










Prometheus (普罗米修斯)是一款基于时序数据库的开源监控告警系统,说起 Prometheus 则不得不提 SoundCloud,这是一个在线音乐分享的平台,类似于做视频分享的 YouTube,由于他们在微服务架构的道路上越走越远,出现了成百上千的服务,使用传统的监控系统 StatsD 和 Graphite 存在大量的局限性。
于是他们在 2012 年开始着手开发一套全新的监控系统。Prometheus 的原作者是 Matt T. Proud,他也是在 2012 年加入 SoundCloud 的,实际上,在加入 SoundCloud 之前,Matt 一直就职于 Google,他从 Google 的集群管理器 Borg 和它的监控系统 Borgmon 中获取灵感,开发了开源的监控系统 Prometheus,和 Google 的很多项目一样,使用的编程语言是 Go。
很显然,Prometheus 作为一个微服务架构监控系统的解决方案,它和容器也脱不开关系。早在 2006 年 8 月 9 日,Eric Schmidt 在搜索引擎大会上首次提出了云计算(Cloud Computing)的概念,在之后的十几年里,云计算的发展势如破竹。
在 2013 年,Pivotal 的 Matt Stine 又提出了云原生(Cloud Native)的概念,云原生由微服务架构、DevOps 和以容器为代表的敏捷基础架构组成,帮助企业快速、持续、可靠、规模化地交付软件。
为了统一云计算接口和相关标准,2015 年 7 月,隶属于 Linux 基金会的 云原生计算基金会(CNCF,Cloud Native Computing Foundation) 应运而生。第一个加入 CNCF 的项目是 Google 的 Kubernetes,而 Prometheus 是第二个加入的(2016 年)。
目前 Prometheus 已经广泛用于 Kubernetes 集群的监控系统中,对 Prometheus 的历史感兴趣的同学可以看看 SoundCloud 的工程师 Tobias Schmidt 在 2016 年的 PromCon 大会上的演讲:The History of Prometheus at SoundCloud 。
1 Prometheus 概述
我们在 SoundCloud 的官方博客中可以找到一篇关于他们为什么需要新开发一个监控系统的文章 Prometheus: Monitoring at SoundCloud,在这篇文章中,他们介绍到,他们需要的监控系统必须满足下面四个特性:
- A multi-dimensional data model, so that data can be sliced and diced at will, along dimensions like instance, service, endpoint, and method.
- Operational simplicity, so that you can spin up a monitoring server where and when you want, even on your local workstation, without setting up a distributed storage backend or reconfiguring the world.
- Scalable data collection and decentralized architecture, so that you can reliably monitor the many instances of your services, and independent teams can set up independent monitoring servers.
- Finally, a powerful query language that leverages the data model for meaningful alerting (including easy silencing) and graphing (for dashboards and for ad-hoc exploration).
