









 本文探讨了如何将卢西亚诺·弗洛里迪的信息和信息伦理哲学应用于信息行为和信息素养模型,以全面考虑数字信息环境中的隐私问题。文章强调了隐私作为信息摩擦的函数,并展示了如何在不同模型中整合隐私概念,如ISCM过程模型和信息素养模型,以增强模型的全面性。
本文探讨了如何将卢西亚诺·弗洛里迪的信息和信息伦理哲学应用于信息行为和信息素养模型,以全面考虑数字信息环境中的隐私问题。文章强调了隐私作为信息摩擦的函数,并展示了如何在不同模型中整合隐私概念,如ISCM过程模型和信息素养模型,以增强模型的全面性。
原文题目
“The dearest of our possessions”: Applying Floridi's information privacy concept in models of information behavior and information literacy
摘要
这篇概念性文章根据卢西亚诺·弗洛里迪 (Luciano Floridi) 的信息和信息伦理哲学,论证了数字信息环境中隐私方法的价值。
这种方法可用于修改信息行为和信息素养的模型,使它们更全面,更有效地覆盖信息领域的隐私问题。
目录
1.引言
2.弗洛里迪信息隐私方法
3.佛罗里迪隐私模型
4.信息行为模型的隐私
5.弗洛里迪信息行为过程模型中的隐私
6.弗洛里迪信息行为解释者范式中的隐私
7.信息素养模型
8.结论
1.引言
长期以来,保护个人隐私一直被认为是一个重要问题,卢西亚诺·弗洛里迪(Luciano Floridi)将隐私保护表示为“我们超历史时代的决定性问题之一”。
随着数字信息的出现,信息隐私问题被认为变得越来越重要,数字信息的技术提供积极的影响的同时,也提供了侵犯隐私的机会。
为了保护隐私,同时允许开放和有效地访问信息与数据,需要了解隐私的性质,这是一个复杂且有争议的概念,而且随着数字技术成为常态,其性质也在发生变化。
对此,该文章将 Luciano Floridi 的信息和信息伦理哲学中的隐私概念应用于信息行为和信息素养模型。
2.弗洛里迪信息隐私方法
基于弗洛里迪的隐私方法,本文使用六个子标题:隐私的概念;一个总体的哲学和伦理体系;信息本体;隐私类型;数字技术的影响;信息摩擦。
