







目录
2.贝叶斯个性化排序(Bayesian Personalized Ranking, BPR)
1.“排序算法”分类
全量召回得到粗排结果,再使用更精准但是性能慢的算法进行排序;相当于算法的融合,得到更佳的推荐结果。初期你想直接用协同过滤的结果做推荐也不是不可以,但要考虑实时推荐的性能和优化推荐结果。

2.贝叶斯个性化排序(Bayesian Personalized Ranking, BPR)
2.1.应用场景
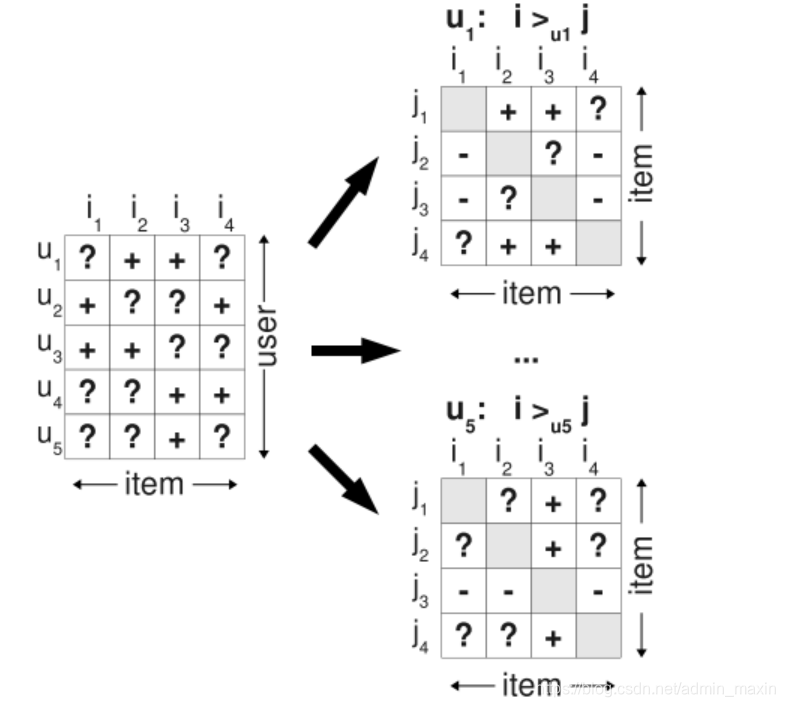
传统的近邻协同过滤推荐算法的核心思想是基于现有“用户-商品评分矩阵”计算用户之间的相似度,并通过评分预测公式对整个矩阵中的缺失评分进行预测,并依据评分的高低对用户进行推荐,实践证明使用起来也很有效。但是,在千万级别的商品中用户感兴趣的商品仅仅是个位数,通过对评分矩阵中的全部缺失评分进行预测的方式耗时耗力(笨方法)。因此,排序推荐更关心的是对于用户来说哪些极少数商品在用户心中有更高的优先级,也就是排序更靠前。
【现有基于隐式反馈数据的排序推荐算法问题】
BPR是基于用户的隐式反馈(传统处理方法:产生交互行为的记为1,未产生交互行为的记为0,并将交互行为矩阵作输入给模型进行训练。于是产生的问题是,我们希望模型在以后预测的缺失值,在训练时却都被认为是负类数据),为用户提供物品的推荐,并且是直接对排序进行优化
2.2.BPR建模思路
2.2.1.【符号说明】
<u,i,j>:用户u在同时有物品i和j的情况下点击了i,也即:对用户u来说,i的排序要比j靠前
m:用户反馈<u,i,j>的个数,也即训练样本的个数
:表示用户u的偏好,相比于商品j,用户u更加偏好于商品i(满足:完整性、反对称性和传递性),因此便可为每个用户构造大小为I×I的偏好矩阵
:所有用户偏好对构成的训练集(也可直接表示为D)
:表示BRP算法最终得到的预测排序矩阵
和
:分别表示分解后期望得到的用户矩阵和商品矩阵(k为自定义大小且远小于用户或商品的量级,矩阵的理解同SVD)
2.2.2.【BPR算法前提假设】
①每个用户之间的偏好行为相互独立,即用户u在商品i和j之间的偏好和其他用户无关
②同一用户对不同物品的偏序相互独立,也就是用户u在商品i和j之间的偏好和其他的商品无关
2.2.3.【BPR算法的目标函数的形式化定义】
总体目标函数如下:
由于BPR是基于用户维度的,所以对于任意一个用户u,对应的任意一个物品i有:
其中,
表示W矩阵中对应用户行的第f个元素,
表示H矩阵中对应行的第f个元素
2.3.BPR优化目标函数
2.3.1.【总体目标函数求解】
由贝叶斯定理可知:
(1).要解决的问题:求解最优参数W和H(表示为θ) → 事件 A
(2).已知条件:用户u对应的所有商品的全序关系
→ 事件 B
故优化目标函数可表示为:
由于假设了用户的偏好排序和其他用户无关,那么对于任意一个用户u,
对所有的物品一样,所以有“后验概率∝(正比于)似然概率×先验概率”:
综上优化目标可表示为“似然概率”和“先验概率”两部分。
2.3.2.【第一部分:似然概率求解】
由“BPR算法的前提假设”可得:
基于符号说明中所介绍的“用户偏好的性质(完整性+反对称性)”上式可简化为:
【一】 上式中
通过sigmoid函数表示,原因主要有两个:
① sigmoid函数满足“BPR算法的用户偏好性质” → 单调连续函数
② 方便后续进行优化计算,也就是方便后续求导
【二】上式中
通过
表示(其中
和
分别表示
中对应位置的值,也即“BPR算法的目标函数的形式化定义”中的最后一个公式),原因:
① 当
,
;反之,
综上,第一部分的优化结果最终表示为:
2.3.3.【第二部分: 先验概率求解】
先验概率
表示我们在不知道B事件(用户的偏好排序)的前提下,对A事件(θ)概率的主观判断。故原作者大胆使用了贝叶斯假设,即这个概率分布符合正态分布,且对应的均值是0,协方差矩阵是
,即:
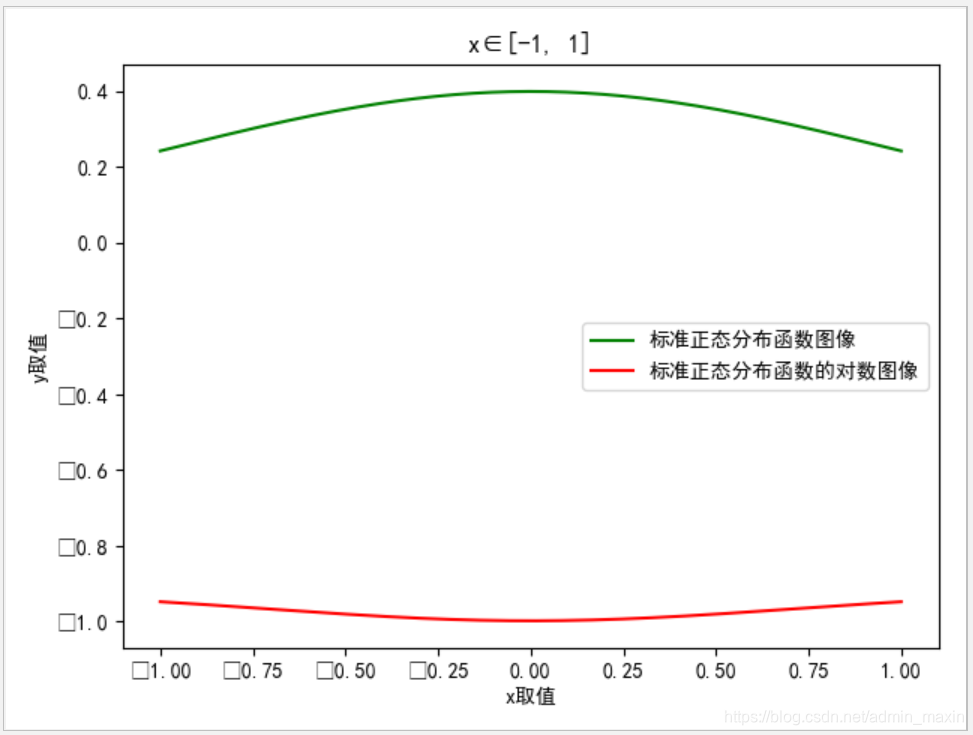
而对于上式中假设的多维正态分布,其取对数之后与
成正比(例如:下图为标准正态分布f(x)和取对数后的函数log2(f(x))图像),故上式可进一步转化为:
2.3.4.【综上:最终的优化目标函数形式】
上式可通过“随机梯度下降法”或者“牛顿法”等优化算法对其进行优化。以“随机梯度下降算法”为例,θ的导数可表示为:
由于:
故可得:
因此,对应的各模型参数的迭代公式可表示为(其中α表示学习速率):
接下来则可以迭代更新各个参数了。
2.4.BPR算法流程
输入:训练集D三元组<u,i,j,label>,学习速率=α, 正则化参数=λ,分解矩阵维度=k
输出:模型参数,矩阵W,H
①. 随机初始化矩阵W,H
②. 迭代更新模型参数
③. 如果W,HW,H收敛,则算法结束,输出W,H,否则回到步骤②
④. 当得到最优的W,H后,就可以计算出每一个用户u对应的任意一个商品的排序分:
,最终选择排序
分最高的若干商品输出。
2.5.总结
BPR是基于矩阵分解的一种排序算法,但是和funkSVD之类的算法比,其不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。因此在迭代优化的思路上完全不同。同时对于训练集的要求也是不一样的,funkSVD只需要用户物品对应评分数据二元组做训练集,而BPR则需要用户对商品的喜好排序三元组做训练集。
3.BPR程序(Python-TensorFlow)
参考博客:https://www.cnblogs.com/pinard/p/9163481.html
以下代码为TensorFlow 2.0版本的兼容代码,并进行了部分修改
# ! /usr/bin/env python
# coding:utf-8
# python interpreter:3.6.2
# author: admin_maxin
# tensorflow 2.0 版本已经在操作上进行了一些变化,因此,原有的程序也需要进行一些调整
import pandas as pd
import numpy as np
import random
from collections import defaultdict
import tensorflow as tfw
import tensorflow.compat.v1 as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 解决Tensorflow不支持AVX2指令集问题
tf.disable_v2_behavior() # 关闭动态图模式
def load_data(data_path):
"""
加载数据
:param data_path:u.data文件的路径
:return:{用户编号:{评价过的商品编号}}
"""
user_ratings = defaultdict(set) # 集合:无序不重复元素序列
max_u_id = -1 # 记录用户最大编号
max_i_id = -1 # 记录电影最大编号
# 加载943个用户对1682部电影的100000个评分(1-5分)
with open(data_path, "r") as f:
for line in f.readlines():
u, i, rate, sku = line.split("\t")
u = int(u)
i = int(i)
user_ratings[u].add(i)
max_u_id = max(u, max_u_id)
max_i_id = max(i, max_i_id)
return max_u_id, max_i_id, user_ratings
def generate_test(user_ratings):
"""
挑选生成测试集三元组的数据:每个用户选一个交互电影
:param user_ratings:
:return:
"""
user_test = dict()
for u, i_set in user_ratings.items():
# random.sample(样本,抽取元素个数) --> 生成list
# 此处np.random.sample()函数并不具备此功能
user_test[u] = random.sample(user_ratings[u], 1)[0]
return user_test
# sklearn.model_selection.train_test_split在此处不适用:无法保证是否保留有每个用户的训练数据
def generate_train_batch(user_ratings, user_ratings_test, item_count, batch_size=512):
"""
生成TensorFlow迭代用的若干批训练集
:param user_ratings:
:param user_ratings_test:
:param item_count:
:param batch_size: 待生成三元组<u,i,j>的个数
:return:
"""
t = []
for b in range(batch_size):
u = random.sample(user_ratings.keys(), 1)[0]
# 任选一部用户偏好的电影
i = random.sample(user_ratings[u], 1)[0]
while i == user_ratings_test[u]:
i = random.sample(user_ratings[u], 1)[0]
# 任选一部用户的非偏好电影
j = random.randint(1, item_count)
while j in user_ratings[u]:
j = random.randint(1, item_count)
t.append([u, i, j])