简单来说,就是下面四个特性:
- 多维度数据模型
- 方便的部署和维护
- 灵活的数据采集
- 强大的查询语言
实际上,多维度数据模型和强大的查询语言这两个特性,正是时序数据库所要求的,所以 Prometheus 不仅仅是一个监控系统,同时也是一个时序数据库。那为什么 Prometheus 不直接使用现有的时序数据库作为后端存储呢?这是因为 SoundCloud 不仅希望他们的监控系统有着时序数据库的特点,而且还需要部署和维护非常方便。
纵观比较流行的时序数据库(参见下面的附录),他们要么组件太多,要么外部依赖繁重,比如:Druid 有 Historical、MiddleManager、Broker、Coordinator、Overlord、Router 一堆的组件,而且还依赖于 ZooKeeper、Deep storage(HDFS 或 S3 等),Metadata store(PostgreSQL 或 MySQL),部署和维护起来成本非常高。而 Prometheus 采用去中心化架构,可以独立部署,不依赖于外部的分布式存储,你可以在几分钟的时间里就可以搭建出一套监控系统。
此外,Prometheus 数据采集方式也非常灵活。要采集目标的监控数据,首先需要在目标处安装数据采集组件,这被称之为 Exporter,它会在目标处收集监控数据,并暴露出一个 HTTP 接口供 Prometheus 查询,Prometheus 通过 Pull 的方式来采集数据,这和传统的 Push 模式不同。
不过 Prometheus 也提供了一种方式来支持 Push 模式,你可以将你的数据推送到 Push Gateway,Prometheus 通过 Pull 的方式从 Push Gateway 获取数据。目前的 Exporter 已经可以采集绝大多数的第三方数据,比如 Docker、HAProxy、StatsD、JMX 等等,官网有一份 Exporter 的列表。
除了这四大特性,随着 Prometheus 的不断发展,开始支持越来越多的高级特性,比如:服务发现,更丰富的图表展示,使用外部存储,强大的告警规则和多样的通知方式。
下图是 Prometheus 的整体架构图:
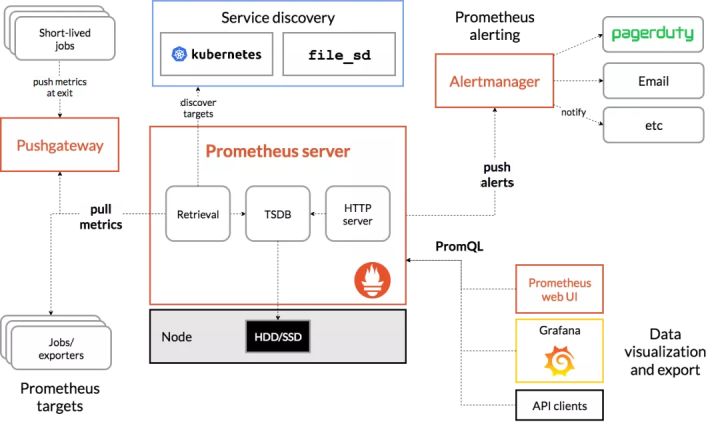
从上图可以看出,Prometheus 生态系统包含了几个关键的组件:Prometheus server、Pushgateway、Alertmanager、Web UI 等,但是大多数组件都不是必需的,其中最核心的组件当然是 Prometheus server,它负责收集和存储指标数据,支持表达式查询,和告警的生成。
我理解它主要分为三个部分:采集层、数据处理层、数据查询层
采集层
数据的采集之前,首先需要解决的是采集目标是怎样知道的,Prometheus 提供了比较丰富的采集目标发现机制,比如基于配置文件的发现机制,基于 Kubernetes 的发现机制等等。对于数据采集的方式,主要分为两种方式,一种是 exporter 的 pull 机制,是指应用本身暴露能获取监控指标能力的接口,或者特定能采集应用数据的 exporter,然后 Prometheus server 通过访问 exporter 获取到监控数据信息,这种方式是主流的使用方式,也就是 pull 模式。另一种是通过 Push Gateway 的 push 机制,是用户主动将数据推送到 Push Gateway 组件,然后 Prometheus server 通过 Push Gateway 获取到数据,这种是比较传统的 push 模式。
数据处理层
数据处理层主要是指 Prometheus server 本身,主要分为三个部分,Retrieval 负责定时去暴露监控指标的目标上抓取数据,Storage 负责将数据写入磁盘,promQL 暴露查询数据的 http server 能力。同时他也会根据告警规则,一旦达到阈值,那么就会向 Alertmanager 推送告警信息,然后由 Alertmanager 对接到外部平台,将应用异常信息推送给用户。
数据查询层
数据查询层是指,可以通过 Prometheus UI 访问 Prometheus server 能力。或者结合 Grafana,将 Prometheus 作为数据源接入,在 Grafana 自定义模版,以图表的方式展示应用指标的状态变化,以便于更加直观地观测应用的变化。
2. 安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
从二进制包安装
对于非Docker用户,可以从https://prometheus.io/download/ 找到最新版本的Prometheus Sevrer软件包:
export VERSION=2.32.1
curl -LO https://github.com/prometheus/prometheus/releases/download/v$VERSION/prometheus-$VERSION.darwin-amd64.tar.gz
解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-${VERSION}.darwin-amd64.tar.gz
cd prometheus-${VERSION}.darwin-amd64
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数--storage.tsdb.path="data/"修改本地数据存储的路径,还可以通过参数--config.file=prometheus.yml修改配置文件路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件:
./prometheus
创建Systemd服务
vi /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
Group=root
WorkingDirectory=/opt/prometheus-2.28.0
ExecStart=/opt/prometheus-2.28.0/prometheus \
--web.listen-address=localhost:9090 \
--storage.tsdb.path="/mnt/data/prometheus" \
--config.file=prometheus.yml
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
正常的情况下,你可以看到以下输出内容:
level=info ts=2021-12-23T14:55:14.499484Z caller=main.go:554 msg="Starting TSDB ..."
