







1.简介
Canopy聚类算法是一个将对象分组到类的简单、快速、精确地方法。每个对象用多维特征空间里的一个点来表示。这个算法使用一个快速近似距离度量和两个距离阈值T1 > T2 处理。
Canopy聚类很少单独使用, 一般是作为k-means前不知道要指定k为何值的时候,用Canopy聚类来判断k的取值
2.算法步骤
输入:所有点的集合D, 超参数:T1 , T2 , 且 T1 > T2
输出:聚类好的集合

注意
- 当T1过大时,会使许多点属于多个Canopy,可能会造成各个簇的中心点间距离较近,各簇间区别不明显;
- 当T2过大时,增加强标记数据点的数量,会减少簇个个数;
- T2过小,会增加簇的个数,同时增加计算时间;
一幅图说明算法:
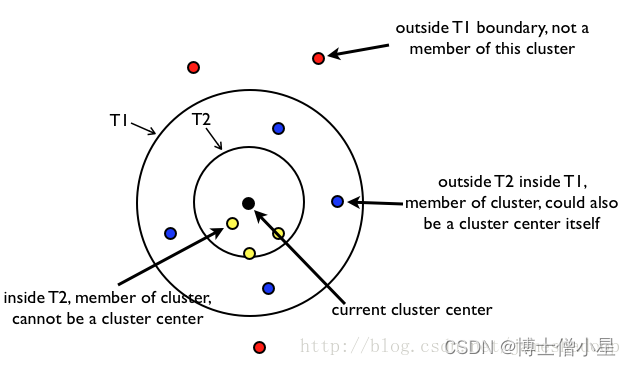
内圈的一定属于该类, 外圈的一定不属于该类,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











