







 本文介绍了正则化方法在防止过拟合、提高模型泛化能力中的作用,详细探讨了L2和L1正则化,并重点讲解了Logistic回归。通过示例展示了在scikit-learn中如何实现L1正则化的逻辑回归。
本文介绍了正则化方法在防止过拟合、提高模型泛化能力中的作用,详细探讨了L2和L1正则化,并重点讲解了Logistic回归。通过示例展示了在scikit-learn中如何实现L1正则化的逻辑回归。
正则化方法,防止过拟合,提高泛化能力
在机器学习算法中,常常将原始数据集分为三部分:training data、validation data 、testing data。
其中validation data用来避免过拟合, 根据validation data上的效果确定学习速率、迭代停止时机等。testing data则用来判断模型的好坏。
L2 regularization权重衰减
L2正则化就是在代价函数后面加上一个正则化项:
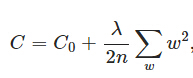
C0表示原始的代价函数。λ是正则化系数,n为训练集的样本大小,w为模型参数。意义就是所有参数w的平方和除以训练集样本大小,系数1/2为了计算方便。L2正则化项效果是减小w,防止参数w过大导致过拟合,更小的权值w,表示网络的复杂度更低。
正则化系数λ的值越大,表示对模型的复杂度惩罚越大。
L1 regularization
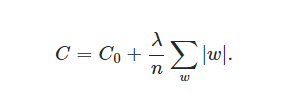
L1正则化是所有的权重w的绝对值的和,除以样本大小n,λ是正则化系数。L1正则化不需要乘以1/2。
L1的正则化的效果是当w>0时,更新后w变小;w<0,更新后w变大,让w往0靠拢,使网络中的权重尽可能为0,相当于减少模型复杂度,防止过拟合。
过拟合问题往往来源于过多的特征,解决的方法就是减少特征数量,或者正则化。
Logistic regression
转载:http://blog.csdn.net/pakko/article/details/37878837
http://www.cnblogs.com/guyj/p/3800519.html
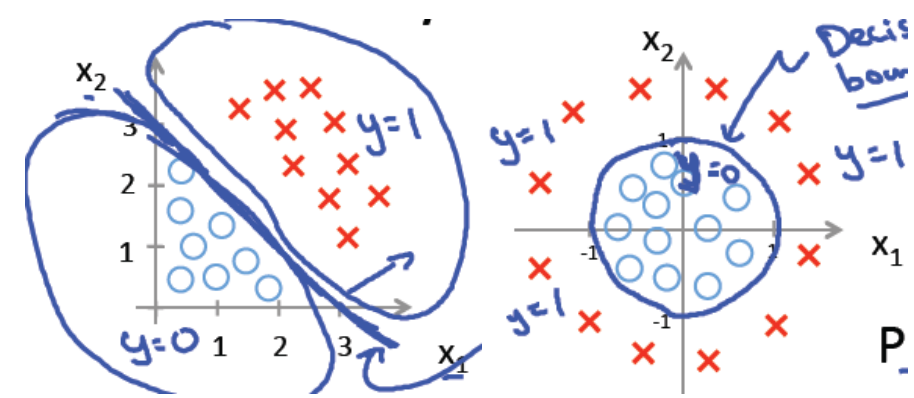
Logistic回归主要用于二分类问题。
对于线性的决策边界,边界形式为:
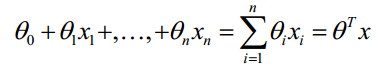
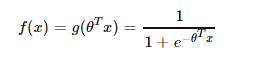
结合0和1两种概率,可以写为:
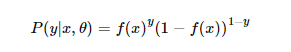
通过最大似然估计来求解参数。参数的似然函数为:
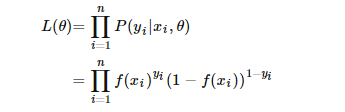
转换为:
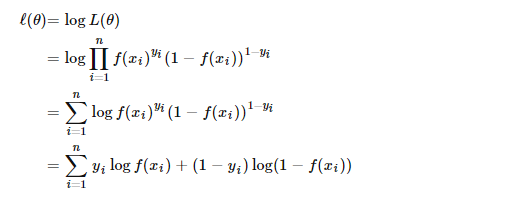
最终求平均值,得到代价函数为:
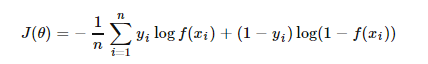
通常还要使用正则化的方法来约束模型的参数,防止过拟合。
Cost(Θ) =
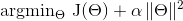
此外,f(x)需要添加常数b修正为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