2.1 隐私的概念
“‘隐私’一词在日常语言以及哲学、政治和法律讨论中经常使用,但没有术语含义的单一定义或分析。
此外,最近的社会技术发展增加了信息、物理性和表达之间的内在复杂性,因此不断改变隐私的含义。
2.2 一个总体的哲学和伦理体系
弗洛里迪已经发展了一种全面的哲学方法来处理所有表现形式的信息,包括信息伦理,他的信息哲学具有很高的影响力,但也受到了评论和批评。
本文阐述这种数字隐私方法的主要和独特方面。表 1 中总结为一个包含八个元素的简单大纲概念模型
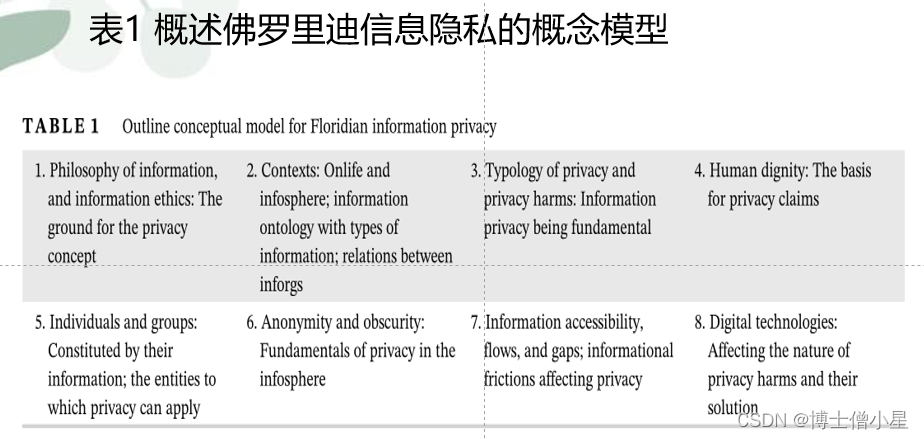
该模型中的隐私问题符合并借鉴了更广泛的信息伦理(模型中的元素 1:信息哲学和信息伦理:隐私概念的基础)。
论证佛罗理迪信息哲学和伦理的合理性:
Burk (2008) 和 Stahl (2008) 是最先断言隐私考虑需要设置在广泛而稳健的道德框架中的人之一.Buschman(2016)对任何基于伦理的隐私模型是否会导致对狭隘的个人隐私伤害的关注表示担忧。但弗洛里达隐私的两个特点--它针对数字环境的设计(Buschman认为这是基于道德的隐私的普遍问题),以及它对群体和个人的强调--可以免除Buschman的担忧
Stahl 断言,弗洛里迪的伦理学没有处理那些相关的但不是信息性的问题;他以考虑信息和通信技术使用中的性别问题为例说明了这一点。
弗洛里迪(2008,2013)的回应是,他的信息伦理和相关的隐私表述是普遍的,因为它们允许在正确的抽象水平下从信息角度看待所有这些问题,而且它们适合被扩展以涵盖不同的含义和背景;该系统是完整和封闭的。
2.3 信息本体
在这种方法的核心,大纲模型的元素2(背景:onlife和信息圈;具有信息类型的信息本体;信息之间的关系)是信息的本体,这意味着所有信息实体,包括但不限于人,都应该得到尊重和保护,这给出了隐私的基本原理。这将隐私的概念从个人转移到信息环境(Floridi的信息圈),其中个人及其信息是参与者。
2.4 隐私计算
Solove (2005) 给出了隐私危害的详细分类; Tavani (2008b) 区分了身体隐私、决策隐私、心理隐私和信息隐私,并指出这些隐私可能重叠,Floridi (2008, 2013) 的模型给出了一个通用框架,可以在其中分析和情境化所有特定形式的隐私,因为这些隐私形式本质上必然是信息性的。
