







首先也是最重要的,发放MLlib机器学习数据集,没有给数据的都是耍流氓~
- 下载地址:github mllib 数据集
- 第一列是标签,也就y
- 后面8列是x1、x2、x3...x8
- 我们的目标是寻找
y =a1*x1 + a2*x2 + ... a8*x8这样的一个线性方法 - 这里面a1、a2、...a8是我们通过这一堆 【y和x1、x2、x3...x8 】训练得来的

- 构建spark对象(这其实是一句废话)
- 读取样本数据(这里需要对数据进行处理,先按照
“,”都分割,然后按照“ ”分割,最后获得LabelPoint数据) - 建立线性回归模型,并设置训练参数(LabelPoint数据,迭代次数,梯度下降的步长,其他默认参数)
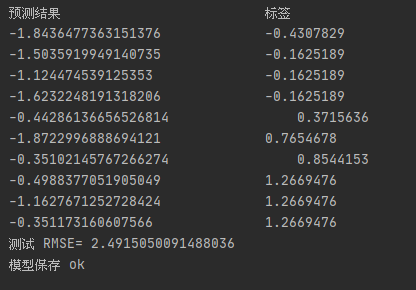
- 对样本进行测试(这里直接把训练数据,拿过来进行预测了,差距还是挺大的)
- 计算测试误差(这里采用均方根误差,是观测值与真值偏差的平方和与观测次数比值的平方根,是用来衡量观测值同真值之间的偏差)
- 模型保存(方便冷启动,不需要重新训练了)
import org.apache.log4j.{Level, Logger}
import org.apache.spark
import org.apache.spark.SparkContext._
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.mllib.util.{KMeansDataGenerator, LinearDataGenerator, LogisticRegressionDataGenerator, MLUtils}
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
//向量
import org.apache.spark.mllib.linalg.Vector
//向量集
import org.apache.spark.mllib.linalg.Vectors
//稀疏向量
import org.apache.spark.mllib.linalg.SparseVector
//稠密向量
import org.apache.spark.mllib.linalg.DenseVector
//实例
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
//矩阵
import org.apache.spark.mllib.linalg.{Matrix, Matrices}
//索引矩阵
import org.apache.spark.mllib.linalg.distributed.RowMatrix
//RDD
import org.apache.spark.rdd.RDD
object WordCount {
def main(args: Array[String]) {
// 构建Spark 对象
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("HACK-AILX10").setMaster("local")
val sc = new SparkContext(conf)
// 读取样本数据1
val datapath1 = "C:\\study\\spark\\lpsa.data"
val data1 = sc.textFile(datapath1)
val ex = data1.map{
line =>
val parts= line.split(",")
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(" ").map(_.toDouble)))
}.cache()
val numEx = ex.count()
// 新建线性回归模型,并设置训练参数
val numIter = 100
val stepSize = 1
val miniBatch = 1.0 //随机梯度下降法SGD
val model = LinearRegressionWithSGD.train(ex,numIter,stepSize,miniBatch)
// 对样本进行测试 展示前10个数据
val prediction = model.predict(ex.map(_.features))
val prediction_and_label = prediction.zip(ex.map(_.label))
val print_predict = prediction_and_label.take(10)
println("预测结果"+"\t\t\t\t\t\t\t"+"标签")
for(i <- 0 to print_predict.length -1){
println(print_predict(i)._1 + "\t\t\t\t" + print_predict(i)._2)
}
//计算测试误差
// (预测值 - 真实值)平法和,然后再除以样本数,最后开根号
val loss = prediction_and_label.map{
case (p,l) =>
val err = p -l
err * err
}.reduce(_+_)
val rmse = math.sqrt(loss/numEx)
println(s"测试 RMSE= $rmse ")
// 模型保存
val modelpath = "C:\\study\\spark\\LinearReg"
model.save(sc,modelpath)
println("模型保存 ok")
}
}
2018年研究过一段时间的Web安全机器学习,并且独立开发过基于Nginx的AI-WAF引擎,把Python和C语言混写,牛逼的一塌糊涂。而如今2020年,继续入坑Spark机器学习,希望自己在大数据安全领域,也能具备独立开发能力。加油,lets go ~
本篇完~















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