level=info ts=2021-12-23T14:55:14.499531Z caller=web.go:397 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-12-23T14:55:14.507999Z caller=main.go:564 msg="TSDB started"
level=info ts=2021-12-23T14:55:14.508068Z caller=main.go:624 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2021-12-23T14:55:14.509509Z caller=main.go:650 msg="Completed loading of configuration file" filename=prometheus.yml
level=info ts=2021-12-23T14:55:14.509537Z caller=main.go:523 msg="Server is ready to receive web requests."
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server:
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
启动完成后,可以通过http://localhost:9090 访问Prometheus的UI界面:
3. 使用Node Exporter采集主机数据
3.1 安装Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从上面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
https://github.com/prometheus/node_exporter/releases/
curl -OL https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.darwin-amd64.tar.gz
tar -xzf node_exporter-1.3.1.darwin-amd64.tar.gz
3.2 运行node exporter:
cp node_exporter-1.3.1.darwin-amd64/node_exporter /usr/local/bin/node_exporter
# 指定端口启动
node_exporter --web.listen-address=":9500"
启动成功后,可以看到以下输出:
INFO[0000] Listening on :9100 source="node_exporter.go:76"
创建Systemd服务
cat > /etc/systemd/system/node_exporter.service << EOF
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
访问http://localhost:9100/ 可以看到以下页面:
注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter \
--path.rootfs /host
关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
4. 初始Node Exporter监控指标
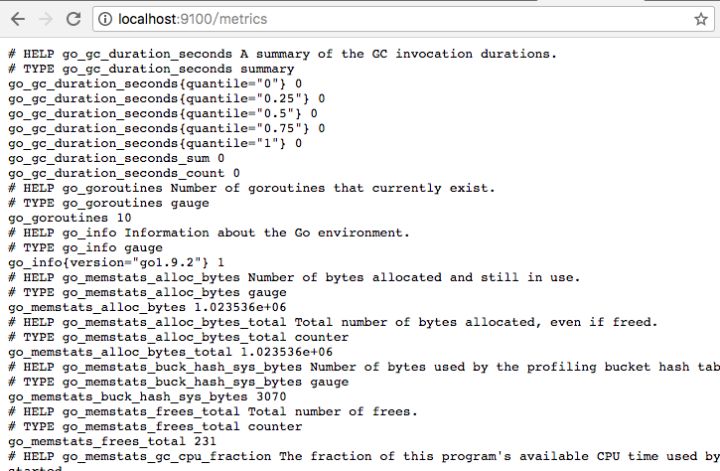
访问 http://localhost:9100/metrics ,可以看到当前node exporter获取到的当前主机的所有监控数据,如下所示:
主机监控指标
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统CPU使用量
- nodedisk*:磁盘IO
- nodefilesystem*:文件系统用量
- node_load1:系统负载
- nodememeory*:内存使用量
- nodenetwork*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
