







一、Docker 复杂安装
1.1、mysql 主从复制
新建主服务器容器实例3307,新建从服务器容器实例3308。主服务器容器同步数据到 从服务器容器
1、新建主服务器容器实例 3307
docker run -p 3307:3306 --name mysql-master \
-v /yzg/mydata/mysql-master/log:/var/log/mysql \
-v /yzg/mydata/mysql-master/data:/var/lib/mysql \
-v /yzg/mydata/mysql-master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
2、进入/mydata/mysql-master/conf 目录下新建my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
3、重启 主服务器容器
docker restart mysql-master
4、进入主服务器容器和mysql
docker exec -it mysql-master /bin/bash
mysql -uroot -p # 密码root
5、创建一个用户并且授权能够实现主从复制
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
# slave是用户,后面创建主从关系时使用过
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%'; # 授权
6、新建从服务器容器 3308
docker run -p 3308:3306 --name mysql-slave \
-v /yzg/mydata/mysql-slave/log:/var/log/mysql \
-v /yzg/mydata/mysql-slave/data:/var/lib/mysql \
-v /yzg/mydata/mysql-slave/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
7、进入/mydata/mysql-slave/conf目录下新建my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
8、重启容器
docker restart mysql-slave
9、在主数据库中查看主从复制
show master status;

10、进入 从服务器容器和mysql,命令和上面一样。
11、在从数据库中配置主从复制。 要在从数据库中执行,切记!!!!!
change master to master_host='192.168.200.132', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30;

参数详解:
master_host:主数据库的IP地址【虚拟机的ip】;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。
12、在从数据库中查询主从关系
show slave status \G;

13、在从数据库中开启主从复制

14、再次查询

测试:
主机创建数据库,建表,查看从机的数据是否同步

1.2、Redis
1.2.1、Redis存储大量数据解决方案
🔴 面试题: 1~2亿条数据需要缓存,请问如何设计这个存储案例.
单机单台100%不可能,肯定是分布式存储,用redis如何落地?一般有三种方案
哈希取余分区

2亿条记录就是2亿个k,v,我们单机不行,必须要分布式多机,`1集群,用户每次读写操作都是根据公式: hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
一致性 hash 算法
背景
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
一致性 hash 算法一般有三个步骤:
(1)算法构建一致性哈希环
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对 232 取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到 232-1,也就是说0点左侧的第一个点代表 232-1, 0和 232-1在零点中方向重合,我们把这个由 232 个点组成的圆环称为Hash环。

(2)服务器IP节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用 Hash 进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:

(3)key落到服务器的落键规则
当我们需要存储一个kv键值对时,**首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走” **,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。

优点:
容错性:假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。
一般的,在一致性Hash算法中,如果一台服务器不可用,**则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)**之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。

**拓展性:**数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,
不会导致hash取余全部数据重新洗牌。

缺点:
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:

总结:
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
哈希曹分区
背景
就是为了解决 一致性哈希算法 的数据倾斜问题
哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
解决的问题
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
有多少个 hash 槽?
一个集群只能有16384个槽,编号0-16383(0-214-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
如何计算 hash槽?
- redis 会根据节点的数量,将 16384 个 hash 槽 分配到各个节点上
- 通过 crc16 算法对key的有效部分进行计算,得出一个结果
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
- 这个结果对 16384 进行取余,结果就是分配在哪个hash 槽上

1.2.2、Redis 集群搭建

1、先关闭防火墙 + 启动 Docker 服务、分别启动六个redis 实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
参数详解:
docker run -d: 创建容器实例,并后台运行
--net host : 使用宿主机的IP和端口,默认【后边讲这个参数】
--privileged=true : 获取宿主机root用户权限
-v /data/redis/share/redis-node-6:/data :容器卷,宿主机地址:docker内部地址
redis:6.0.8 : redis 镜像版本号
--cluster-enabled yes : 开启redis集群
--appendonly yes : 开启持久化
--port 6386 :redis 端口号
2、进入 redis-node-1 容器,创建主从关系
redis-cli --cluster create 192.168.200.132:6381 192.168.200.132:6382 192.168.200.132:6383 192.168.200.132:6384 192.168.200.132:6385 192.168.200.132:6386 --cluster-replicas 1
--cluster-replicas 1 表示为每个master创建一个slave节点 。【和 redis 创建集群的命令意思一样】

