







 本文详细介绍了Spark MLlib中的线性回归算法,包括线性回归的基础理论、梯度下降算法(批量梯度下降与随机梯度下降)、最小二乘法,以及Spark Mllib中LinearRegressionWithSGD的源码分析,展示了如何在实践中使用线性回归模型进行训练和预测,最后提供了一个完整的实例来说明线性回归模型的应用。
本文详细介绍了Spark MLlib中的线性回归算法,包括线性回归的基础理论、梯度下降算法(批量梯度下降与随机梯度下降)、最小二乘法,以及Spark Mllib中LinearRegressionWithSGD的源码分析,展示了如何在实践中使用线性回归模型进行训练和预测,最后提供了一个完整的实例来说明线性回归模型的应用。
1、Spark MLlib Linear Regression线性回归算法
1.1 线性回归算法
1.1.1 基础理论
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
下面我们来举例何为一元线性回归分析,为某地区的房屋面积(feet)、房间数、价格($)的一个数据集,在该数据集中,只有自变量面积(feet)、房间数,和一个因变量价格($),
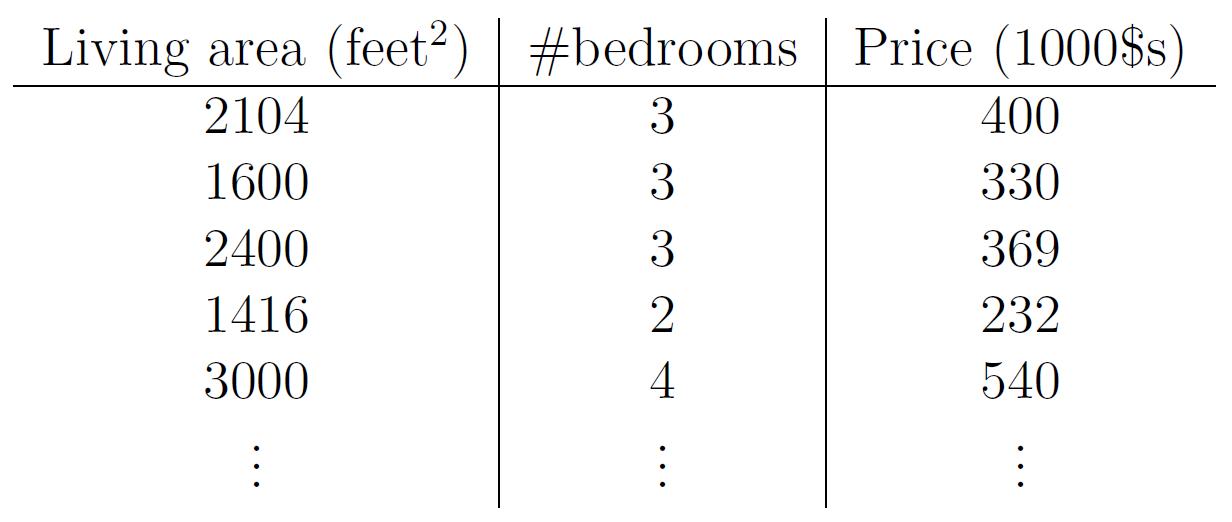
分析得到的线性方程应如下所示:
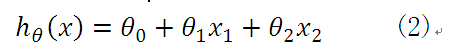
因此,无论是一元线性方程还是多元线性方程,可统一写成如下的格式:
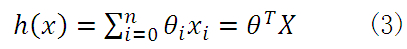
上式中x0=1,而求线性方程则演变成了求方程的参数ΘT。
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以有前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算,这样就可以表达特征与结果之间的非线性关系。
1.1.2 梯度下降算法
为了得到目标线性方程,我们只需确定公式(3)中的ΘT,同时为了确定所选定的的ΘT效果好坏,通常情况下,我们使用一个损失函数(loss function)或者说是错误函数(error function)来评估h(x)函数的好坏。该错误函数如公式(4)所示。前面乘上的1/2是为了在求导的时候,这个系数就不见了。
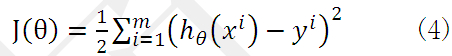
如何调整ΘT以使得J(Θ)取得最小值有很多方法,其中有完全用数学描述的最小二乘法(min square)和梯度下降法。
1.1.3 批量梯度下降算法
由之前所述,求ΘT的问题演变成了求J(Θ)的极小值问题,这里使用梯度下降法。而梯度下降法中的梯度方向由J(Θ)对Θ的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。
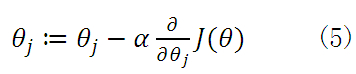
公式(5)中α为学习速率,当α过大时,有可能越过最小值,而α当过小时,容易造成迭代次数较多,收敛速度较慢。假如数据集中只有一条样本,那么样本数量,所以公式(5)中
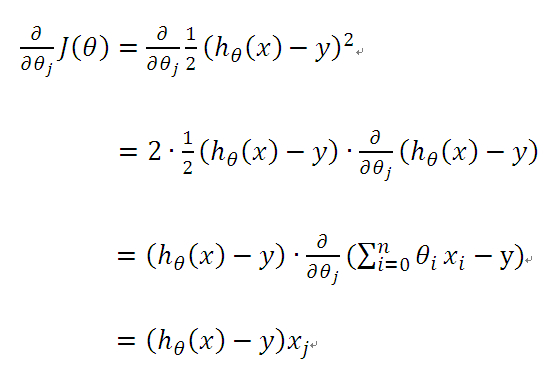
所以公式(5)就演变成:
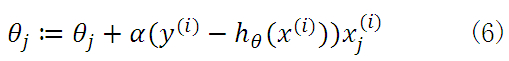
当样本数量m不为1时,将公式(5)中
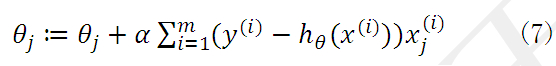
初始时ΘT可设为0,然后迭代使用公式(7)计算ΘT中的每个参数,直至收敛为止。由于每次迭代计算ΘT时,都使用了整个样本集,因此我们称该梯度下降算法为批量梯度下降算法(batch gradient descent)。
1.1.4 随机梯度下降算法
当样本集数据量m很大时,批量梯度下降算法每迭代一次的复杂度为O(mn),复杂度很高。因此,为了减少复杂度,当m很大时,我们更多时候使用随机梯度下降算法(stochastic gradient descent),算法如下所示:
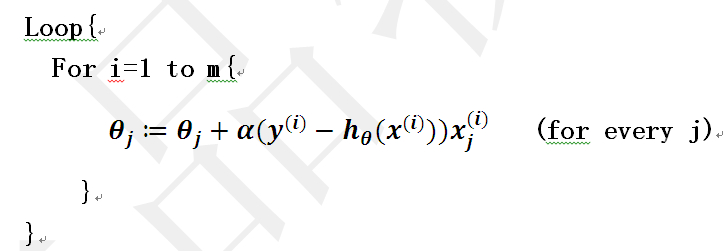
即每读取一条样本,就迭代对ΘT进行更新,然后判断其是否收敛,若没收敛,则继续读取样本进行处理,如果所有样本都读取完毕了,则循环重新从头开始读取样本进行处理。
