







后向传播算法,简称BP算法,适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上。BP网络的输入输出关系实质上是一种映射关系:一个n输入m输出的BP神经网络所完成的功能是从n维欧氏空间向m维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。
后向传播算法(Back Propagation)
主要思想:梯度下降发求局部极值(Gradient Descent Method)
假设有函数 f(ω),我们希望找到这个函数上的最小值,要如何去做?
首先任取一点 ω0,此时这一点对应的函数值为 f(ω0)

接下来,我们要计算在这一点 ω0上,梯度的方向,即

计算出来为该点的斜率,此时我们需要沿着梯度下降的方向,走一定的“步数”

这时在很大程度上,f(ω1)的值要小于 f(ω0)的值。
同样的步骤,不断向下平移,直至找到斜率为0 的一点,此时我们成为找到了一个合理的局部极值点,退出

这个方法类似于一种“试探”过程,向左平移的过程就是一个不断试探的过程,最终找到了一个满意的最低的状态
但是在这个过程中,我们无法判断找到的局部极值点是否为函数的最小值,这便与我们一开始所选定的初始位置有关。当初始值ω0选定的位置离图中初始位置较远时,我们无法判断最终是否能集中至同一位置。
因此上述方法的好坏于选定的初始位置有很大关系。
接下来我们尝试用语言描述出上示算法
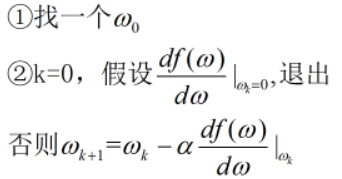
这里的α称为步长或者学习率
我们用泰勒展开来解释这里
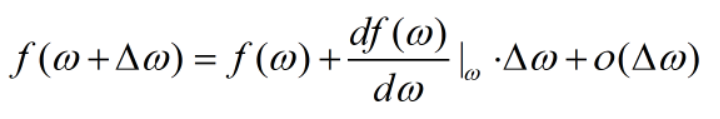
(最右侧一项意为比△ω的高阶无穷小)
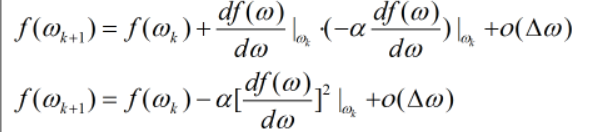 在上式中,最后一项可看做无穷小,同时α恒大于零,因此我们得到 f(ωk+1)小于 f(ω),同时每迭代一步f都会变小,直到最后找到极值为止
在上式中,最后一项可看做无穷小,同时α恒大于零,因此我们得到 f(ωk+1)小于 f(ω),同时每迭代一步f都会变小,直到最后找到极值为止
下面我们来推导BP算法
后向传播算法的推导
假设已知存在如下多层神经网络
输入{(Xi,Yi)} i=1~N
 我们要通过输入的X,调整神经网络中所有的ω和b,使得神经网络中的y尽量等于输入中的Y
我们要通过输入的X,调整神经网络中所有的ω和b,使得神经网络中的y尽量等于输入中的Y
针对某一输入 (X,Y),定义优化函数E
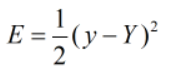
优化函数有无限多种,这里只是选用了最简单的其中一种,其中1/2的作用是方便求导运算。
推导梯度下降算法
①随机取(ω11,ω12,ω21,ω22,ω1,ω2,b1,b2)
②对所有的ω,求ω关于优化函数E的偏导
对所有的b,求b关于优化函数E的偏导
(多维使用偏导数)
③
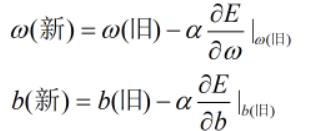
④当所有的偏导数均为0时退出循环
在算法中,每当我们输入一个X,均可得到一个与之对应的E,后续不断输入X并且不断调整E。而算法的重点在于:如何计算公式中的偏导数。
计算偏导数
根据BP算法,我们要针对神经网络中的九个ω和b分别计算偏导,而计算的顺序有一定的规则,换句话说,我们可以根据前面计算的结果用于后面求导的计算中。
在神经网络中,ω1和ω2与y有直接关系,而其余ω和b分别于a1,a2有直接关系,因此我们第一步是求出y,a1,a2关于E的偏导