分配情况,没有问题,输入 yes、搭建完成

3、以 6381 为例,连接 redis,查询集群情况
redis-cli -p 6381 # 连接 redis
cluster nodes # 查询集群情况

1.2.3、数据读写存储
当我们在 6381 中存储数据时,发现有的 key 存不进去,有的 key 却能存进去。

这是因为 hash 槽的原因,由于 6381 只分配了 0~ 5460 之间的卡槽,如果 计算出来的 key 存到了别的卡槽上,自然就会报错。
解决方法:
使用 集群模式 启动redis
redis -c -p 6381

使用集群模式启动 redis 后,自动计算 key 存到哪个卡槽上,并自动切换到对应的 redis 实例上
查看集群情况命令汇总:
info replication # 查看主从关系【redis 内部使用该命令】
cluster nodes # 【redis 内部使用该命令】
cluster info # 【redis 内部使用该命令】
redis-cli --cluster check 192.168.200.132:6381 # docker 容器内使用该命令
1.2.4、容错切换转移

首先停掉 6381 主机测试:
docker stop redis-node-1
我们在登录随意一个 redis 查看集群情况:

之前我们 6381 为主机,6381 停掉之后,6384 成为主机。
当 6381 再次启动之后,不会在变成主机,会变成 从机。
如果想让 6381 继续当主机,让 6384 重启

1.2.5、主从扩容案例

1、增加 6387、6388 俩个节点:
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
2、进入到 6387 容器内部,并加入集群
# 进入 6387 容器内部
docker exec -it redis-node-7 bash
# 将 6387 增加到集群
redis-cli --cluster add-node 192.168.200.132:6387 192.168.200.132:6381
# 6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
 添加节点成功
添加节点成功
3、再次检查节点情况
redis-cli --cluster check 192.168.200.132:6381

我们可以看到虽然 6387 加入集群成功,但是还没有分配槽点和从服务器、
4、重新分配槽号
# redis-cli --cluster reshard IP地址:端口号
redis-cli --cluster reshard 192.168.200.132:6381

5、查看分配情况

重新分配的规则,并不是所有的槽点重新分配,而是将之前的三台主机匀出来一点分给 新节点, 因为重新分配成本太高
6、为 6387 分配从服务器 6388
命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli --cluster add-node 192.168.200.132:6388 192.168.200.132:6387 --cluster-slave --cluster-master-id 5bbd8a7f459a72f28b94eae468835b56c6f4fd75
# -------这个是6387的 ID ,按照自己实际情况
最后查看一下集群情况,扩容成功!!!!!
1.2.6、主从缩容案例
删掉 6387、6388 节点完成缩容,考虑俩个问题:
- 先删除哪个节点?
- 删除后节点槽号又是如何分配的?
1、先删除 6388 从节点
# 命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID
redis-cli --cluster del-node 192.168.200.132:6388 e8377c7fc4170ba19ef5f410d0c67b003ebac35d
2、重新分配槽位
redis-cli --cluster reshard 192.168.200.132:6381

不是只能分配给一个 节点,可以多执行几次 reshard 命令,分配多个节点不同的槽位,这里只是为了方便
3、查看集群情况

6381 分配了 8292 个槽位 !!!
4、删除 6387
redis-cli --cluster del-node 192.168.200.132:6387 5bbd8a7f459a72f28b94eae468835b56c6f4fd75
总结
首先要非常清楚的了解: 解决分布式存储大量数据的三种解决方案
- 哈西取余分区
- 一致性hash算法
- 哈希槽
熟练掌握 redis 集群的搭建、扩容、缩容
二、Dockerfile
官网:https://docs.docker.com/engine/reference/builder/
2.1、是什么?
Dockerfile是用来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本。
类似于 Linux 中的 shell 脚本

构建三部曲:
- 编写 Dockerfile 文件
- docker build 命令构建镜像
- docker run 镜像运行容器实例
Docker 内容基础知识:
1:每条保留字指令都必须为大写字母且后面要跟随至少一个参数
2:指令按照从上到下,顺序执行
3:#表示注释
4:每条指令都会创建一个新的镜像层并对镜像进行提交
Dockerfile 执行的大致流程:
(1)docker从基础镜像运行一个容器
(2)执行一条指令并对容器作出修改
(3)执行类似docker commit的操作提交一个新的镜像层
(4)docker再基于刚提交的镜像运行一个新容器
(5)执行dockerfile中的下一条指令直到所有指令都执行完成
简单来说,dockerfile 每执行一条指令都会提交新的镜像层,执行完得到最终的镜像层
从应用软件的角度来看,Dockerfile、Docker镜像与Docker容器分别代表软件的三个不同阶段,
- Dockerfile是软件的原材料
- Docker镜像是软件的交付品
- Docker容器则可以认为是软件镜像的运行态,也即依照镜像运行的容器实例