基于所有隐私本质上都是信息性的中心思想的同时,我们可能包括其他类型的隐私,将它们视为各种信息隐私;模型中元素 3(隐私和隐私危害的类型学:信息隐私是根本)。
该特性使Floridi的隐私框架能够有效地弥合最常采用的两种数字隐私方法,Mai(2019)称之为“控制方法”和“访问方法”。
控制方法:将隐私与个人控制有关自己的信息的能力联系起来,并对谁可以访问它施加限制;一种对我们自己数字信息的产权(Tavani,2008b,Moore(2010)。
访问方法:将隐私与在各个方面控制我们信息的想法联系起来,包括但不仅限于授予对它的访问权限。
这两种看似不同的数字隐私观点可能被归入一个更大的一致框架中,这是采用Floridi对隐私理解的进一步论据。
Floridi认为保护隐私应被确定为对个人身份的保护,而对信息隐私的破坏则是对个人身份和自我发展的侵犯。
保护隐私应直接基于对人类尊严的保护,而不是次要考虑,如财产权、言论自由权或隐私权本身。这反映在模型的元素4中(人类尊严:隐私主张的基础)。
Floridi的隐私方法认为,群体隐私与个人隐私一样重要(Floridi,2017),反映在大纲模型的元素5(个人和群体:由他们的信息构成;隐私可以适用的实体)中。
2.5 数字技术的影响
数字技术既可以保护也可以破坏隐私,这些可以通过改变两个因素来改变人们对隐私的理解:
匿名性:由于收集和处理个人数据的困难而无法获得个人数据;
模糊性:个人信息已被收集并且原则上是可用的,但需要过多的时间和精力才能找到。
这些因素是Floridi方法(大纲模型中的元素 6:匿名和模糊:信息领域的隐私基础)所固有的,它是为数字信息领域而设计的。
2.6 信息摩擦
该模型认识到“隐私是信息圈中信息摩擦的函数(模型中的元素 7:信息的可获得性、流动和差距;影响隐私的信息摩擦)。任何增加或减少摩擦的因素也会影响隐私。摩擦越小,可以实施的信息隐私程度就越低。
数字技术通过改变信息摩擦的性质,既可以加强也可以削弱信息隐私,正如模型中的元素 8(数字技术:影响隐私伤害的本质及其解决方案) 所包含的那样。
2.7 Floridi的隐私小插曲
