






人工神经网络
后向传播算法(上)
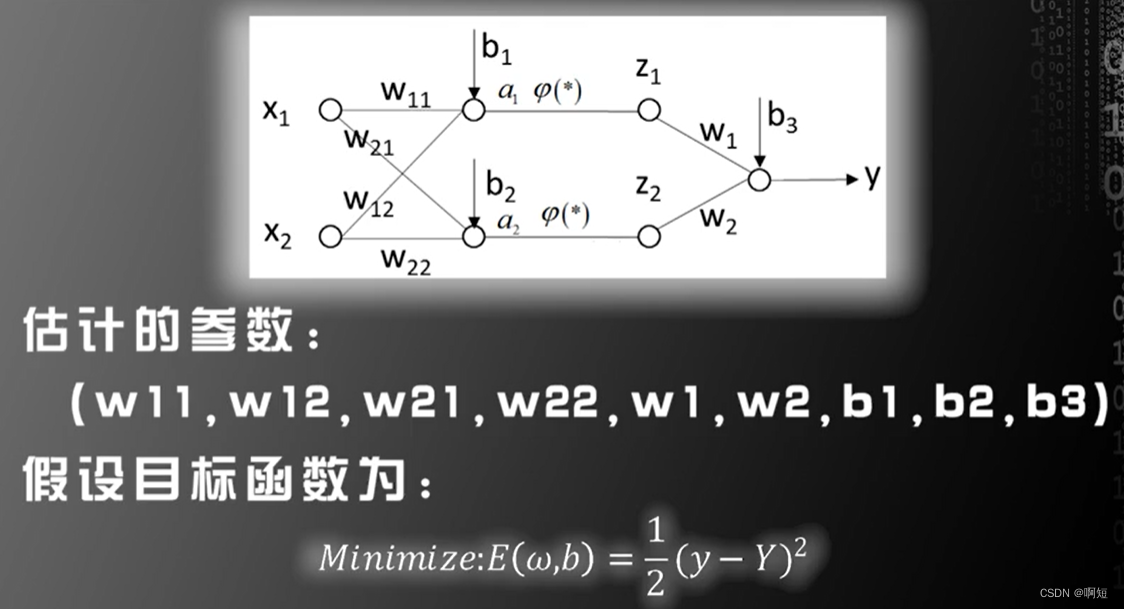
平方损失

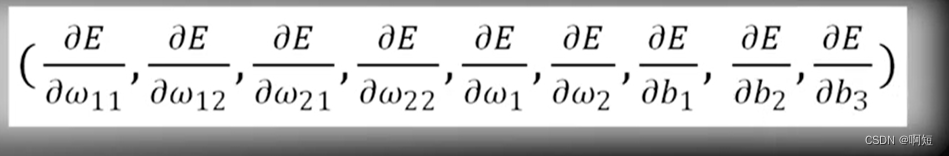
利用梯度下降的算法,我们需要计算这九个偏导数,这样计算太过麻烦,计算量太大。
那么我们如何根据神经网络这种分层的结构来简化求解偏导数的计算呢?这就是我们的后向传播算法
后向传播核心:这九个偏导数是相互关联的,根据偏导数的链式求导法则,可以用已经算出的偏导数去计算还未算出的偏导数,这笔直接计算九个偏导数要方便很多。
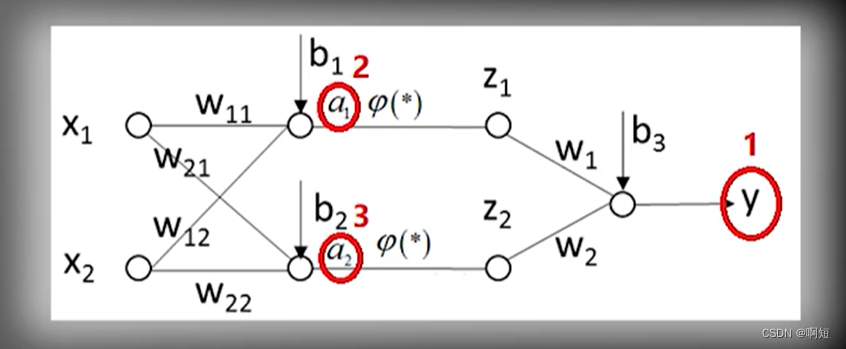
我们先去计算红圈的偏导数,这三个点是枢纽,其他的偏导数可以根据这三个点算出来。




原则上就是一个简单地链式求导法则,因为各层之间的变量函数关系是嵌套的,相互关联的,所以我们可以先算中间层,之后就可以方便我们计算别的偏导数了。
后向传播:输出往输入推,从后向前,所以叫做后向传播。