5. 从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
重新启动Prometheus Server
访问 http://localhost:9090 ,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
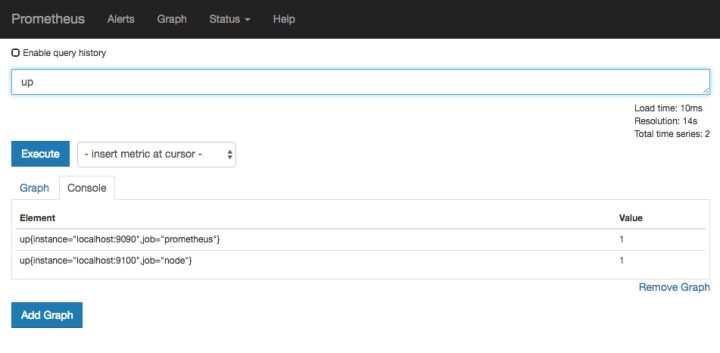
如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1
up{instance="localhost:9100",job="node"} 1
其中“1”表示正常,反之“0”则为异常。
6. 使用PromQL查询监控数据
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据:
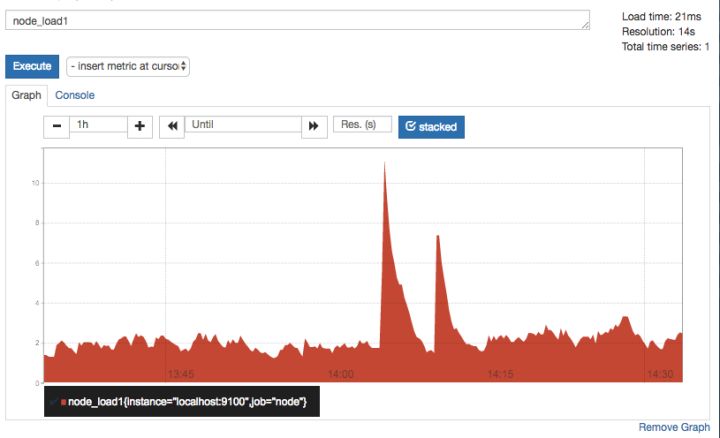
切换到Graph面板,用户可以使用PromQL表达式查询特定监控指标的监控数据。如下所示,查询主机负载变化情况,可以使用关键字node_load1可以查询出Prometheus采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
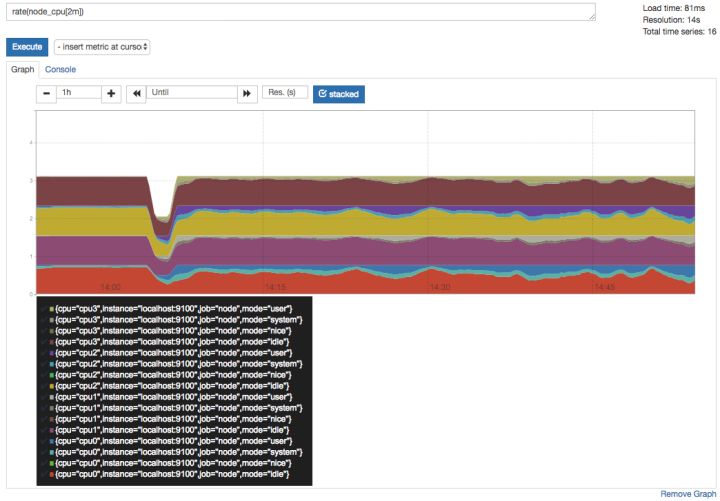
PromQL是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用rate()函数,可以计算在单位时间内样本数据的变化情况即增长率,因此通过该函数我们可以近似的通过CPU使用时间计算CPU的利用率:
rate(node_cpu[2m])
这时如果要忽略是哪一个CPU的,只需要使用without表达式,将标签CPU去除后聚合数据即可:
avg without(cpu) (rate(node_cpu[2m]))
那如果需要计算系统CPU的总体使用率,通过排除系统闲置的CPU使用率即可获得:
- avg without(cpu) (rate(node_cpu{mode="idle"}[2m]))
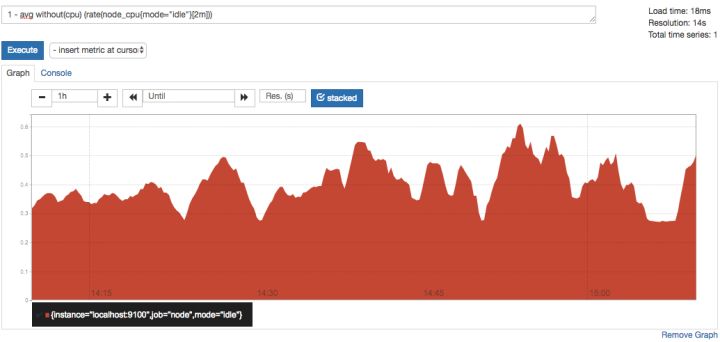