这样迭代一次的算法复杂度为O(n)。对于大数据集,很有可能只需读取一小部分数据,函数J(Θ)就收敛了。比如样本集数据量为100万,有可能读取几千条或几万条时,函数就达到了收敛值。所以当数据量很大时,更倾向于选择随机梯度下降算法。
但是,相较于批量梯度下降算法而言,随机梯度下降算法使得J(Θ)趋近于最小值的速度更快,但是有可能造成永远不可能收敛于最小值,有可能一直会在最小值周围震荡,但是实践中,大部分值都能够接近于最小值,效果也都还不错。
1.1.4 最小二乘法
将训练特征表示为X矩阵,结果表示成y向量,仍然是线性回归模型,误差函数不变。那么θ可以直接由下面公式得出
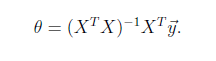
但此方法要求X是列满秩的,而且求矩阵的逆比较慢。
1.2 Spark Mllib Linear Regression源码分析
1.2.1 LinearRegressionWithSGD
线性回归算法的train方法,由LinearRegressionWithSGD类的object定义了train函数。
package org.apache.spark.mllib.regression
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
miniBatchFraction: Double): LinearRegressionModel = {
new LinearRegressionWithSGD(stepSize, numIterations, miniBatchFraction).run(input)
}
Input为输入样本,numIterations为迭代次数,stepSize为步长,miniBatchFraction为迭代因子。
创建一个LinearRegressionWithSGD对象,初始化梯度下降算法。
Run方法来自于继承父类GeneralizedLinearAlgorithm,实现方法如下。
1.2.2 GeneralizedLinearAlgorithm
LinearRegressionWithSGD中run方法的实现。
package org.apache.spark.mllib.regression
/**
* Run the algorithm with the configured parameters on an input RDD
* of LabeledPoint entries starting from the initial weights provided.
*/
def run(input: RDD[LabeledPoint], initialWeights: Vector): M = {
// 特征维度赋值。
if (numFeatures < 0) {
numFeatures = input.map(_.features.size).first()
}
// 输入样本数据检测。
if (input.getStorageLevel == StorageLevel.NONE) {
logWarning("The input data is not directly cached, which may hurt performance if its"
+ " parent RDDs are also uncached.")
}
// 输入样本数据检测。
// Check the data properties before running the optimizer
if (validateData && !validators.forall(func => func(input))) {
thrownew SparkException("Input validation failed.")
}
val scaler = if (useFeatureScaling) {
new StandardScaler(withStd = true, withMean = false).fit(input.map(_.features))
} else {
null
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