Dockerfile,需要定义一个Dockerfile**,Dockerfile定义了进程需要的一切东西**。Dockerfile涉及的内容包括执行代码或者是文件、环境变量、依赖包、运行时环境、动态链接库、操作系统的发行版、服务进程和内核进程(当应用进程需要和系统服务和内核进程打交道,这时需要考虑如何设计namespace的权限控制)等等;
2.2、保留字指令
FROM : 基础镜像,当前新镜像是基于哪个镜像的,指定一个已经存在的镜像作为模板,第一条必须是from
MAINTAINER : 镜像维护者的姓名和邮箱地址
RUN : 容器构建时需要运行的命令,RUN是在 docker build 时运行,有俩种格式:
第一种格式:Shell 格式。比如:RUN yum -y install vim ,在build时会安装 vim

第二种 exec 格式:

EXPOSE : 当前容器对外暴露出的端口
WORKDIR: 指定在创建容器后,终端默认登陆的进来工作目录,一个落脚点
USER: 指定该镜像以什么样的用户去执行,如果都不指定,默认是root.
ENV: 用来在构建镜像过程中设置环境变量。
比如:ENV MY_PATH /usr/mytest
这个环境变量可以在后续的任何RUN指令中使用,这就如同在命令前面指定了环境变量前缀一样;也可以在其它指令中直接使用这些环境变量
比如:WORKDIR $MY_PATH
ADD : 将宿主机目录下的文件拷贝进镜像且会自动处理URL和解压tar压缩包
COPY : 类似ADD,拷贝文件和目录到镜像中。
将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 <目标路径> 位置
COPY 源文件路径 目标路径
COPY [“源文件路径”, “目标路径”]
VOLUME: 容器数据卷,用于数据保存和持久化工作
CMD: 指定容器启动后的要干的事情, 格式和 RUN 命令一致
**Dockerfile 中可以有多个 CMD 指令,但只有最后一个生效,CMD 会被 docker run 之后的参数替换
**注意和 RUN 的区别: RUN 是在 docker build 时运行,CMD 是在 run 之后运行
ENTRYPOINT : 也是用来指定一个容器启动时要运行的命令,类似于 CMD 指令,但是 ENTRYPOINT 不会被 docker run 后面的命令覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序
ENTRYPOINT 命令格式:

案例:
假设已通过 Dockerfile 构建了 nginx:test 镜像:


首先不写参数情况下:
CMD 会将自己参数 /etc/nginx/nginx.conf 传递给 ENTRYPOINT, 因此变成了 : nginx -c /etc/nginx/nginx.conf
写参数的情况下:
参数 是/etc/nginx/new.conf ,这个参数覆盖了 CMD 中的参数,因此传递给 ENTRYPOINT 的不是 /etc/nginx/nginx.conf ,而是命令行后边的参数 /etc/nginx/new.conf
ENTRYPOINT 和 CMD 都是在 docker run 命令之后运行的,区别就是:CMD 会被 run 后面的参数覆盖,ENTRYPOINT 不会被覆盖,并且还能接受参数。如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
2.3、案例
使用Dockerfile 为CentOS 增加 vim + ifconfig + java8 功能
1、Java8 镜像下载地址:https://mirrors.yangxingzhen.com/jdk/jdk-8u171-linux-x64.tar.gz
下载 CentOS
# 不要下载最新版的 CentOS,新版的 CentOS 的yum 源有问题
docker pull centos:7
2、创建 myfile 文件夹,将下载好 的 Java8 传进去,并编写 Dockerfile文件**【D 一定要大写】**

# 基础镜像的名字
FROM centos:7
# 维护者
MAINTAINER zzyy<zzyybs@126.com>
# 指明环境变量
ENV MYPATH /usr/local
# 登录CentOS之后的目录
WORKDIR $MYPATH
#安装vim编辑器
RUN yum -y install vim
#安装ifconfig命令查看网络IP
RUN yum -y install net-tools
#安装java8及lib库
RUN yum -y install glibc.i686
RUN mkdir /usr/local/java
#ADD 是相对路径jar,把jdk-8u171-linux-x64.tar.gz添加到容器中/usr/local/java/下,安装包必须要和Dockerfile文件在同一位置
# 并且会自动进行解压
ADD jdk-8u171-linux-x64.tar.gz /usr/local/java/
#配置java环境变量
ENV JAVA_HOME /usr/local/java/jdk1.8.0_171
ENV JRE_HOME $JAVA_HOME/jre
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
ENV PATH $JAVA_HOME/bin:$PATH
EXPOSE 80
CMD echo $MYPATH
CMD echo "success--------------ok"
CMD /bin/bash
3、构建
docker build -t 新镜像名字:TAG . # 不要忘记TAG 后面有个空格和点