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达书语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。
7. 监控数据可视化
虽然 Prometheus 提供的 Web UI 也可以很好的查看不同指标的视图,但是这个功能非常简单,只适合用来调试。要实现一个强大的监控系统,还需要一个能定制展示不同指标的面板,能支持不同类型的展现方式(曲线图、饼状图、热点图、TopN 等),这就是仪表盘(Dashboard)功能。
因此 Prometheus 开发了一套仪表盘系统 PromDash,不过很快这套系统就被废弃了,官方开始推荐使用 Grafana 来对 Prometheus 的指标数据进行可视化,这不仅是因为 Grafana 的功能非常强大,而且它和 Prometheus 可以完美的无缝融合。
Grafana 是一个用于可视化大型测量数据的开源系统,它的功能非常强大,界面也非常漂亮,使用它可以创建自定义的控制面板,你可以在面板中配置要显示的数据和显示方式,它 支持很多不同的数据源,比如:Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus 等,而且它也 支持众多的插件。
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana
访问 http://localhost:3000 就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
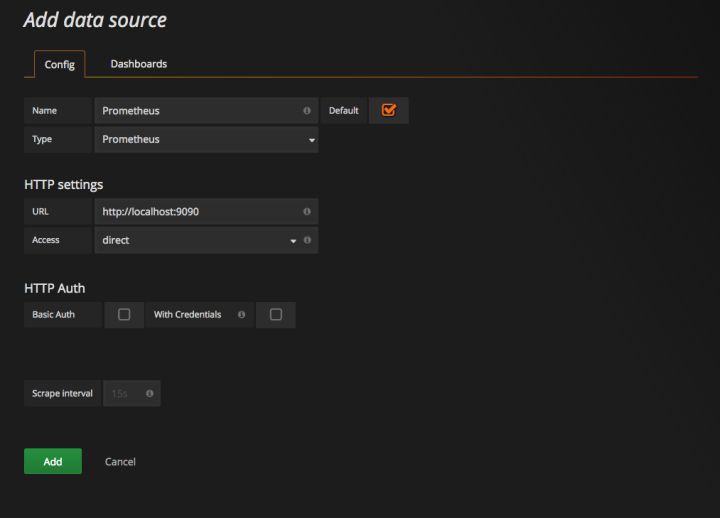
我们在这里依次填上:
- Name: prometheus
- Type: Prometheus
- URL: http://localhost:9090
- Access: Browser
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是 /api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