(1)一家旨在为遭受情绪困扰的人提供支持的慈善机构开发了一个应用程序,该应用程序可以识别社交媒体帖子,这些帖子可能表明存在自残的可能性,并提醒已注册的人监视该用户;他们必须关注并被用户关注,表明他们有关系。
慈善机构对强烈的愤怒反应感到惊讶,这导致该应用程序在数小时内被停用。
慈善机构认为没有隐私问题,因为这些帖子在公共时间线上,任何人都可以看到;该应用程序没有修改或评论它们,而只是将它们重复给其他可能会看到它们的用户;对用户的结果不可能是有害的,它们要么可以忽略不计,要么非常有益;并且所涉及的其他用户已知是该用户的朋友。
基于Floridian的隐私模型,问题很明确:用户的尊严受到对潜在敏感信息的不必要关注的侵犯,并且任何其他论点都无法改善这一点
(2)Alice 是一所大学的图书馆员,负责使用图书馆分析来确定服务改进的机会。她在一些赞助人的行为中发现了一种不寻常的模式,她认为这些赞助人主要是来自特定种族背景的技术学科的女学生。
她相信她可以推荐有针对性的服务来帮助这群学生。爱丽丝在她的建议中没有看到任何隐私问题。尽管必须确定有关学生的身份,但他们的数据仅用于收集数据的目的,即改善图书馆服务。所涉及的学生不会被他人识别,而且提议的内容似乎没有什么害处;对这组学生的唯一影响将是提供增强的图书馆服务。
从Floridian的角度来看,存在严重的隐私问题。这些学生受到了不同的对待,尽管是出于善意的动机,因为他们是由算法决定的群体的成员,他们并没有要求加入,也不一定希望与他们有联系。这并不是反对使用分析的论点,而是陈述了考虑所有群体隐私的必要性,包括那些由算法确定的群体
(3)鲍勃是一个金融专业人士。 Bob 的雇主鼓励他们的员工腾出时间进行创造性的追求,而他的家人则希望他能做一些工作以外的事情。鲍勃有点胆怯,开始从事创意写作并使用化名参加在线论坛;他获得了论坛最佳新人奖,论坛不小心泄露了他的真名。这显然是侵犯隐私,论坛管理员道歉;然而,他们觉得这是一件小事,不明白鲍勃为什么会生气。他没有受到任何伤害,他的名誉也没有受到损害;相反,他的家人和同事可能会为他采纳了他们的建议而高兴,并祝贺他取得成功。
从Floridian的角度来看,鲍勃完全有权利对严重的隐私伤害感到生气。作为一个个体,他正在努力成长和发展,如果他被观察,被评论,甚至被祝贺,他就无法有效地做到这一点。