 同理
同理

在多层神经网络中,当我们输入X后,首先进行前向计算,即从左向右以此计算。而后向传播的意义为:从最后的y开始,向左进行求偏导计算。
这里介绍一种特殊的函数:阶跃函数,其图像如下
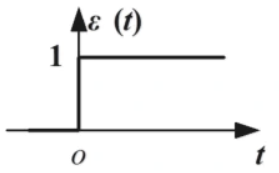
可以看到,除了在0这一点,其余位置上φ(x)均为0,这种情况下带入我们上述推算的偏导中便不可以使用,于是我们引入其他更加方便的函数
①sigmoid函数
 其优点在于求导后十分简易,同时在三层神经网络中同阶跃函数一样能够模拟任意的决策面:
其优点在于求导后十分简易,同时在三层神经网络中同阶跃函数一样能够模拟任意的决策面:
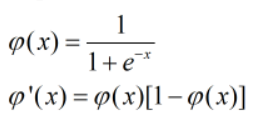
②双曲正切(tanh)函数
 同样可以模拟任意的决策面
同样可以模拟任意的决策面
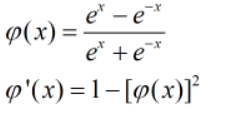
下面两种函数为深度学习出现后常采用的函数
③Relu(Rectified Linear Units)函数

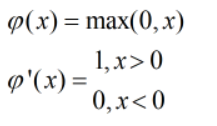
在tanh函数中,其最大值为1,最小值为-1,当函数值比较大时,其值必然会被压缩,因此无法将网络的全部信息由当前层传导至下一层。
而Relu将所有小于零的情况压缩为零,会有比较多的神经元(小于零),会使这一层活跃的参数减少,在大规模的神经网络计算BP算法中可以有效地降低每一层训练参数的活跃程度,从而降低训练的复杂度,在同样的训练样本的情况下使训练变得更加收敛。
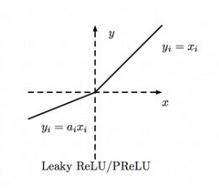
④Leak Relu
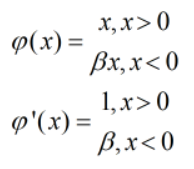
接下来我们从一个普遍性的例子中还原BP算法
假设输入X,这里的X是一个N*1维的向量
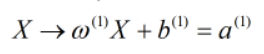
ω是MN维向量,而b是M1维向量。因此在第一层中共有M个神经元。 而这种表达形式与下图的神经网络的表达形式是一致的
 继续向后拓展,得到
继续向后拓展,得到
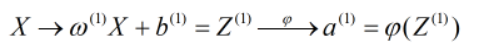 在图中表示即为
在图中表示即为
 经过非线性函数后,将得到第二层的内容
经过非线性函数后,将得到第二层的内容
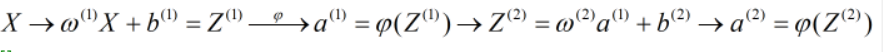 接下来一直网线进行,直至达到最后一层
接下来一直网线进行,直至达到最后一层
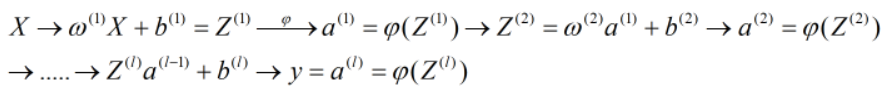
在推导前,我们介绍几个定义:
①网络共有l层
②Z(k),a(k),b(k)是第k层的向量,与第k层神经元个数一致
③使用Zi(k),ai(k),bi(k)来表示Z(k),a(k),b(k)的第i个分量
④用yi表示y的第i个分量
BP算法流程
①随机初始化所有(ω,b)
②假设有训练样本(X,Y),将训练样本带入网络,可求出所有的(Z,a,y),且通过BP算法输出的结果y与训练样本Y的维度保持一致。(前向传播流程)
③链式法则求偏导:定义目标函数,最小化E=1/2(y-Y)2

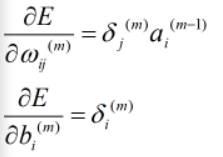
通过上述四式联合可以将所有(ω,b)求出来
④更新参数
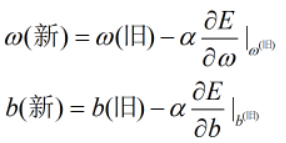
(创作不易 ,如需转载请联系作者)















 1640
1640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