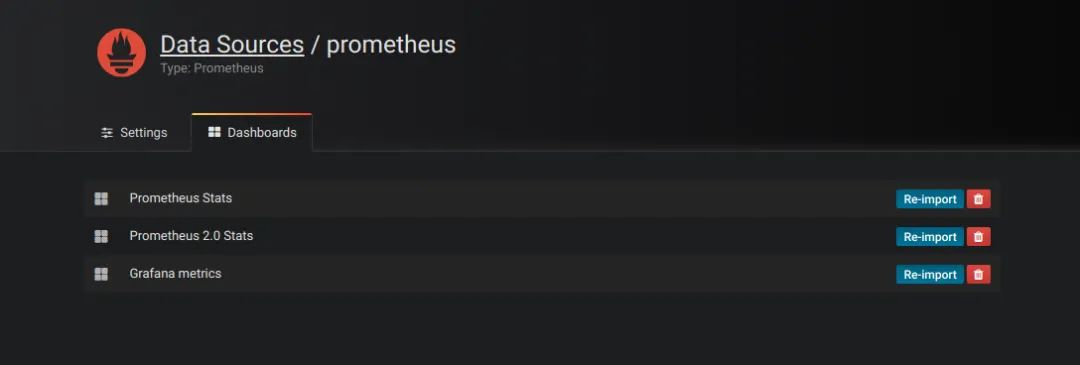
配置好数据源,Grafana 会默认提供几个已经配置好的面板供你使用,如下图所示,默认提供了三个面板:Prometheus Stats、Prometheus 2.0 Stats 和 Grafana metrics。点击 Import 就可以导入并使用该面板。
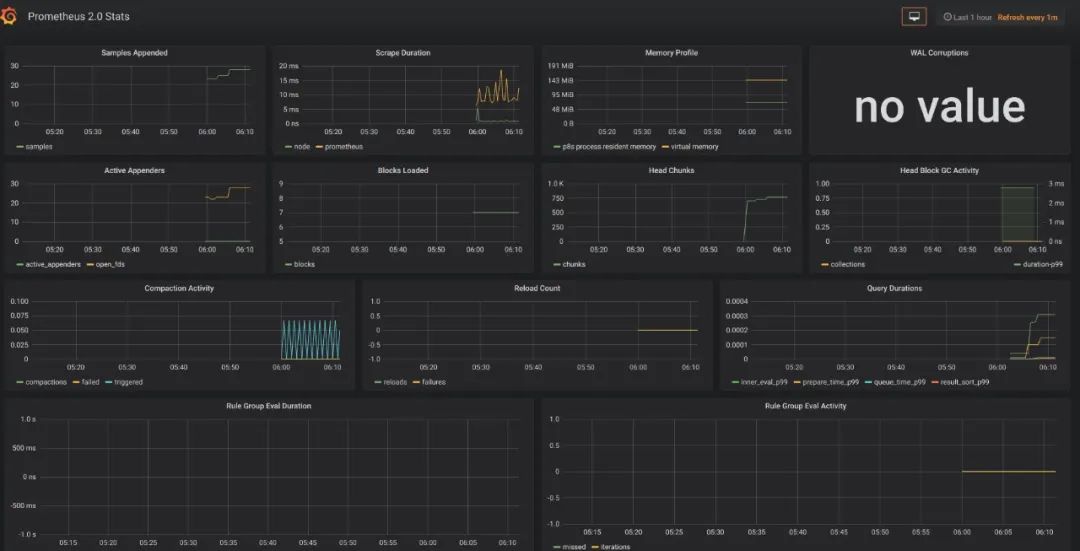
我们导入 Prometheus 2.0 Stats 这个面板,可以看到下面这样的监控面板。如果你的公司有条件,可以申请个大显示器挂在墙上,将这个面板投影在大屏上,实时观察线上系统的状态,可以说是非常 cool 的。
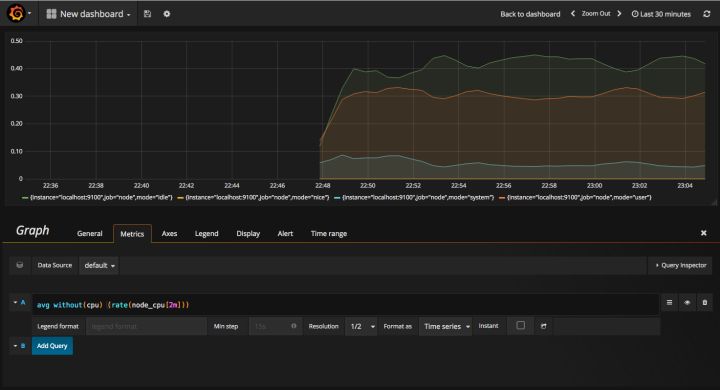
在完成数据源的添加之后还可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个类型为“Graph”的面板。 并在该面板的“Metrics”选项下通过PromQL查询需要可视化的数据:
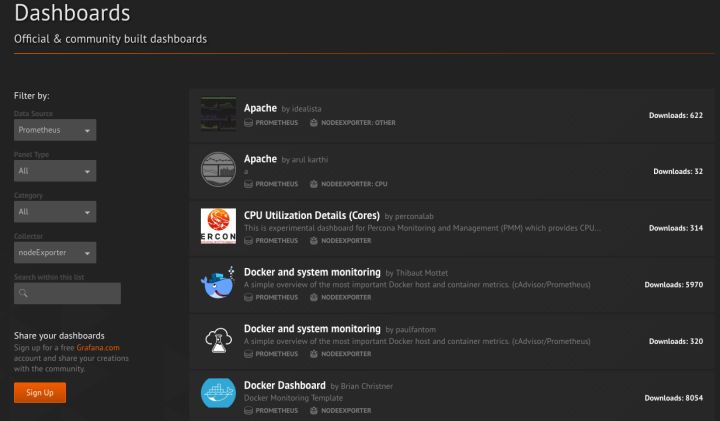
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:
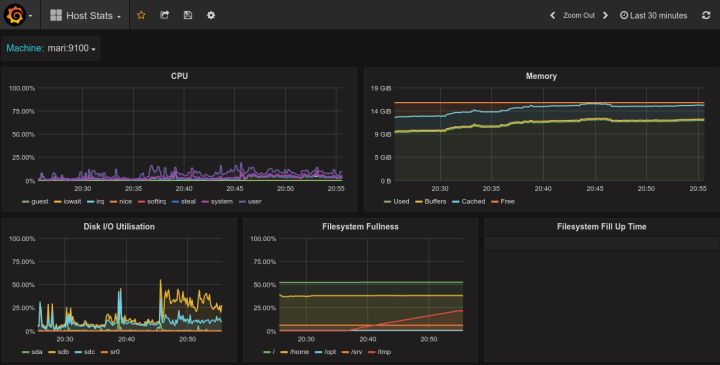
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
8.任务和实例
在上一小节中,通过在prometheus.yml配置文件中,添加如下配置。我们让Prometheus可以从node exporter暴露的服务中获取监控指标数据。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
当我们需要采集不同的监控指标(例如:主机、MySQL、Nginx)时,我们只需要运行相应的监控采集程序,并且让Prometheus Server知道这些Exporter实例的访问地址。在Prometheus中,每一个暴露监控样本数据的HTTP服务称为一个实例。例如在当前主机上运行的node exporter可以被称为一个实例(Instance)。