反向传播算法(下)
推广到更一般的网络,我们不限定层数。

第一行是第一层 a(0)是第一层的输入,在最后得到a(1),之后的函数是连接两层之间的非线性函数。

最后结果:
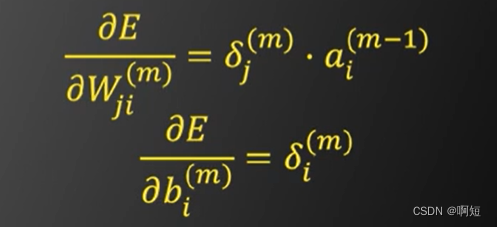
总结



反向传播的应用
实际应用中需要进一步改进。
非线性函数的改进
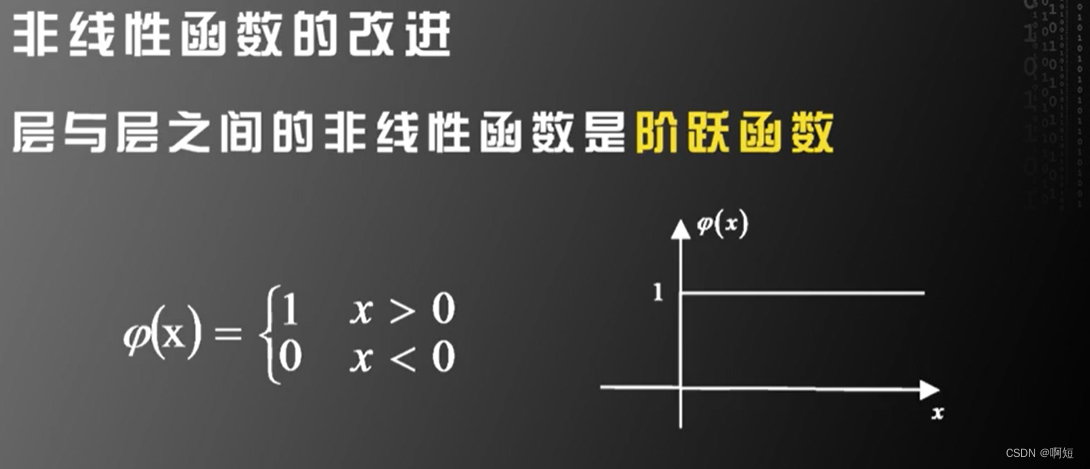
后向传播需要对非线性函数求导,但是阶跃函数没有导数。
我们必须对非线性函数进行改造。
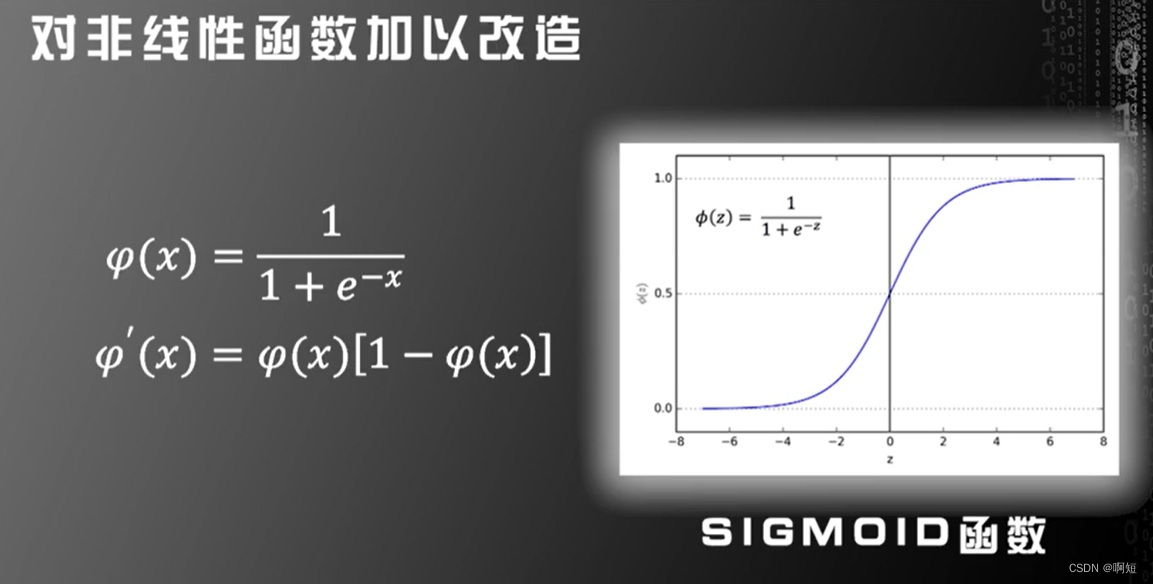
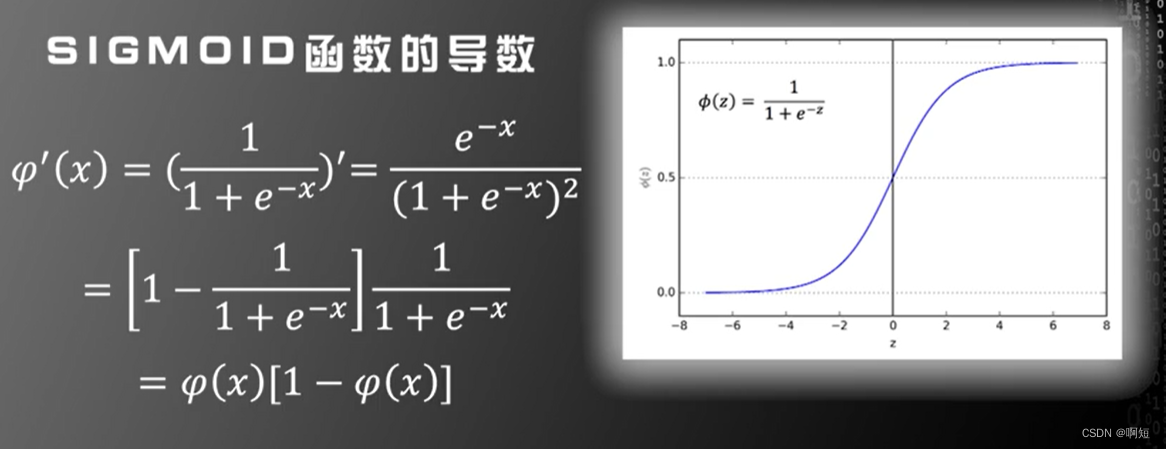
三层神经网络可以模拟任何决策面的证明是基于阶跃函数的,但是对于SIGMOID函数依旧是可以适用的。