构建完成 !!!!
4、运行
docker run -it 7fb1bf90fced /bin/bash


三、虚悬镜像
3.1、是什么
仓库名、标签都是的镜像,俗称dangling image

查看虚悬镜像
docker image ls -f dangling=true
删除虚悬镜像
docker image prune

四、实战
通过 Dockerfile 发布一个简单的微服务到 Docker 容器
1、使用 Maven 将微服务打成 jar 包,发送到 Linux 中。

2、编写 Dockerfile
# 基础镜像使用java
FROM java:8
# 作者
MAINTAINER zzyy
# VOLUME 指定临时文件目录为/tmp,在主机/var/lib/docker目录下创建了一个临时文件并链接到容器的/tmp
VOLUME /tmp
# 将jar包添加到容器中并更名为zzyy_docker.jar
ADD docker_boot-0.0.1-SNAPSHOT.jar zzyy_docker.jar
# 运行jar包
RUN bash -c 'touch /zzyy_docker.jar'
ENTRYPOINT ["java","-jar","/zzyy_docker.jar"]
#暴露6001端口作为微服务
EXPOSE 6001
3、构建镜像
docker build -t yzg_docker:1.0 .
4、运行,并进行测试
docker run -d -p 6001:6001 yzg_docker:1.0
访问 : 192.168.200.132:6001/order/docker
五、Docker 网络
Docker 整体架构图

5.1、是什么?
先看看没有启动 docker 的网络情况:
ens33 是虚拟机的网卡,lo 是本地回环地址,virbr0 是虚拟网卡的地址,是用于 NAT 模式的虚拟网桥

启动docker后的网络情况:
docker0 就是Docker网络需要的网卡

查看 Docker 网络模式:
docker network ls
安装 Docker 后会默认安装三大网络模式

查看网络源数据 :
docker network inspect XXX网络名字
删除网络:
docker network rm XXX网络名字
创建一个新的网络:
默认就是 bridge 模式 : docker network create xxx网络名字
5.2、能干嘛
容器间的互联和通信以及端口映射
容器IP变动时候可以通过服务名直接网络通信而不受到影响
Docker 的网络模式:
bridge模式:使用 --network bridge指定,默认使用docker0。或者不指定默认就是 bridge
host模式:使用–network host指定
none模式:使用–network none指定
container模式:使用–network container:NAME或者容器ID指定
第一和第二种比较常用

容器内部 IP 生产默认规则:
新建俩个容器 u1,u2,查看IP 地址:
u1: 172.17.0.4
u2: 172.17.0.3


当我们删掉 u1 之后,在创建 u3 容器,。查看其 IP 地址:


最后发现, 容器内的 IP 地址是会发生变化的,因此 选择适合的网络模式还是很有必要的 !!!!
5.3、bridge
Docker 服务器会默认创建一个 docker0 的网桥,在之前也已经用 ifconfig 命令查看过了,这个网桥在内核层 连通了其他的物理或者虚拟网卡,将容器和本地主机都放到同一个物理网络 !! Docker 默认为 docker0 的网桥分配了 IP 地址和子网掩码,这样主机和容器就可以互相通信了

- Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
- docker run 的时候,没有指定network的话默认使用的网桥模式就是bridge,使用的就是docker0。在宿主机ifconfig,就可以看到docker0和自己create的network(后面讲)eth0,eth1,eth2……代表网卡一,网卡二,网卡三……,lo代表127.0.0.1,即localhost,inet addr用来表示网卡的IP地址
- 网桥docker0创建一对对等虚拟设备接口一个叫veth,另一个叫eth0,成对匹配。
- 整个宿主机的网桥模式都是docker0,类似一个交换机有一堆接口,每个接口叫veth,在本地主机和容器内分别创建一个虚拟接口,并让他们彼此联通(这样一对接口叫veth pair);
- 每个容器实例内部也有一块网卡,每个接口叫eth0;
- docker0上面的每个veth匹配某个容器实例内部的eth0,两两配对,一一匹配。
通过上述,将宿主机上的所有容器都连接到这个内部网络上,两个容器在同一个网络下,会从这个网关下各自拿到分配的ip,此时两个容器的网络是互通的
总结
Docker 启动时会自动创建一个 docker0 的网桥,该网桥类似交换机,有许多端口,这些个接口就是 veth,用于连接容器中的网卡 eth0 。
上面说了,bridge 模式下,每创建一个容器 Docker 都会根据 docker0 的网段 分配一个 IP 地址,网桥上的端口就会和容器的网卡 相连,达到通信的效果。
启动一个容器进行验证:

明显的可以看到,在主机上 veth 端口 和 8 相连, 在容器内部 eth0 的网卡 和 9相连。 俩俩配对 !!
5.4、host
直接使用宿主机的 IP 地址与外界进行通信,不再需要额外进行NAT 转换。
容器将不会获得一个独立的 Network Namespace, 而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡而是使用宿主机的IP和端口。

实例验证
启动一个 tomcat 容器:

出现警告的原因是 host 网络模式,使用了主机的 IP 和 端口,再去指定端口已经无意义。虽然不是报错,但是指定的端口是没有用的。默认使用主机的端口,重复时递增

默认使用 bridge 网络的情况:

5.5、none
在none模式下,并不为Docker容器进行任何网络配置。
也就是说,这个Docker容器没有网卡、IP、路由等信息,只有一个lo
需要我们自己为Docker容器添加网卡、配置IP等。

5.6、container
新建的容器和已经存在的一个容器共享一个网络ip配置而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的

当 alpine1 关机之后, alpine2 只剩下 一个 lo 本地地址
5.7、自定义网络
前面我们说,如果不使用自定义网络的话,无法按照服务名去 通信,如果用 IP 通信的话,容器内的 IP 是会变化的。

- 创建自定义网络
docker network create xxxx网络名字
- 在 RUN 的时候通过 --network 指定自定义的网络
自定义网络本身就维护好了主机名和ip的对应关系(ip和域名都能通)
六、Docker-compose容器编排
是什么?
Compose 是 Docker 公司推出的一个工具软件,可以管理多个 Docker 容器组成一个应用。你需要定义一个 YAML 格式的配置文件docker-compose.yml,写好多个容器之间的调用关系。然后,只要一个命令,就能同时启动/关闭这些容器
能干嘛?
-
docker建议我们每一个容器中只运行一个服务,因为docker容器本身占用资源极少,所以最好是将每个服务单独的分割开来但是这样我们又面临了一个问题?
-
如果我需要同时部署好多个服务,难道要每个服务单独写Dockerfile然后在构建镜像,构建容器,这样累都累死了,所以docker官方给我们提供了docker-compose多服务部署的工具
-
例如要实现一个Web微服务项目,除了Web服务容器本身,往往还需要再加上后端的数据库mysql服务容器,redis服务器,注册中心eureka,甚至还包括负载均衡容器等等。。。。。。
-
Compose允许用户通过一个单独的docker-compose.yml模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。
-
可以很容易地用一个配置文件定义一个多容器的应用,然后使用一条指令安装这个应用的所有依赖,完成构建。Docker-Compose 解决了容器与容器之间如何管理编排的问题。
下载
官网地址:https://docs.docker.com/compose/compose-file/compose-file-v3/
下载地址:https://docs.docker.com/compose/install/compose-plugin/
安装步骤:

curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 赋予权限
chmod +x /usr/local/bin/docker-compose
# 查看版本
docker-compose --version
compose 的核心概念:
- 一文件
- docker-compose.yml 文件
- 俩要素
- 服务:一个个应用容器实例,比如订单微服务、库存微服务、mysql容器、nginx容器或者redis容器
- 工程:多个服务组成,在 docker-compose.yml 文件中定义。
compose 的三个步骤:
- 编写Dockerfile定义各个微服务应用并构建出对应的镜像文件
- 使用 docker-compose.yml 定义一个完整业务单元,安排好整体应用中的各个容器服务。
- 最后,执行docker-compose up命令 来启动并运行整个应用程序,完成一键部署上线
compose 常用命令:
docker-compose -h # 查看帮助
docker-compose up # 启动所有docker-compose服务
docker-compose up -d # 启动所有docker-compose服务并后台运行
docker-compose down # 停止并删除容器、网络、卷、镜像。
docker-compose exec yml里面的服务id # 进入容器实例内部 docker-compose exec docker-compose.yml文件中写的服务id /bin/bash
docker-compose ps # 展示当前docker-compose编排过的运行的所有容器
docker-compose top # 展示当前docker-compose编排过的容器进程
docker-compose logs yml里面的服务id # 查看容器输出日志
docker-compose config # 检查配置
docker-compose config -q # 检查配置,有问题才有输出
docker-compose restart # 重启服务
docker-compose start # 启动服务
docker-compose stop # **停止服务**
6.1、案例演示
6.1.1、基础环境搭建
对之前的 docker_boot 进行一下改造:
1、SQL 语句,创建表
CREATE TABLE `t_user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL DEFAULT '' COMMENT '用户名',
`password` varchar(50) NOT NULL DEFAULT '' COMMENT '密码',
`sex` tinyint(4) NOT NULL DEFAULT '0' COMMENT '性别 0=女 1=男 ',
`deleted` tinyint(4) unsigned NOT NULL DEFAULT '0' COMMENT '删除标志,默认0不删除,1删除',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户表'
2、实体类,service 使用 MyBatisPlus-X 插件一键生成