而一组用于相同采集目的的实例,或者同一个采集进程的多个副本则通过一个一个任务(Job)进行管理。
* job: node
* instance 2: 1.2.3.4:9100
* instance 4: 5.6.7.8:9100
当前在每一个Job中主要使用了静态配置(static_configs)的方式定义监控目标。除了静态配置每一个Job的采集Instance地址以外,Prometheus还支持与DNS、Consul、E2C、Kubernetes等进行集成实现自动发现Instance实例,并从这些Instance上获取监控数据。
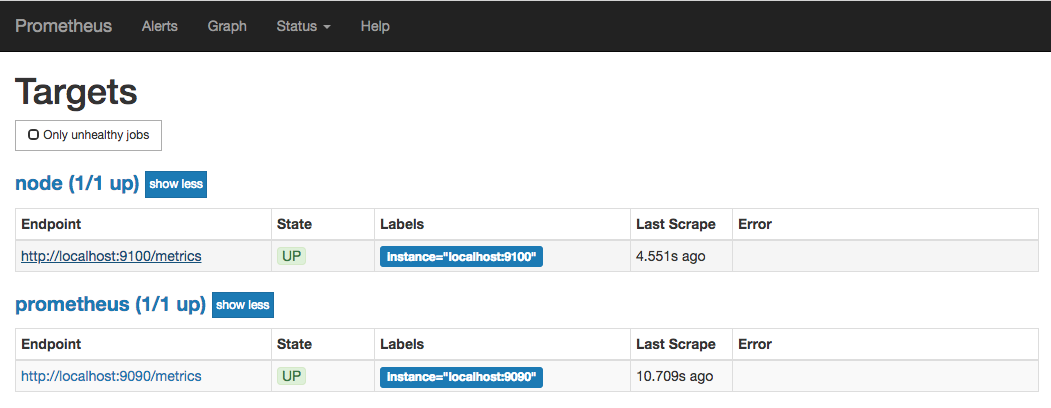
除了通过使用“up”表达式查询当前所有Instance的状态以外,还可以通过Prometheus UI中的Targets页面查看当前所有的监控采集任务,以及各个任务下所有实例的状态:

我们也可以访问http://192.168.33.10:9090/targets直接从Prometheus的UI中查看当前所有的任务以及每个任务对应的实例信息。
9.Prometheus核心组件
上一小节,通过部署Node Exporter我们成功的获取到了当前主机的资源使用情况。接下来我们将从Prometheus的架构角度详细介绍Prometheus生态中的各个组件。
下图展示Prometheus的基本架构:
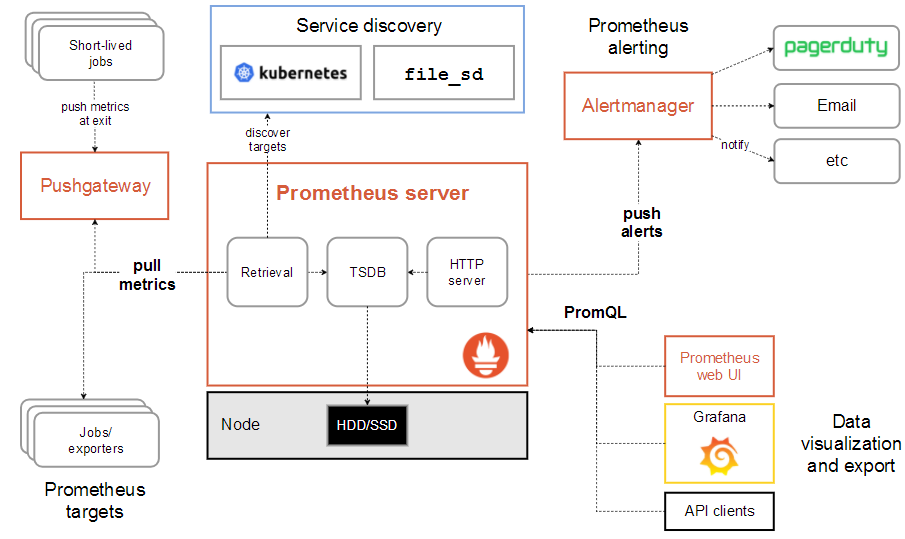
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
参考
自从上了Prometheus,睡觉真香!https://mp.weixin.qq.com/s/tcDn5p-B-c7cV1-GP2pLnQ
https://yunlzheng.gitbook.io/prometheus-book/














 5771
5771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