第一个改进是利用:SIGMOID和rank函数来替代原来的阶跃函数
SOFTMAX和交叉熵
向量机中二分类问题标签取值:

人工神经网络中二分类问题标签取值:

K分类、K维的话,人工神经网络变为了K为变量。
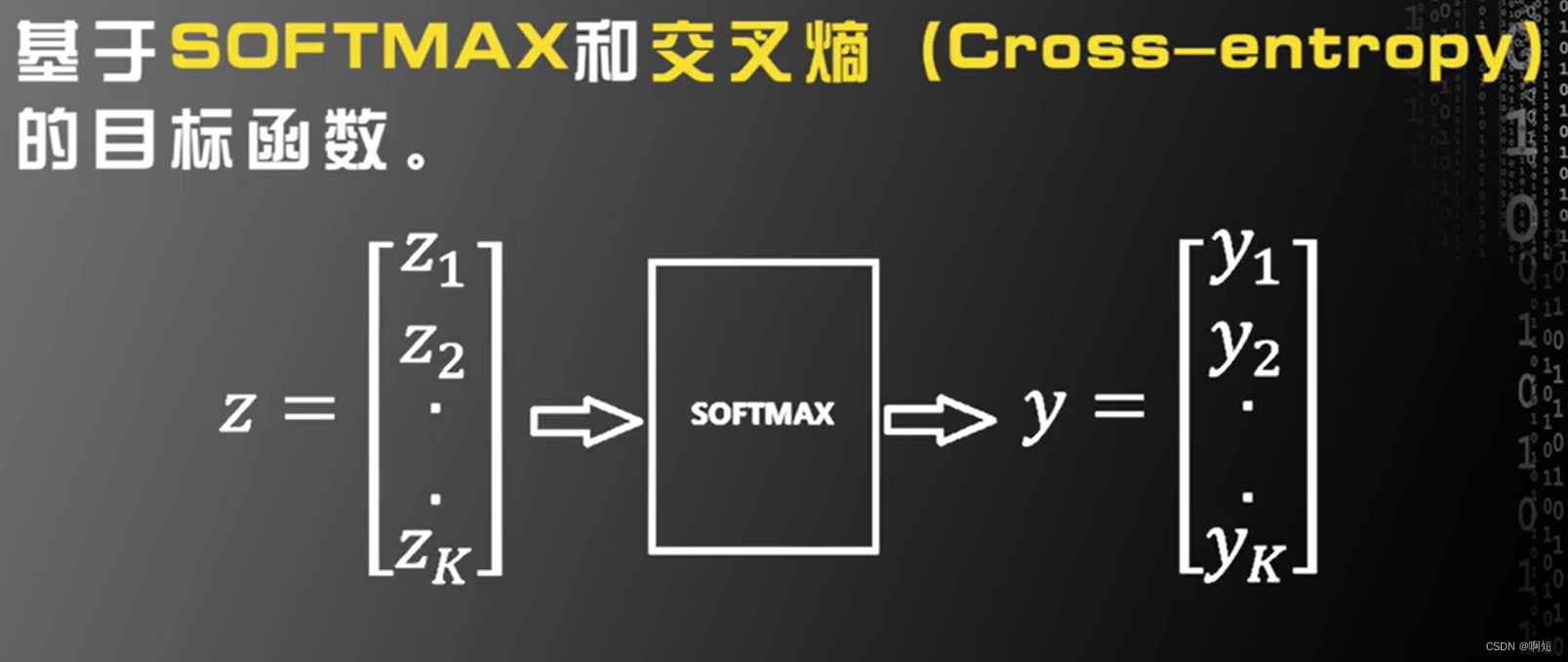
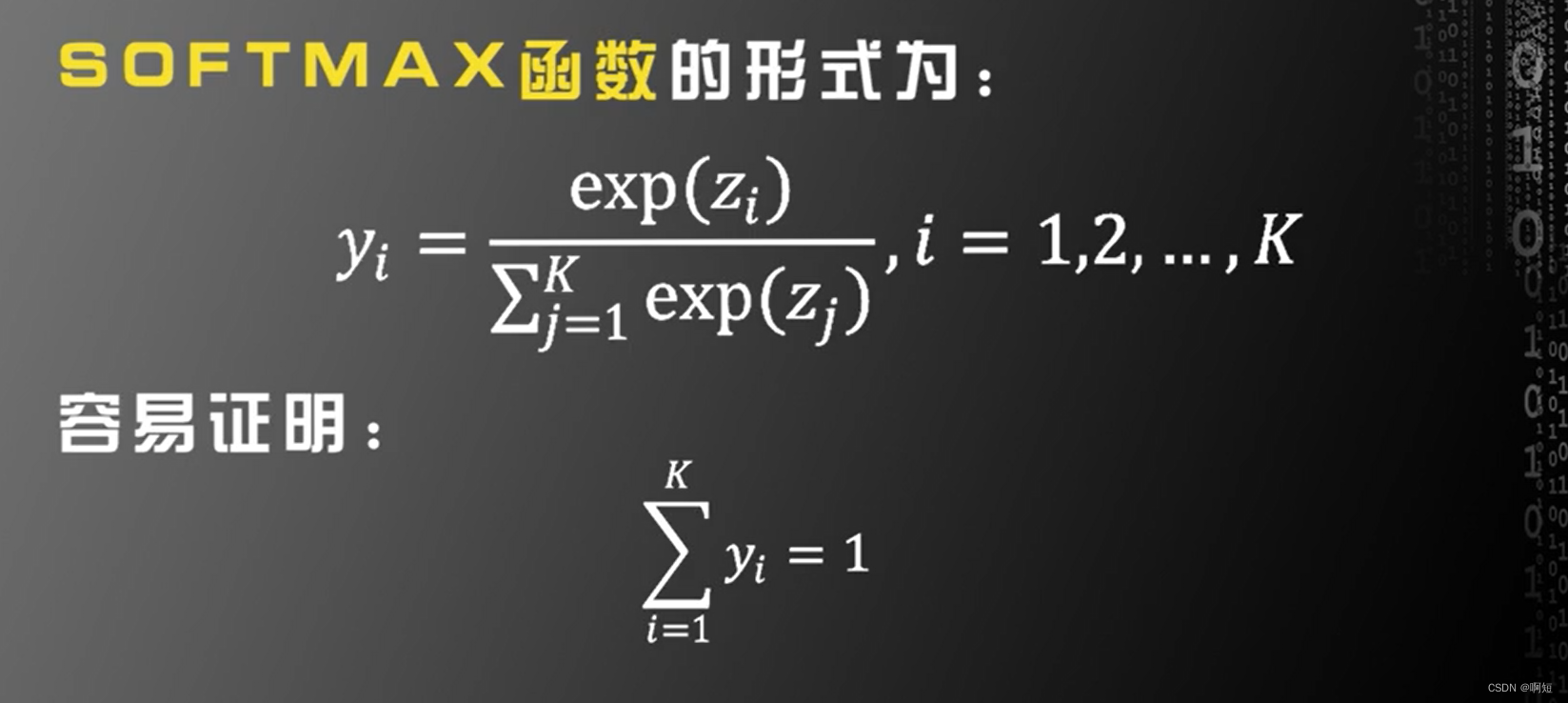
