








开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@qqq,@鲍勃
01有话题的技术
1、Zyphra 发布 Zonos-v0.1:领先的开源文本到语音模型,支持多语言和高保真声音克隆
Zyphra 发布的 Zonos-v0.1 是领先的开放权重文本到语音模型,提供与顶级 TTS 提供商相当甚至更出色的表现力和质量。它能够在给定说话人嵌入或音频前缀的情况下,从文本提示生成高度自然化的语音。只需 5 到 30 秒的语音,Zonos 就能实现高保真度的声音克隆。它还允许根据说话速度、音调变化、音频质量和悲伤、恐惧、愤怒、快乐和喜悦等情绪进行条件化。该模型以 44kHz 的采样率原生输出语音。
主要功能:
-
零样本语音克隆 TTS:输入所需文本和 10-30 秒的说话人样本,生成高质量的 TTS 输出
-
音频前缀输入:添加文本和音频前缀,以实现更丰富的说话人匹配。音频前缀可用于引发如耳语等难以从纯语音克隆中获得的举止
-
多语言支持:Zonos-v0.1 支持英语、日语、中文、法语和德语
-
音频质量和情感控制:Zonos 提供了对生成音频许多方面的精细控制。这包括说话速度、音调、最大频率、音频质量以及各种情感,如快乐、愤怒、悲伤和恐惧。
-
速度快:模型在 RTX 4090 上运行时,实时性因子约为 2 倍
-
WebUI gradio 界面:Zonos 附带了一个易于使用的 gradio 界面,用于生成语音
-
简单安装和部署:Zonos 可以通过使用仓库中打包的 Docker 文件简单安装和部署。
(@Hugging Face)
2、北航推出开源 TinyLLaVA-Video 模型:小尺寸多模态视频理解框架
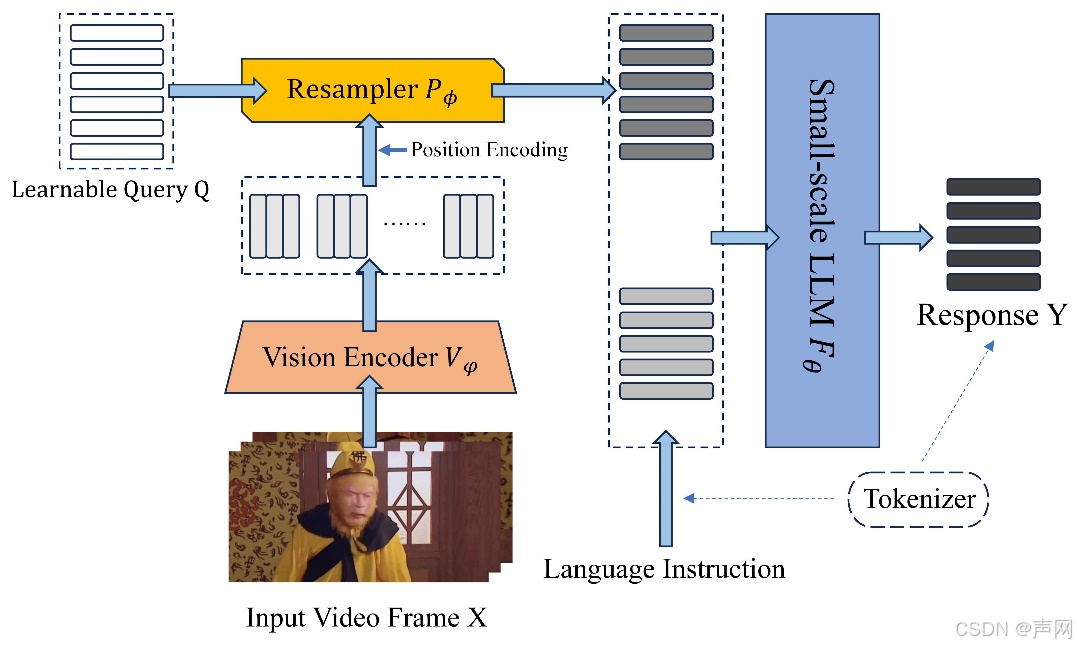
北京航空航天大学的研究团队最近发布了一个名为 TinyLLaVA-Video 的开源视频理解框架。该框架基于 TinyLLaVA_Factory 项目,专为计算资源有限的环境设计&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