3、POM 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.6</version>
<relativePath/>
</parent>
<groupId>com.atguigu.docker</groupId>
<artifactId>docker_boot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
<lombok.version>1.16.18</lombok.version>
<druid.version>1.1.16</druid.version>
<mapper.version>4.1.5</mapper.version>
</properties>
<dependencies>
<!--guava Google 开源的 Guava 中自带的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!--SpringBoot通用依赖模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--swagger2-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<!--SpringBoot与Redis整合依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--springCache-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!--springCache连接池依赖包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
<!--Mysql数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<!--SpringBoot集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<!--mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<!-- <!– 添加springboot对amqp的支持 –>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>-->
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.10</version>
</dependency>
<!--通用基础配置junit/devtools/test/log4j/lombok/hutool-->
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.2.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<optional>true</optional>
</dependency>
<!--persistence-->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>persistence-api</artifactId>
<version>1.0.2</version>
</dependency>
<!--通用Mapper-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>${mapper.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.1.0</version>
</plugin>
</plugins>
</build>
</project>
4、application 文件
server.port=6001
# ========================alibaba.druid相关配置=====================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.200.132::3306/db2022?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.druid.test-while-idle=false
# ========================redis相关配置=====================
#Redis服务器地址
spring.redis.host=192.168.200.132
#Redis服务器连接端口
spring.redis.port=6379
#Redis数据库索引(默认为0)
spring.redis.database= 0
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
# ========================swagger=====================
spring.swagger2.enabled=true
5、主启动类
@SpringBootApplication
@MapperScan("com.atguigu.docker.mapper")
public class DockerBootApplication {
public static void main(String[] args) {
SpringApplication.run(DockerBootApplication.class, args);
}
}
6、新建配置类RedisConfig + SwaggerConfig
@Configuration
public class RedisConfig {
/**
* @param lettuceConnectionFactory
* @return
*
* redis序列化的工具配置类,下面这个请一定开启配置
* 127.0.0.1:6379> keys *
* 1) "ord:102" 序列化过
* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,没有序列化过
*/
@Bean
public RedisTemplate<String, Serializable> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory)
{
RedisTemplate<String,Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
@Configuration
@EnableSwagger2
public class SwaggerConfig
{
@Value("${spring.swagger2.enabled}")
private Boolean enabled;
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.enable(enabled)
.select()
.apis(RequestHandlerSelectors.basePackage("com.atguigu.docker")) //你自己的package
.paths(PathSelectors.any())
.build();
}
public ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("尚硅谷Java大厂技术"+"\t"+new SimpleDateFormat("yyyy-MM-dd").format(new Date()))
.description("docker-compose")
.version("1.0")
.termsOfServiceUrl("https://www.atguigu.com/")
.build();
}
}
7、新建实体类 UserDTO
@NoArgsConstructor
@AllArgsConstructor
@Data
@ApiModel(value = "用户信息")
public class UserDTO implements Serializable
{
@ApiModelProperty(value = "用户ID")
private Integer id;
@ApiModelProperty(value = "用户名")
private String username;
@ApiModelProperty(value = "密码")
private String password;
@ApiModelProperty(value = "性别 0=女 1=男 ")
private Byte sex;
@ApiModelProperty(value = "删除标志,默认0不删除,1删除")
private Byte deleted;
@ApiModelProperty(value = "更新时间")
private Date updateTime;
@ApiModelProperty(value = "创建时间")
private Date createTime;
/**
* @return id
*/
public Integer getId() {
return id;
}
/**
* @param id
*/
public void setId(Integer id) {
this.id = id;
}
/**
* 获取用户名
*
* @return username - 用户名
*/
public String getUsername() {
return username;
}
/**
* 设置用户名
*
* @param username 用户名
*/
public void setUsername(String username) {
this.username = username;
}
/**
* 获取密码
*
* @return password - 密码
*/
public String getPassword() {
return password;
}
/**
* 设置密码
*
* @param password 密码
*/
public void setPassword(String password) {
this.password = password;
}
/**
* 获取性别 0=女 1=男
*
* @return sex - 性别 0=女 1=男
*/
public Byte getSex() {
return sex;
}
/**
* 设置性别 0=女 1=男
*
* @param sex 性别 0=女 1=男
*/
public void setSex(Byte sex) {
this.sex = sex;
}
/**
* 获取删除标志,默认0不删除,1删除
*
* @return deleted - 删除标志,默认0不删除,1删除
*/
public Byte getDeleted() {
return deleted;
}
/**
* 设置删除标志,默认0不删除,1删除
*
* @param deleted 删除标志,默认0不删除,1删除
*/
public void setDeleted(Byte deleted) {
this.deleted = deleted;
}
/**
* 获取更新时间
*
* @return update_time - 更新时间
*/
public Date getUpdateTime() {
return updateTime;
}
/**
* 设置更新时间
*
* @param updateTime 更新时间
*/
public void setUpdateTime(Date updateTime) {
this.updateTime = updateTime;
}
/**
* 获取创建时间
*
* @return create_time - 创建时间
*/
public Date getCreateTime() {
return createTime;
}
/**
* 设置创建时间
*
* @param createTime 创建时间
*/
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", sex=" + sex +
'}';
}
}
8、UserService
@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* addUser
* @param user
*/
public void addUser(User user)
{
//1 先插入mysql并成功
int i = userMapper.insertSelective(user);
if(i > 0)
{
//2 需要再次查询一下mysql将数据捞回来并ok
user = userMapper.selectByPrimaryKey(user.getId());
//3 将捞出来的user存进redis,完成新增功能的数据一致性。
String key = CACHE_KEY_USER+user.getId();
redisTemplate.opsForValue().set(key,user);
}
}
/**
* findUserById
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
}
9、Controller 层
@RestController
public class UserController {
@Resource
private UserService userService;
@ApiOperation("数据库新增3条记录")
@RequestMapping(value = "/user/add", method = RequestMethod.POST)
public void addUser() {
for (int i = 1; i <= 3; i++) {
User user = new User();
user.setUsername("zzyy" + i);
user.setPassword(IdUtil.simpleUUID().substring(0, 6));
user.setSex((int) new Random().nextInt(2));
userService.addUser(user);
}
}
10、使用 maven 命令打包成 jar 包,传送到 /mydocker 目录下

