







SparkMLlib线性回归算法案例
一、SparkMLlib线性回归模型
MLlib的线性回归模型采用随机梯度下降算法来优化目标函数。MLlib实现了
分布式的随机梯度下降算法,其分布方法是:在每次迭代中,随机抽取一定比例的样本作为当前迭代的计算样本;对计算样本中的每一个样本分别计算梯度(分布式计算每个样本的梯度);然后再通过聚合函数对样本的梯度进行累加,得到该样本的平均梯度及损失;最后根据最新的梯度及上次迭代的权重进行权重的更新。
MLlib线性回归模型方程:
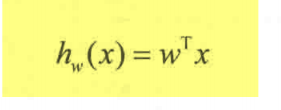
线性回归模型的损失函数是:


二、案例实现
-
数据格式说明:

-
测试数据所在位置:测试数据集
-
具体实现代码如下:
package com.spark.ml import org.apache.log4j.{Level, Logger} import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionModel, LinearRegressionWithSGD} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object LinearRegression { def main(args: Array[String]) { // 构建Spark对象 val conf = new SparkConf().setAppName("LinearRegressionWithSGD").setMaster("local[*]") val sc = new SparkContext(conf) Logger.getRootLogger.setLevel(Level.WARN) //读取样本数据 val data_path1 = "testdatas/lpsa.data" val data = sc.textFile(data_path1) val examples = data.map { line => val parts = line.split(',') LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble))) }.cache() // 触发Job实现缓存 val numExamples = examples.count() // 新建线性回归模型,并设置训练参数 val numIterations = 200 val stepSize = 1 val miniBatchFraction = 0.5 val model = LinearRegressionWithSGD.train(examples, numIterations, stepSize, miniBatchFraction) val weights = model.weights // 权重 val intercept = model.intercept // 偏置 println("权重:" + weights.toArray + "-,偏置:" + intercept) // 对样本进行测试 predictByModel(model,examples,numExamples) // 模型保存 val ModelPath = "testdatas/model/LinearRegressionModel" model.save(sc, ModelPath) } def predictByModel(model: LinearRegressionModel,examples:RDD[LabeledPoint],numExamples:Long): Unit ={ // 对样本进行测试 val prediction = model.predict(examples.map(_.features)) val predictionAndLabel = prediction.zip(examples.map(_.label)) val print_predict = predictionAndLabel.take(20) println("prediction" + "\t" + "label") for (i <- 0 to print_predict.length - 1) { println(print_predict(i)._1 + "\t" + print_predict(i)._2) } // 计算测试误差 val loss = predictionAndLabel.map { case (p, l) => val err = p - l err * err }.reduce(_ + _) val rmse = math.sqrt(loss / numExamples) println(s"Test RMSE = $rmse.") } }注意:可不断调整模型参数以便于得到最优的模型
















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