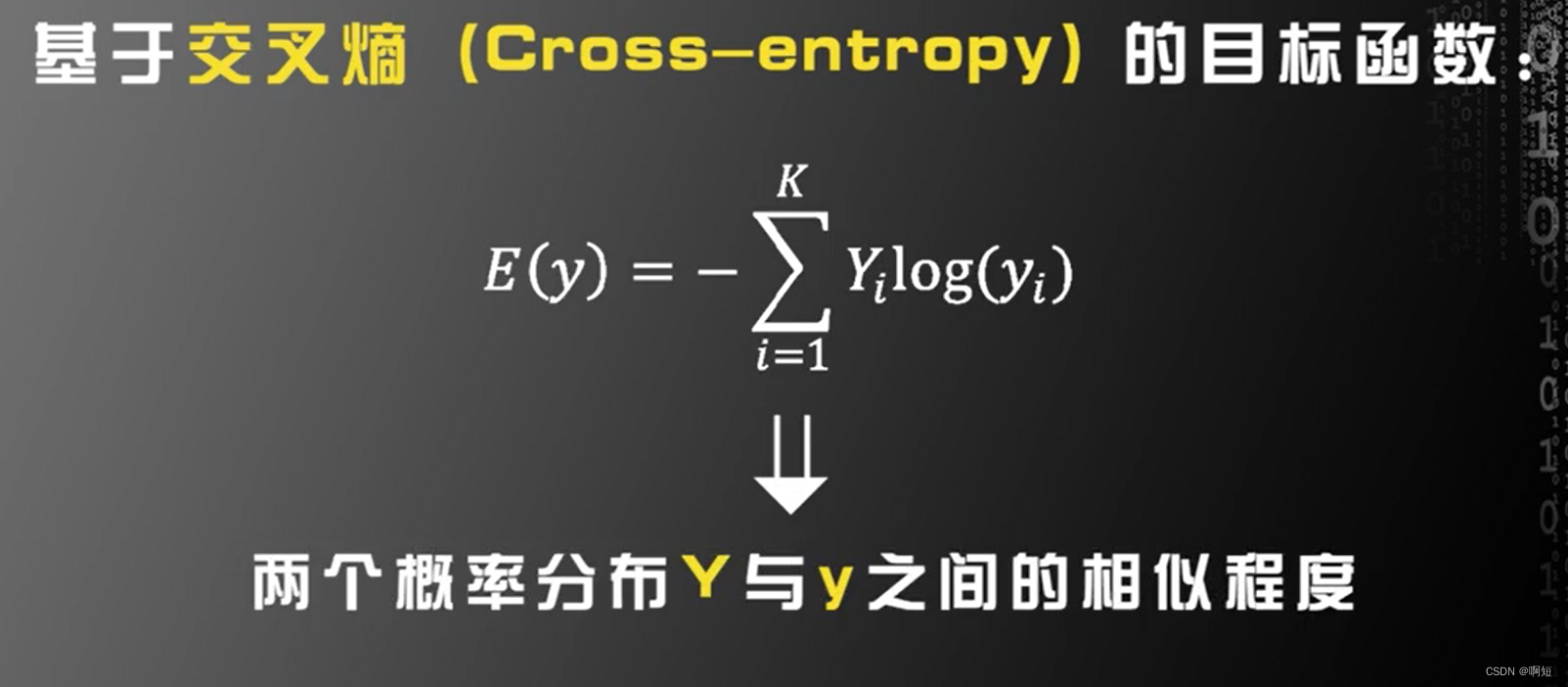



第二个改进就是利用SOFTMAX函数和交叉熵来改进目标函数,实践证明这样的目标函数比前面的目标函数(平方损失函数),更有利于训练,在实际中获得的识别率更高。
随机梯度下降法

每输入一个样本就要训练样本就要更新一下参数。
但是在实际应用中,我们的训练将非常慢。单一数据带来的随机性是非常大的,这样会让数据收敛变得非常慢。


以上10000/100=100个BATCH
按照BATCH遍历所有训练样本一次,我们称为一个EPOCH。

在随机梯度下降法SGD里,每一次训练整个训练集称为一个epoch,可以有好多个epochs;
batch越多说明分的越细
epoch训练的时候就越复杂
效果就越好














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