11、编写 Dockerfile 文件
# 基础镜像使用java
FROM java:8
# 作者
MAINTAINER yzg
# VOLUME 指定临时文件目录为/tmp,在主机/var/lib/docker目录下创建了一个临时文件并链接到容器的/tmp
VOLUME /tmp
# 将jar包添加到容器中并更名为yzg_docker.jar
ADD docker_boot-0.0.1-SNAPSHOT.jar yzg_docker.jar
# 运行jar包
RUN bash -c 'touch /zzyy_docker.jar'
ENTRYPOINT ["java","-jar","/yzg_docker.jar"]
#暴露6001端口作为微服务
EXPOSE 6001
12、构建镜像
docker build -t yzg_docker:1.0 .
6.1.2、不使用 Compose
- 创建 mysql 容器
- 创建 Redis 容器
- 创建微服务容器
创建MYSQL容器:
1、创建 mysql容器
docker run -p 3306:3306 --name mysql57 --privileged=true -v /yzguse/mysql/conf:/etc/mysql/conf.d -v /yzguse/mysql/logs:/logs -v /yzguse/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=1234 -d mysql:5.7
出现 listen tcp4 0.0.0.0:3306: bind: address already in use 错误,检查你的 Linux主机的mysql服务是否开启,如果开启关掉就好了。
2、进入容器,进入 mysql 创建 t_user表
docker exec -it mysql57 bash
mysql -uroot -p
CREATE TABLE `t_user` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`username` VARCHAR(50) NOT NULL DEFAULT '' COMMENT '用户名',
`password` VARCHAR(50) NOT NULL DEFAULT '' COMMENT '密码',
`sex` TINYINT(4) NOT NULL DEFAULT '0' COMMENT '性别 0=女 1=男 ',
`deleted` TINYINT(4) UNSIGNED NOT NULL DEFAULT '0' COMMENT '删除标志,默认0不删除,1删除',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
创建 Redis 容器:
1、启动
docker run -p 6379:6379 --name redis608 --privileged=true -v /yzg/app/redis/redis.conf:/etc/redis/redis.conf -v /yzg/app/redis/data:/data -d redis:6.0.8 redis-server /etc/redis/redis.conf
2、连接客户端
redis-cli -p 6379
创建微服务容器
docker run -d -p 6001:6001 yzg_docker:1.0
使用 Swagger 测试: 往数据库增加数据
http://localhost:你的微服务端口/swagger-ui.html#/

