







文章目录
一、线性回归
1、一元线性回归
一元线性回归分析:找到一条直线能够最大程度上拟合二维空间中出现的点。


2、多元线性回归
多元线性回归分析:如果自变量多于1个,那么就需要求一个多元函数去拟合空间中的点。
二元线性回归:
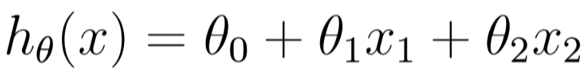
n元线性回归:
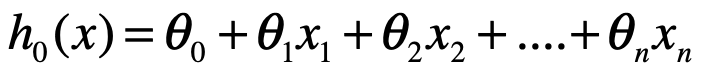
变化为:
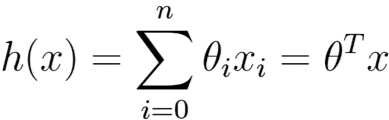
1、损失函数
如何利用一个规则或机制帮助我们评估求得的参数θ,并且使得线性模型效果最佳呢?直观地认为,如果求得参数θ线性求和后,得到的结果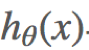 与真实值yy之差越小越好。
与真实值yy之差越小越好。
这时我们需要映入一个函数来衡量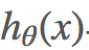 表示真实值y好坏的程度,该函数称为损失函数(loss function,也称为错误函数)。数学表示如下:
表示真实值y好坏的程度,该函数称为损失函数(loss function,也称为错误函数)。数学表示如下:

这个损失函数用的是 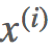 的预测值
的预测值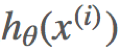 与真实值
与真实值 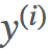 之差的平方和。如果不考虑诸如过拟合等其他问题,这个就是我们需要优化的目标函数。
之差的平方和。如果不考虑诸如过拟合等其他问题,这个就是我们需要优化的目标函数。
2、目标函数的概率解释
<1>中心极限定理
中心极限定理本事就是研究独立随机变量和的极限分布是正态分布的问题。
公式如下:
设n个随机变量X1,X2,···,Xn相互独立,均具有相同的数学期望与方差,即 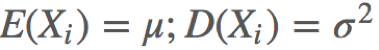 ,令
,令 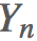 为随机变量之和,有
为随机变量之和,有
称随机变量Zn为n个随机变量X1、X2、X3、…、Xn的规范和。
定义为:
设从均值为μ、方差为σ2(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布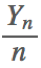 近似服从于均值为μ、方差为σ2的正态分布。
近似服从于均值为μ、方差为σ2的正态分布。
<2>高斯分布
假设给定一个输入样例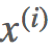 根据公式得到预测值
根据公式得到预测值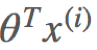 与真实值
与真实值 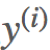 之间存在误差,即为
之间存在误差,即为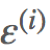 。那么,它们之间的关系表示如下:
。那么,它们之间的关系表示如下:
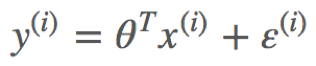
而这里假设误差 服从标准高斯分布是合理的
<3>极大似然估计与损失函数极小化等价
根据上述公式估计得到一条样本的结果概率,模型的最终目标是希望在全部样本上预测最准,也就是概率积最大,这个概率积就是似然函数。优化的目标函数即为似然函数,表示如下:
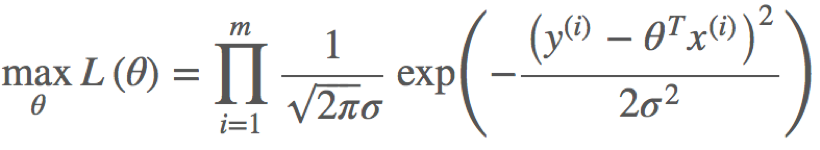
对L(x)取对数,可得对数似然函数:
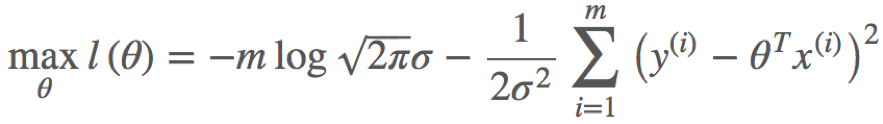
由于n,σ都为常数,因此上式等价于
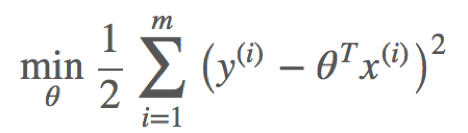
三、最小二乘法
通过观察或者求二阶导数可知,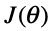 是一个凸函数。
是一个凸函数。

