







CUDA架构
之前的图形处理架构中,计算资源划分为顶点着色器和像素着色器。CUDA架构包含了一个统一的着色器流水线。同时,GPU不仅能任意地读写内存,还能访问软件管理的缓存。
CPU与GPU
CPU 和 GPU之间浮点运算能力之所以存在这样的差异,原因就在于CPU具有复杂的控制逻辑和大容量的缓存,适合进行控制转移,处理分支繁杂的任务,而GPU专为计算密集型、高度并行化的计算而设计。
架构
使用GPU运行的程序存在几个特征: 算法密集、高度并行、控制简单、多阶段执行等。
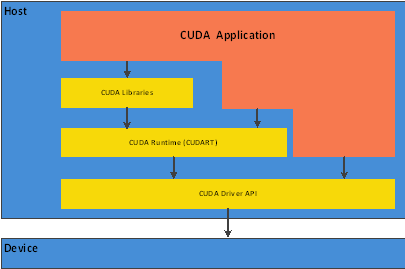
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。
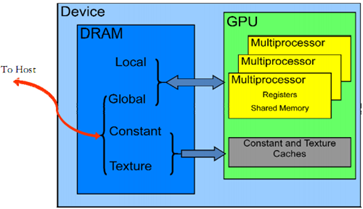
CUDA提供了片上共享内存,使得线程之间可以共享数据。CUDA线程可以在执行过程中访问多个存储器空间的数据。
1. 每个线程都有一个私有的local存储器。
2. 每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。
3. 所有的线程都可以访问相同的全局存储器。CUDA
CUDA C程序将在两个不同的处理器上执行计算,需要两个编译器。
nvcc 是 CUDA 的编译工具,它可以将 .cu 文件解析出在 GPU 和CPU 上执行的部分,它会帮忙把 GPU 上执行和主机上执行的代码区分开来。在 GPU 执行的部分会通过 NVIDIA 提供的 编译器编译成中介码,主机执行的部分则调用 gcc 编译。
一般,将CPU以及系统的内存称为host,将GPU及其内存称为device。在CUDA中,主程序还是由CPU来执行,并行数据处理部分是在GPU上执行,在GPU上运行的函数称为核函数。在调用核函数时,它将由N个不同的CUDA线程并行执行N次,执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。
在 CUDA 程序中,主程序在调用任何 GPU 内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。
线程块中的最大的线程数量不能超过设备属性结构中maxThreadsPerBlock域的值。这个值并不固定,有的是512,有的是1024。
核函数只能在主机端调用,其调用形式为:Kernel <<<Dg,Db, Ns, S>>>(param list)
Dg: 定义grid的维度和尺寸。Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
Db: 定义一个block的维度和尺寸,即一个block有多少个thread。Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.x*Db.y*Db.z个thread。
Ns: 可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。
S: 一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。














 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