6.1.3、使用 Compose
以上那种方式的缺点:
- RUN 命令太多,如果有更多的容器,太麻烦
- 容器间的启停或宕机,有可能导致IP地址对应的容器实例变化,映射出错,
要么生产IP写死(可以但是不推荐),要么通过服务调用
1、在 /mydocker 目录下创建 docker-compose.yaml 文件
version: "3" #版本
services:
# 定义服务名字 microService,只要不冲突即可
microService:
# 镜像名字
image: yzg_docker:1.6
# 自定义容器名字
container_name: ms01
ports:
- "6001:6001"
# 容器数据卷
volumes:
# 挂载目录
- /app/microService:/data
# 网络模式
networks:
- atguigu_net
# 依赖于哪个服务
depends_on:
- redis
- mysql
redis:
image: redis:6.0.8
ports:
- "6379:6379"
volumes:
- /app/redis/redis.conf:/etc/redis/redis.conf
- /app/redis/data:/data
networks:
- atguigu_net
command: redis-server /etc/redis/redis.conf
mysql:
image: mysql:5.7
environment:
# 这个密码是和你的application中配置的一致
MYSQL_ROOT_PASSWORD: '123456'
MYSQL_ALLOW_EMPTY_PASSWORD: 'no'
MYSQL_DATABASE: 'db2022'
MYSQL_USER: 'root'
MYSQL_PASSWORD: '1234'
ports:
- "3306:3306"
volumes:
- /app/mysql/db:/var/lib/mysql
- /app/mysql/conf/my.cnf:/etc/my.cnf
- /app/mysql/init:/docker-entrypoint-initdb.d
networks:
- atguigu_net
command: --default-authentication-plugin=mysql_native_password #解决外部无法访问
networks:
atguigu_net:
2、修改 application.properties ,将固定 IP 改成服务名

3、打包,生成镜像image

4、构建镜像
docker build -t yzg_docker:1.1 .
5、容器编排
# 编排前可检查一下配置文件,如果没有任何东西输出就没有问题
docker-compose config -q
# 编排
docker-compose up

6、在 mysql 中键数据库 db2022和 t_user 表。最后进行测试即可

7、查询数据库和redis是否有数据
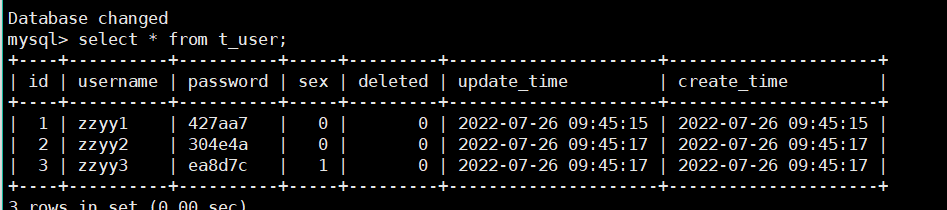

总结:
对微服务进行编排总体步骤:
- 生成 jar 包,放在 Linux 上
- 在 jar 包同目录下,编写 Dockerfile 文件,生成镜像images
- 在 jar 包同目录下,编写docker-compose.yml 文件
- 最终 docker-compose up -d 编排容器
七、Portainer 可视化工具
Portainer 是一款轻量级的应用,它提供了图形化界面,用于方便地管理Docker环境,包括单机环境和集群环境。【监控、统计】
安装:
官网:https://www.portainer.io/
安装命令:
docker run -d -p 8000:8000 -p 9000:9000 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer # --restart=always 表示:如果重启了Docker 该容器也不会丢失。如果不加,重启之后,容器丢失了第一次访问:IP地址:9000
第一次访问需要创建用户:


图形化界面下载 Nginx

可以增加容器卷、网络等参数:

安装完即可访问:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