return np.asarray(t)
def generate_test_batch(user_ratings, user_ratings_test, item_count):
"""
生成TensorFlow用的测试集[yield所在函数变成了生成器]
:param user_ratings:
:param user_ratings_test:
:param item_count:
:return: 逐一返回单个用户的三元组
"""
for u in user_ratings.keys():
t = []
i = user_ratings_test[u]
for j in range(1, item_count+1):
if not (j in user_ratings[u]):
t.append([u, i, j])
yield np.asarray(t)
def bpr_mf(user_count, item_count, hidden_dim):
"""
BPR算法模型
:param user_count: 用户数
:param item_count: 电影数
:param hidden_dim: 矩阵分解的隐含维度k
:return:
"""
u = tf.placeholder(tf.int32, [None])
i = tf.placeholder(tf.int32, [None])
j = tf.placeholder(tf.int32, [None])
# 指定会话运行的具体设备
with tf.device("/cpu:0"):
# 定义用户矩阵W和电影矩阵H[trainable=True:可训练变量]
user_embedding_w = tf.get_variable("user_embedding_w", [user_count+1, hidden_dim], initializer=tfw.random_normal_initializer(0, 0.1))
item_embedding_w = tf.get_variable("item_embedding_w", [item_count+1, hidden_dim], initializer=tfw.random_normal_initializer(0, 0.1))
# 定义用户列、电影列
u_emb = tf.nn.embedding_lookup(user_embedding_w, u)
i_emb = tf.nn.embedding_lookup(item_embedding_w, i)
j_emb = tf.nn.embedding_lookup(item_embedding_w, j)
# 定义目标函数
# tf.reduce_sum():按行求和且保留原来张量的形状
x = tf.reduce_sum(tf.multiply(u_emb, (i_emb - j_emb)), 1)
# 定义2阶正则化项
l2_norm = tf.add_n([
tf.reduce_sum(tf.multiply(u_emb, u_emb)),
tf.reduce_sum(tf.multiply(i_emb, i_emb)),
tf.reduce_sum(tf.multiply(j_emb, j_emb)),
])
# 平均AUC=平均值(测试集中每个用户的AUC)
mf_auc = tf.reduce_mean(tf.cast(x > 0, tf.float32))
# 定义损失函数
regulation_rate = 0.0001
bpr_loss = - tf.reduce_mean(tf.log(tf.sigmoid(x))) + regulation_rate*l2_norm
# 定义优化目标
train_operation = tf.train.GradientDescentOptimizer(0.001).minimize(bpr_loss)
return u, i, j, mf_auc, bpr_loss, train_operation
if "__main__" == __name__:
# 2.1.0
print(tf.__version__)
data_path = "data/u.data"
user_count, item_count, user_ratings = load_data(data_path)
# print(user_count, item_count, user_ratings)
user_ratings_test = generate_test(user_ratings)
