器:在鸟瞰图(BEV)视图中对输入进行编码。BEV表示提供了车辆周围环境的从上往下的视图,使本车能够检测到停车位、障碍物和标记。同时,BEV视图在不同驾驶视角下提供了一致的视点表示,从而简化了轨迹预测的复杂性。


其中,Nt表示序列中一个标记可以编码的最大值,用于序列化轨迹点的符号表示为Ser(·)。Rx和Ry分别表示x和y方向上预测范围的最大值。
序列化后,第i条轨迹可以表示如下:

轨迹解码器:鸟瞰图(BEV)特征作为键(key)和值(value),而序列化序列则作为查询(query),以自回归的方式使用Transformer解码器生成轨迹点。在训练过程中,我们向序列点添加位置嵌入,并通过masking未知信息来实现并行化。在推理过程中,给定开始符(BOS)标记后,Transformer解码器按顺序预测后续点。然后,我们将预测的点添加到序列中,以便在下一步中重复此过程,直到遇到结束符(EOS)或达到指定数量的预测点为止。
3)横向和纵向控制

实验对比
数据集是通过车载设备收集的。为了促进全面的视觉感知和轨迹跟踪,采用环视摄像头来捕捉RGB图像。同时,集成了航位推算技术,利用传感器数据融合算法实现车辆定位的鲁棒性和准确性。实验平台的布局和所使用的传感器如图4所示。数据是在不同的停车场景中收集的,包括地下和地面停车场,如图5所示。从各种环境中收集数据有助于提升神经网络的泛化能力。

在训练过程中,使用环视摄像头图像(摄像头数量为4)作为输入,并通过停车位末端的一些点来确定目标停车位。轨迹序列点用于监督端到端的预测结果。
在推理过程中,通过RViz界面软件中的“2D-Nav-Goal”选择目标停车位。模型接收来自环视摄像头的当前图像和目标停车位,以自回归方式预测后续n个轨迹点的位置。控制器根据路径规划结果、自身姿态和反馈信号来控制车辆,将车辆停放在指定停车位。值得注意的是,目标点和预测轨迹点的坐标是在车辆坐标系中表示的,这确保了轨迹序列和鸟瞰图(BEV)特征在一致的坐标基准上进行表达。这种设计也使得整个系统独立于全局坐标系。
关于神经网络的细节,鸟瞰图(BEV)特征的大小为200x200,对应于实际空间范围x ∈ [-10m, 10m],y ∈ [-10m, 10m],分辨率为0.1米。在Transformer解码器中,轨迹序列化的最大值Nt为1200。轨迹解码器生成长度为30的预测序列,在推理过程中实现了精度和速度的最佳平衡。
使用PyTorch框架实现了我们的方法。神经网络在一个NVIDIA GeForce RTX 4090 GPU上进行训练,bs大小为16,总训练时间约为8小时,包含40,000帧。测试数据包含约5,000帧。
1)评估指标
模型轨迹评估:为了在实际场景实验之前分析模型的性能,我们设计了一些评估指标来评估模型的推理能力。
L2距离(L2 Dis.):L2距离指的是预测轨迹与真实轨迹之间的平均欧几里得距离。这一指标评估了模型推理的精确度和准确性。
Hausdorff距离(Haus. Dis.):Hausdorff距离指的是两个点集之间最小距离的最大值。这一指标从点集的角度评估了预测轨迹与真实轨迹的匹配程度。
傅里叶描述符差异(Four. Diff.):傅里叶描述符差异可以用来衡量轨迹之间的差异。较低的值表示轨迹之间的差异较小。这一指标使用一定数量的傅里叶描述符将实际轨迹和预测轨迹都表示为向量。
端到端实车评估:在实车实验中,我们使用以下指标来评估端到端的停车性能。
停车成功率(PSR):停车成功率描述了自动驾驶车辆成功停入目标停车位的概率。
无车位率(NSR):无法停入指定停车位的失败率。
停车违规率(PVR):停车违规率指的是车辆在停车时稍微超出指定停车位范围,但未阻碍或影响相邻停车位的情况。
平均位置误差(APE):平均位置误差是指当车辆成功停车时,目标停车位置与车辆实际停止位置之间的平均距离。
平均方向误差(AOE):平均方向误差是指当车辆成功停车时,目标停车方向与车辆实际停止方向之间的平均差异。
平均停车分数(APS):平均停车分数是通过综合考虑停车过程中的位置误差、方向误差和成功率来计算的。分数范围在0到100之间。
平均停车时间(APT):多次停车操作所需的平均停车时间。停车时间从启动停车模式开始计算,直到车辆成功停入指定空间,或因异常或失败而终止停车过程。
2)Quantitative Results
使用提出的端到端停车系统,在四个不同的停车场进行了闭环车辆测试,以验证我们系统的性能。结果如表I所示。

在实验中,在四个不同的停车场进行了测试。停车场I是地下停车场,而停车场II、III和IV是地面停车场。对于每个停车场,我们都进行了三种不同的实验场景。场景A是两侧无障碍物的停车。场景B是车辆左侧或右侧有障碍物的停车。场景C是附近有障碍物或墙壁的停车。对于每个实验场景,都随机选择了三个不同的停车位。在每个停车位的左右两侧各进行了大约三次停车测试。实验结果表明,提出的方法在不同场景下均实现了较高的停车成功率,展现出了强大的停车能力。

尽管最近出现了更多端到端的自动驾驶方法,但大多数都集中在解决城市驾驶场景中遇到的挑战。虽然像ParkPredict这样的方法被用于停车场景,但它们的任务与我们的有显著不同。据我们所知,目前还没有现有的有效端到端方法可以直接与我们的方法进行比较。在表II中比较了我们的方法(基于Transformer的解码器)和Transfuser(基于GRU的解码器)的结果。由于Transformer中的注意力机制,基于Transformer的解码器具有更高的预测精度。

3)消融实验
这里设计了消融实验来分析不同网络设计的影响。在网络结构方面,针对特征融合进行了消融实验,如表III所示。比较了基线(目标查询)、特征拼接和特征逐元素加法的结果。目标查询方法利用注意力和空间对齐机制来充分整合目标特征和鸟瞰图(BEV)特征。它明确限制了目标槽与鸟瞰图图像之间的空间关系,以实现最高的轨迹预测精度。

4)一些Limits
尽管提出的方法在停车任务中表现出优势,但仍存在一些局限性。首先,由于数据规模和场景多样性的限制,提出的方法对移动目标的适应性较差。通过扩展数据集,可以随后提高模型对移动物体的适应性。其次,由于训练过程依赖于专家轨迹,因此无法提供有效的负样本。此外,在停车过程中如果出现较大偏差,则没有稳健的纠正机制,最终导致停车失败。随后,可以通过构建紧密模拟现实条件的模拟器,并利用神经辐射场(NeRF)和3D高斯splatting(3DGS)技术,使用深度强化学习来训练端到端模型。最后,尽管我们的端到端停车方法已经取得了良好的结果,但与传统的基于规则的停车方法相比仍存在一定差距。然而,我们相信随着端到端技术的不断进步,这个问题将得到解决。我们期待未来端到端停车算法在复杂场景中展现出优势。
参考
[1] ParkingE2E: Camera-based End-to-end Parking Network, from Images to Planning.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