3 佛罗里迪隐私模式
正如我们在Bawden和Robinson(2019)中指出的那样,基于Floridi的原则开发一个隐私概念模型是很诱人的,并在必要时通过其他相关模型的各个方面进行增强。我们在表 1 中展示了一个简单的框图作为此类模型的前身。在这个简单的模型中,八个元素本质上是独立的。
有趣的是,鉴于隐私本身的模型和框架的过多,以及信息行为和素养的模型和框架,这种模型和框架可能是信息科学中与隐私有明显关系的两个重要问题,但创建另一个似乎是不可取的。
为了实际利用前面讨论的概念化,我们建议最好尝试为现有结构注入明确的Floridi隐私观点,并通过其他模型的元素进行增强。
首先考虑将隐私概念纳入信息行为模型,然后再考虑信息素养模型。
4 信息行为模型的隐私
就Floridi的信息哲学而言,隐私可以解释为环境中的信息可访问性,信息差距,信息(或本体论)摩擦和信息流。寻求将这个想法纳入一个或多个可用的信息行为模型中似乎是明智的。
已经推导出了许多这样的模型和理论:
Wilson(1999)的模型包括一个“沟通渠道”部分,其中信息摩擦自然会被放置。
在Maletzke(1963)的模型中,“来自[通信]介质的压力或约束”部分适合于考虑信息和数据摩擦。
没有任何信息行为模型(或者实际上是信息素养模型)被认为是最终和完整的。它们的发起者通常明确表示它们可以扩展以适应新的概念和背景。否则将面临越来越多的静态、部分过时的模型,唯一的补救办法是不断创建新模型来处理新技术和新信息环境。
原则上,隐私问题可以被引入到任何信息行为模型中,但在实践中,某些类型的模型似乎更适合这项任务,并且比其他模型更适合解决这些问题。
我们通过展示隐私问题如何包含在流程模型和解释主义范式中来说明这一点。
5 佛罗里迪信息行为过程模型中的隐私
信息行为的过程或流程图模型已经形成了信息行为研究的一个主要分支。
为了说明将佛罗里达隐私理念融入这种模型,我们使用信息搜索和通信模型 (ISCM) 。ISCM 的修订版 如图 1 所示。
ISCM 的修订版 (Robson & Robinson, 2015) 如图 1 所示。它以三种方式适用于我们的目的
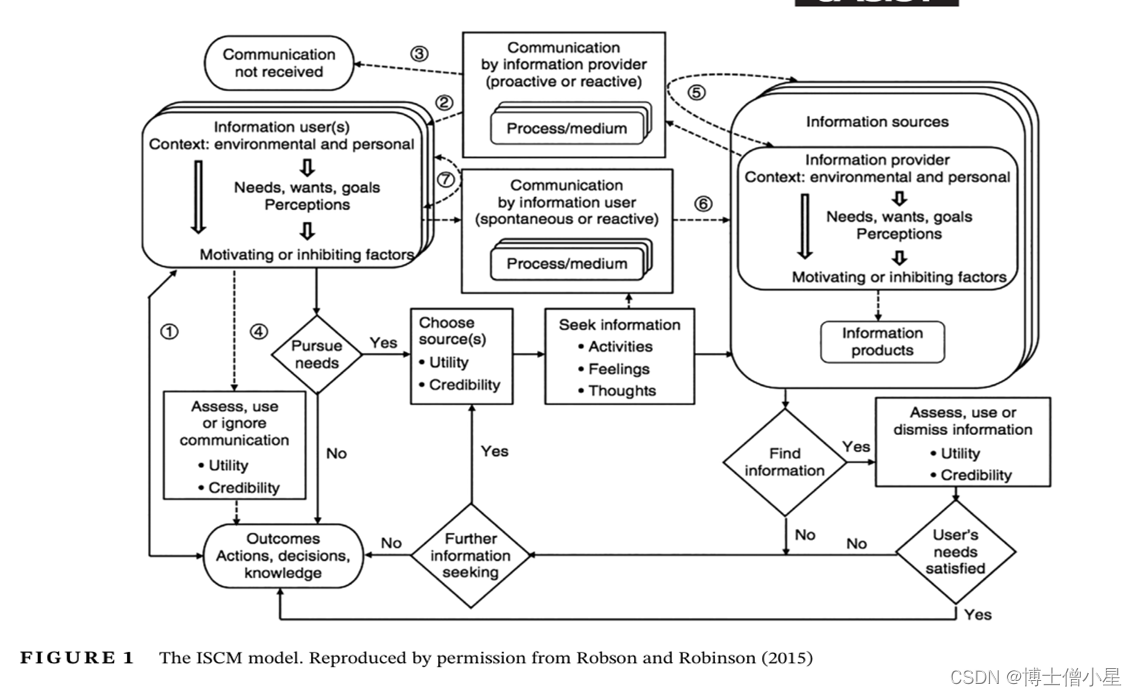