# print(user_ratings_test)
# train_data = generate_train_batch(user_ratings, user_ratings_test, item_count, batch_size=512)
# print(train_data)
# test_data = generate_test_batch(user_ratings, user_ratings_test, item_count)
# print(test_data)
# ==模型运作流程
with tf.Graph().as_default(), tf.Session() as sess:
u, i, j, mf_auc, bpr_loss, train_op = bpr_mf(user_count, item_count, 20)
sess.run(tf.global_variables_initializer())
# ==模型训练
for epoch in range(1, 3):
# 记录单次迭代的损失值
_batch_bpr_loss = 0
for k in range(1, 100):
uij = generate_train_batch(user_ratings, user_ratings_test, item_count, 512)
_loss, _op = sess.run([bpr_loss, train_op], feed_dict={u: uij[:, 0], i: uij[:, 1], j: uij[:, 2]})
_batch_bpr_loss += _loss
print("第{}次迭代,训练集损失值:{}".format(str(epoch), str(_batch_bpr_loss / k)))
# ==模型测试
auc_sum = 0
test_bpr_sum_loss = 0
count = 0
# 每次只返回一个用户的auc
for t_uij in generate_test_batch(user_ratings, user_ratings_test, item_count):
_auc, _test_bpr_loss = sess.run([mf_auc, bpr_loss], feed_dict={u: t_uij[:, 0], i: t_uij[:, 1], j: t_uij[:, 2]})
count += 1
auc_sum += _auc
test_bpr_sum_loss += _test_bpr_loss
print("第{}个用户的准确性:{} ---- 损失值:{}".format(str(count), str(_auc), str(_test_bpr_loss)))
print("test_loss: ", test_bpr_sum_loss/user_count, "test_auc: ", auc_sum / user_count)
# 查看可训练变量W和H
variable_names = [v.name for v in tf.trainable_variables()]
values = sess.run(variable_names)
for k, v in zip(variable_names, values):
print("Variable:{}".format(k))
print("Shape:{}".format(v.shape))
print("{}值:{}".format(k, v))
# 生成推荐列表
# values[0]:<class 'tuple'>: (944, 20)
# values[0][0]:<class 'tuple'>: (20,)
# u1_dim_w: shape=(1, 20)
# values[1]: shape=(1683, 20)
# u1_all: shape=(1, 1683)
user_recommendation_list = defaultdict(list)
for i in range(user_count):
u1_dim_w = tfw.expand_dims(values[0][i], 0)
u1_all = tf.matmul(u1_dim_w, values[1], transpose_b=True)
result_1 = sess.run(u1_all) # 生成评分向量
p = np.squeeze(result_1) # 删除result_1中为一维的项
p[np.argsort(p)[:-5]] = 0 # 将除评分最大的后5项之外的评分设置为0
for index in range(len(p)):
if p[index] != 0:
user_recommendation_list[i].append(index)
user_recommendation_list[i].append(p[index])
print("用户商品推荐列表:", user_recommendation_list)


















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











