






单目3D目标检测论文笔记-3D Bounding Box Estimation
本文是3D Bounding Box Estimation Using Deep Learning and Geometry的论文笔记及个人理解。这篇文章是单目图像3d目标检测的一个经典工作之一。其目的是从输入图片中提取3d bounding box。也是3d bounding box estimation的早期经典工作。本文的核心思路为:
-
根据2d bounding box与3d bounding box的约束关系构建了一组欠定方程组。
-
利用几何约束关系及bbox先验对该方程组的未知量自由度(freedom of degree)进行下降。
-
使用CNN对该方程组中的部分未知量进行预测,进一步下降自由度。
-
将23步骤的结果带入方程组,方程组转化为超定方程,可以进行求解。
附赠自动驾驶最全的学习资料和量产经验:链接
0. 先修知识:
3d point与2d pixel之间存在一个投影关系,即:
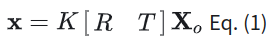
其中K是相机内参矩阵,R是旋转矩阵,T是平移。[R T]在一起就是仿射变换。大写Xo是3d空间的point,x是2d pixel。这个公式反应了图像坐标系与任意3d坐标系之间的关系。现在稍微解读下这个式子:

Xo是三维空间的点:表示为[x,y,z,1](齐次坐标)。[R T]为三维空间的旋转和平移变换,其反应了如何从当前点所属的三维空间坐标系变换到三维摄像机坐标系(坐标系变换可以可以参考线性代数中的基变换进行理解,也可以参考我上面的图,不同的三维坐标系就是基和原点的方向不同)。[R T]Xo则是将当前给定的point转化为摄像机坐标系下的point。之后我们可以根据相机模型(比如针孔相机模型)将摄像机坐标系下的三维点投影到图像坐标系下(通过矩阵K,即相机内参矩阵)。这里补充一下,相机内参矩阵其实潜在包含了两次坐标映射,一次是将三维坐标通过针孔相机模型投影到相机感光器件坐标上(这一步需要相机的焦距)。第二步是将底片坐标转化成图像坐标(需要感光器件的物理间距)。这些参数(焦距,感光器件间距)统称为相机内参。所以K[R T]Xo为Xo在图像像素上对应的坐标点。值得注意的是,如果Xo所处的三维空间坐标系是不同的,[R T]也是是不同的,如果三维空间坐标系是世界坐标系,[R T]也称为相机外参矩阵。
1. 目标坐标系:
在本论文中,Xo所属的三维空间坐标系就不是世界坐标系,而是目标坐标系(object坐标系),其可以定义为以3d bbox中心为原点,坐标轴垂直于盒子的各个平面:

object 坐标系
那么如果三维空间坐标系是object坐标系,[R T]就会变得物理含义很强了。R反应了坐标系旋转关系,因为object坐标系的每个轴都垂直于bbox的各个平面,所以bbox的旋转就可以等价于坐标系在旋转,因此R可以反应3d bbox的旋转关系。而T在坐标变换中往往反应的是原点的对应关系,所以此处可以得到T反应的就是当前bbox所属的object坐标系的原点值,也就是当前3d bbox的centre的坐标(摄像机坐标系下的坐标)。这也就是为什么原文在Eq (1)中直接假设了R, T分别是bbox旋转角度和中心坐标的原因。这里也建议结合论文理解。
2. 3D bbox与2D bbox之间存在的约束关系
根据Eq. (1)。我们很容易将3D bbox投影到2D图像上,画下来就是这个样子:

从这里我们可以看出,对于投影在图像上的3d框,我们总可以用一个2d框包在外面。如下图:

那么从这里我们就可以很清晰的看出对应关系了。3d bbox的8个角点会对外围的2d bbox起到决定性作用。那么首先,假设3d bbox的长宽高分别为dx,dy,dz,然后我们就可以在object坐标系(关于object坐标系,可以看一下0章节的后面)中将3d bbox的角点表现出来:
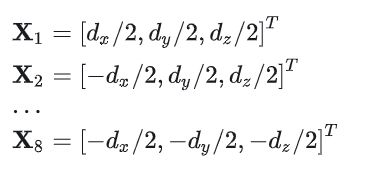
然后我们可以把这些点根据Eq (1)投影到2d 图像坐标系,那么很容易获得一系列的对应关系,原文给出了xmin与3d bbox节点坐标的对应关系:
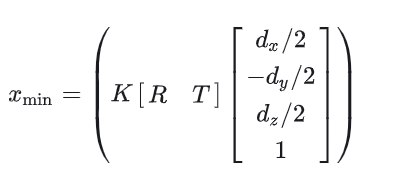
*tips: 这里之所以是最小的y对应图像空间最小的x,是取决于三维坐标系中y轴的定义。那么因为2d bbox存在四个点。所以根据xmin,ymin,xmax,ymax可以写出上述形式的式子共四个。这即为2d bbox与3d bbox构成的四个约束方程。而这组方程组中待求解参数有9个(仿射变换参数6个,bbox尺寸3个)。显然4个方程是解不出9个未知量的(欠定方程组)。那么如何解决这个问题,即为本文核心的idea。
3. 约束关系
原文在此段的描述比较详细,这里简单叙述下核心论点。
-
如何建模3d bounding box: 如果按照节点建模,过于复杂(8个点的排列组合高达上千种)。这里我觉得不重要,没人会这样建模吧= =。
-
先不考虑目标的具体位置,仅回归目标的大小,作者称这一步是顾及稳定性。
-
旋转角度先验:即汽车是在路面行驶,所以仅需考虑偏行角(yaw angle)。偏航角就是对应汽车左右拐弯的角度。另外两个角度分别对应汽车上下坡,和单边侧倾。文章认为不太需要考虑后两者。
-
预测相对角度而非绝对:即文章4.1的内容。首先文章剖析了绝对角的问题。绝对角即目标真实的旋转角度。参考下图可以发现绝对角的问题。

汽车是直线行驶,但是随着位移的改变,其局部图像上看似乎发生了旋转,这是因为相机拍摄的原因,导致相对角度发生了变化,看上去就像汽车在旋转一样。这种特性对于CNN而言极其不利,因为如果采用绝对角作为ground truth。CNN需要将看上去转角不同的图像映射到同一个答案上,这是非常不利的。所以本文采用了局部相对角作为答案,即去回归目标相对相机射线的夹角。

即图片中的theta_l。这个角度由目标绝对角度(theta)与相机射线角度 (theta_ray)共同决定。根据图像区域的关系,theta_ray是可以计算的,所以CNN只需估计相对角,我们就可以根据两个角度结合起来计算真正的目标绝对角度了。
综合这些而言,作者最后希望CNN去回归如下参数:目标相对角度,目标的尺寸。
4. 基于卷积神经网络的预测模型
网络模型没有太多新颖之处,首先基于2D检测器将2D bbox找出,将2D RoI区域输入神经网络,网络主干是三个stream,分别预测尺寸,转角与得分。

网络框架没什么值得细说的,下面说下ground truth的定义。首先本文的检测头也采用了以往2D检测中经常采用的anchor的设置,关于anchor的概念,不了解的可以先去看看faster rcnn。本文的anchor setting如下:
-
统一尺寸:即anchor尺寸仅设置一个,为所有object在数据集上的平均尺寸
-
不同的夹角:将360度转角划分成n个具备overlap的区间。
所以可以看出最终的anchor会有n个。而每一个2d roi都会根据这n个anchor计算结果,最终只保留最高得分的结果。那么接下来是ground truth的定义:
-
dimensions: 真实bbox与anchor的差值。(原文中对应公式5)
-
转角:真实bbox与anchor转角的差值。(原文对应公式4)
-
得分:利用softmax预测bbox属于哪一个转角区间,所以其本质上反应的是anchor与真实bbox的角度匹配程度。
5. 位置预测(参考原文的supplementary)
CNN预测了转角与尺寸之后,由bbox构建的4个约束中的9个位置量仅剩三个了(三个转角先被先验简化成了一个,然后被CNN预测了。尺寸三个量被CNN预测,仅剩余bbox中心位置三个量了)。那么很容易就可以根据四个方程解出三个未知量,即bbox的中心位置。
以上就是该论文的内容。作为单目图片3d检测的早期工作,内容也十分经典。主要贡献在于给出了一套合理的包围盒回归方案。给出了相对角的定义,便于回归。当然原文也遗留了一些疑问,比如不知道为什么不使用CNN直接预测bbox的位置,而要回到方程组上。这些还需要进一步的思考















 3222
3222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