ISCM 的修订版 以三种方式适用于本文的目的:
首先,它是全面的,它包含了信息的寻找、访问、交流和使用的所有方面,而不是只关注某些方面。
其次,大多数过程模型仅从信息搜索者或用户、消息接收者(信息行为模型)或发送者或通信者(通信模型)的角度派生出来。隐私是一个双向问题;我们必须同时考虑沟通者和接受者。ISCM旨在结合这两种观点,这两个角色被认为是可以互换的:信息的传播者/提供者可以成为接收者/用户,反之亦然,无论是在单个信息交换中,还是在不同的交换中。隐私问题可能随时发生,双方都需要意识到潜在的隐私危害。
第三,虽然大多数信息行为模型都从个人寻求者或用户的角度出发,但ISCM在设计上更加广泛,侧重于“个人,群体和组织”,适合出于隐私目的考虑群体和个人。
前面确定的隐私概念可以非常直接地纳入ISCM,如下所示:
各种本体论摩擦在“沟通过程和媒介”部分表示。
“用户”和“提供商”部分是指个人、团体或组织。
“用户环境”和“提供商环境”部分,以及它们的“激励和抑制因素”,迎合了隐私规范和准则;
ISCM中的“结果”部分侧重于积极的结果-行动,决策和知识;但同样可用于不良结果,包括隐私损害。
6 佛罗里迪信息行为解释者范式中的隐私
作为我们这种信息行为方法的例子,从几个广泛使用的模型中,我们采用了“信息基础”。
“信息基础”被理解为一种物理或数字环境,由人们的行为暂时创造,这些环境聚集在一起执行除信息交流以外的特定任务,从中产生了一种促进信息自发交换和共享的社会氛围。作为信息场所研究的环境包括足部诊所,商店,餐馆,公共交通
此模型具有使其适合包含隐私概念的属性。
它侧重于群体和个人,以及连续的双向信息交换,请求者和提供者的角色交替进行。
信息基础必须具有丰富的上下文环境,使用惯例、角色和规范来解释信息交换的性质,因此自然有利于隐私问题和潜在危害。
在一个典型的信息环境中,参与者数量相对较少,且彼此都有一定程度的认识,匿名性和模糊性都将是重要的隐私因素
在 Fisher 等人的一项大学生研究中,感知隐私水平是影响信息基础偏好的主要因素之一,这种偏好并非自动获得更多隐私:
包括私人谈话区域或彼此相距足够远的桌子的地方促进可能是个人的对话。相反,信息场地可能很有吸引力,因为它们可以进行窃听,这可能有助于该地方的整体丰富性。