将m个n维样本组成矩阵:

目标函数的矩阵形式为:
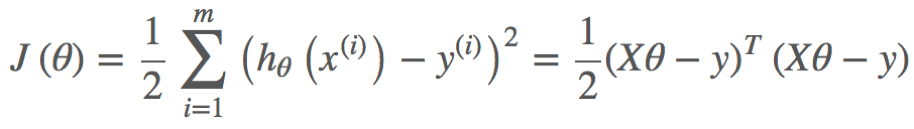
凸函数有最小值,即导数为0:

令导数为0,可以求得驻点:
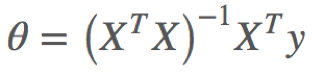
如果XTX不可逆,那么不可使用
在实际开发中,若XTX阶数过高的话,仍然需要使用梯度下降方式计算求解。
由于最小二乘法在求解的时候存在局限性,这时需要使用梯度下降来近似求解。
四、梯度下降
梯度下降算法如下:
- 初始化θ(随机初始化)
- 迭代,新的θ能够使得J(θ)更小
- 如果J(θ)能够继续减少且不收敛,则返回2
- α成为学习率
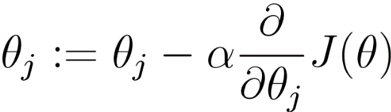
收敛条件:J(θ)不再变化,或者是变化小于某个阈值。
1、批量梯度下降
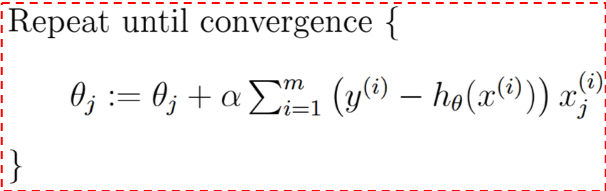
2、随机梯度下降

下降的梯度即为导数的负数:

直至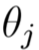 收敛:
收敛: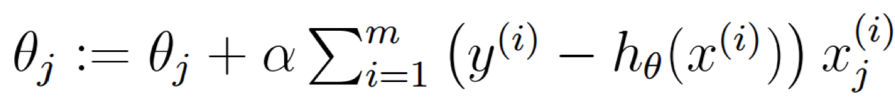
我们也可以使用代码自己实现一下梯度下降,具体代码如下:
package linear_regression
import scala.collection.mutable
object tidu {
//定义一个存放数据的集合
val data = mutable.HashMap[Int,Int]()
def getData():mutable.HashMap[Int,Int]={
for (i <- 1 to 50){
data += (i -> (12 * i))
}
data
}
var θ: Double = 0 //第一步假设θ为0
val α : Double = 0.1 //设置步进系数
//定义损失函数
def sgd(x:Double,y:Double)={
θ = θ - α * ((θ * x) - y)
}
def main(args: Array[String]): Unit = {
val dataSource = getData()
dataSource.foreach( myMap =>{
sgd(myMap._1,myMap._2)
})
println("最终结果" + θ)
}
}
五、线性回归的使用
Spark MLlib 实现线性回归:
package linear_regression
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
import org.apache.spark.{SparkConf, SparkContext}
//65|7,400
//90|5,1300
//100|4,1100
//110|3,1300
//60|9,300
//100|5,1000
//75|7,600
//80|6,1200
//70|6,500
//50|8,30
object LinearRegression1 {
def main(args: Array[String]): Unit = {
//获取配置信息
val sparkConf = new SparkConf().setAppName("LinearRegression2").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//读取数据
val data = sc.textFile("/Users/xiaotongxin/IdeaProjects/spark2/sparkmllib/mllibvector/src/main/resources/dataset")
//处理数据,需要LabeledPoint类型的数据
val parsedData = data.map{ line =>
val part = line.split("|")
LabeledPoint(part(0).toDouble,Vectors.dense(part(1).split(",").map(_.toDouble)))
}
//建立模型
val module = LinearRegressionWithSGD.train(parsedData,2,0.1)
//预测模型,均方误差
val valuesAndLabel = parsedData.map{ point =>
val prediction = module.predict(point.features)
(point.label,prediction)
}
valuesAndLabel.foreach(println)
val Mse = valuesAndLabel.map{ case (v,p) => math.pow((v-p),2)}.mean()
println(Mse)
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