这是需要平衡本体摩擦的一个例子,在这种情况下是可听性。这些作者专门讨论了作为信息基础特征的环境噪声。这是信息摩擦如何在信息基础模型中得到自然处理的一个例子。
图2中显示了信息基础的典型关系图表示。
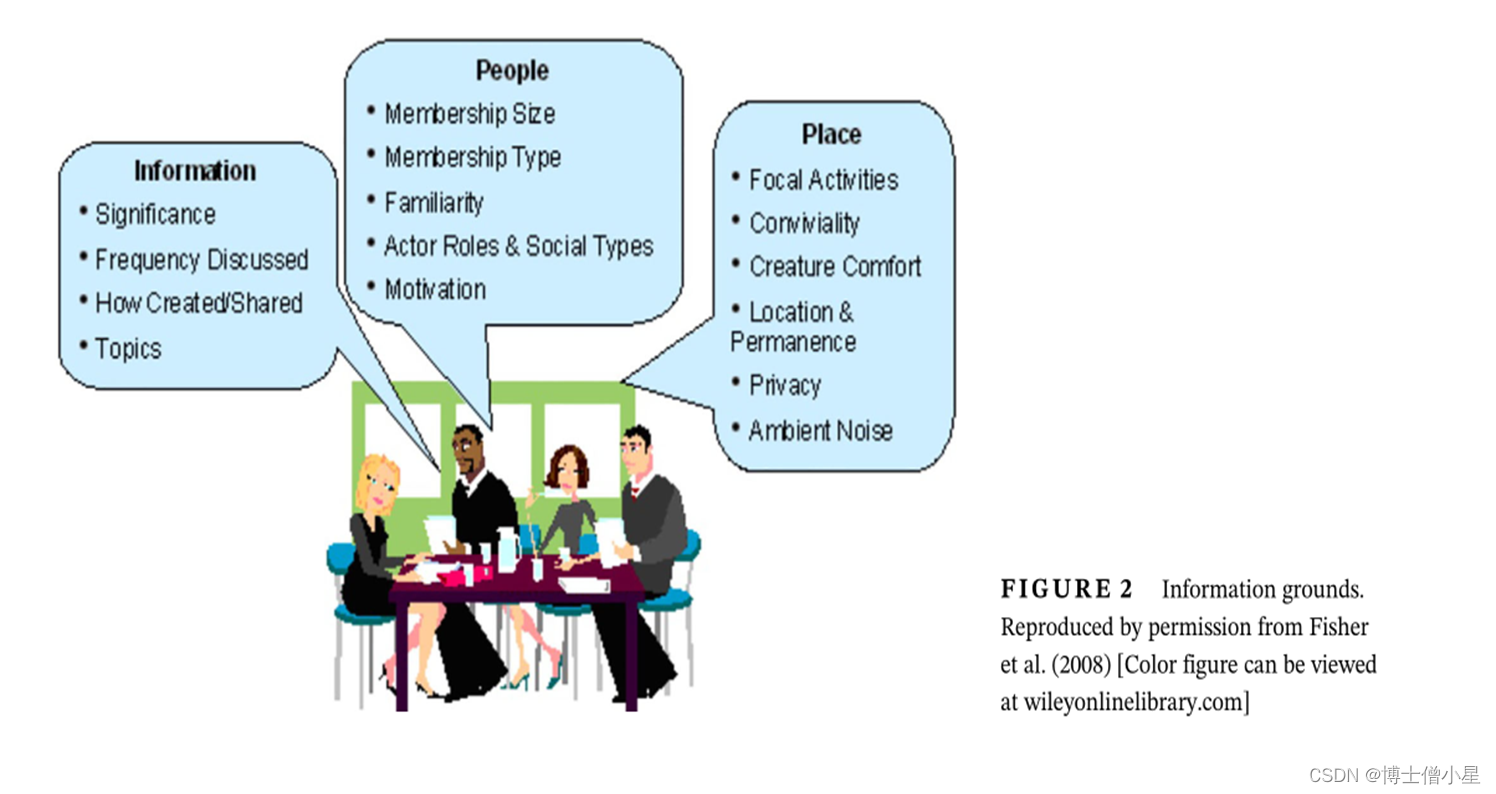
这在“地方”方面具有隐私概念,有效地限制在表示本体摩擦方面。
隐私的其他方面可能位于“信息”方面,信息流和信息技术包含在如何创建和共享信息的概念中。在“人”方面,会员类型和社会类型的概念考虑到群体隐私方面,而动机则包含个人对隐私的渴望。
最后,我们提到了慢速信息行为的解释主义模型,它阐明了“信息平衡”的概念,即小心谨慎地选择使用哪些信息来源,以及如何和为什么使用信息。
虽然这项研究没有明确处理隐私问题,但它的重点是找到本体论摩擦的最佳平衡;信息获取的速度和便利性,以及因此在特定时间内处理的信息量。
这是另一个例子,说明一些现有的信息行为模型能够以最小的调整纳入弗洛里迪的隐私概念。
上述分析表明,隐私概念可以被自然地纳入信息行为模型中;包括那些在模型的最初构建中明确关注隐私的模型(信息基础)和不关注隐私的模型(ISCM 和 Slow)。
这并不意味着隐私概念应该包括在所有的信息行为模型中,也不意味着那些不太适合包括隐私问题的模型是低级的;后者可能是为特定的问题或背景而设计的,在那里隐私可能不被认为是一个值得包括的问题。
但是,鉴于隐私问题越来越重要,我们可以说,那些自然地包含这些问题的模型可能会被证明是更普遍适用和有用的。
7 信息素养模型
与信息行为一样,信息素养有许多模型。它们同样分为两大类,一种是旧式的“能力”模型,表示个人技能和解决问题的能力,另一种是更新的,更全面,更灵活和包罗万象的“关系”模型。
早期的信息素养模型很少关注隐私问题。随着对数字环境的普遍重视,特别是对社交媒体的重视,隐私概念进入信息素养的推广中。
广为人知的信息素养模型明确提到隐私的是Metaliteracy方法,它具体目标之一是“在不断变化的技术环境中了解个人隐私,信息道德和知识产权问题”。
将隐私作为目标的具体内容表明,metaliteracy和类似的较新的整体框架,可能是将弗洛里达人的隐私概念引入信息素养模式的最佳载体。
然而,这些模型的开放和灵活的性质很少或没有规定应该引入哪些具体的背景。虽然它们肯定对基于信息哲学的隐私概念很有吸引力,但这些概念在这些模型中究竟如何表达却没有确定。
"隐私素养 "的概念很好地说明了如何实现这一点,这个概念与信息和数字素养相重叠,但又有区别。隐私素养是由Rotman(2009)提出的,是一个包含五个要素的框架,后来由Wissinger(2017)稍作修订。
这个框架可以很容易地进行调整,以包括前面讨论的弗洛里迪的隐私概念,目的是使其更普遍地适用于所有的隐私问题,超越社交媒体环境,这是隐私素养的最初重点。表2比较了这三个隐私素养框架的要素。
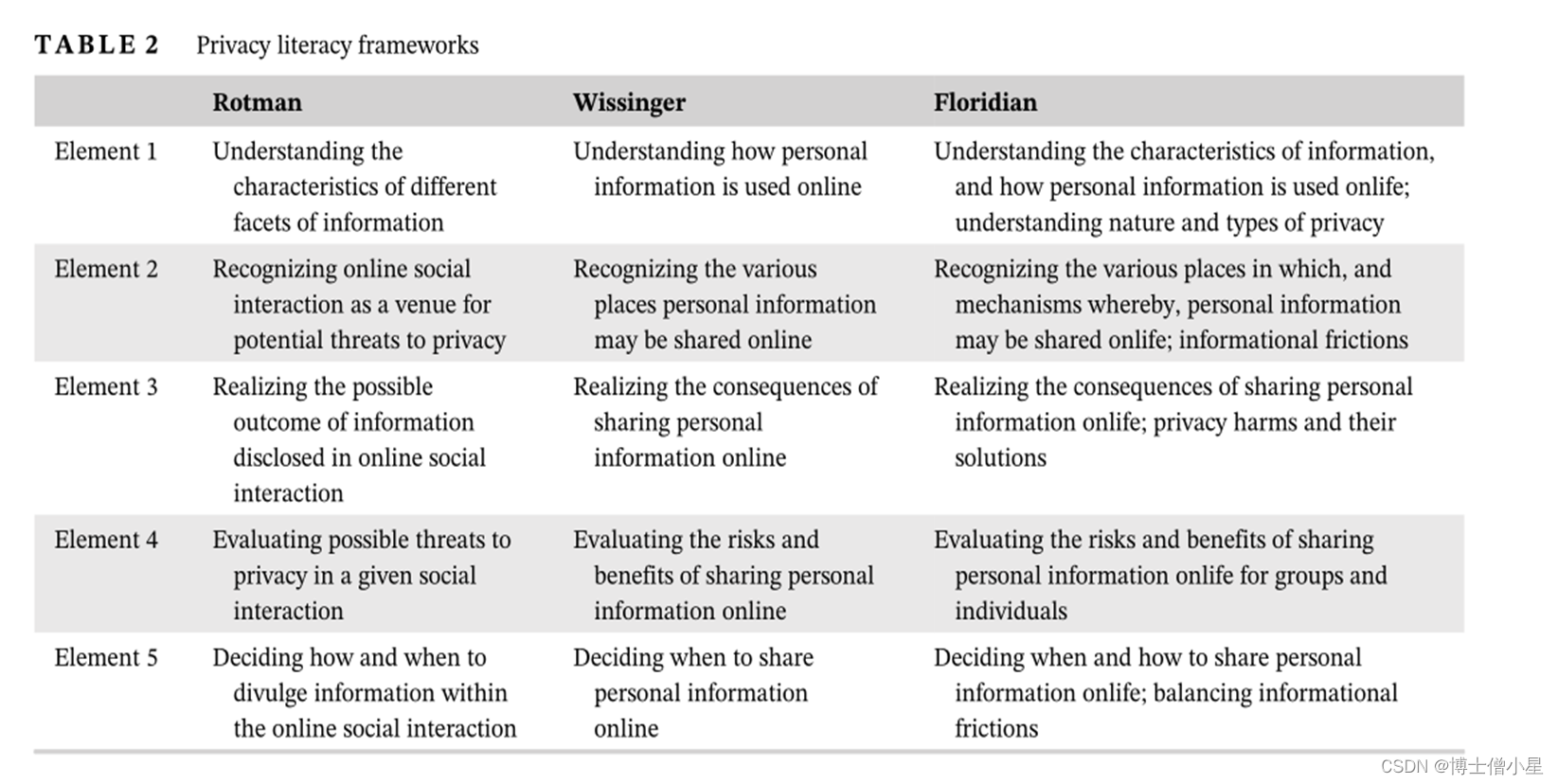
弗洛里迪版本涉及对信息和隐私特征的理解,将这种理解设定在 "onlife "领域,即在线和离线领域的融合,增加了对本体论摩擦的具体理解,规定了对一系列可能的隐私伤害的具体认识,提倡对个人信息的周到处理,并将其扩展到个人和团体,以及对个人信息的onlife共享,意味着对本体论摩擦的明确理解。在本表和图1的总结模型之间提供联系的概念如下:信息本体和伦理;onlife和infosphere;隐私的性质、类型和背景;群体和个人的隐私;以及信息摩擦。
因此,弗洛里迪的隐私概念可以很容易地纳入较新的信息素养概念中。
8 结论
很明显,从Floridi的信息哲学和他的信息伦理学中得出的信息隐私的概念,可以很容易地被纳入信息行为和信息素养的模型中,只是需要广泛的修改。就信息行为而言,两个非常不同的模型,一个来自过程模型系列,一个来自解释主义范式类别,被证明是合适的。在信息素养的案例中,一个较新的整体模型的例子,当被某种程度上扩展的隐私素养框架所增强时,是合适的。
弗洛里迪的概念,如匿名性、隐蔽性和本体摩擦,与这些信息科学概念模型中的现有概念相对容易、自然,这表明将弗洛里迪的信息哲学视为我们学科的适当理论基础的确是合理的。更广泛地说,它显示了形式和理论基础对信息科学的模型和框架的价值。
在这些想法的基础上,未来的工作将包括在隐私特别重要的环境中更全面地开发和评估这些类型的模型。


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











