






一、准备工作
本篇文章所使用的缩写总结如下表。

Markov决策过程(MDP)被定义为元组(S,A,P,R,T),其中S和A是有限的有效状态集和所有有效动作的有限集。函数P : S×A→ P(S)是转移概率函数,其中P(st+1 | st, at)表示在时间t+1进入状态st+1的概率,如果智能体在时间t在状态st执行一个动作at。函数R : S×A×S→ R是奖励函数,其中Rt = R(st, at, st+1)。具有有限时间视图的MDP解决找到参数化的πθ政策∈Π,其中π是由θ参数化的(例如神经网络的权重)。政策πθ确定在每个状态下必须执行的动作a ∈ A,以最大化智能体在有限时间间隔T内接收到的状态转移的折扣累积奖励。在传统的Q学习算法中,πθ政策依赖于Q(st, at)的值-即Q值,它定义了智能体在状态st中选择动作at的好坏。Q值定义为折扣累积未来奖励如下:Q(st, at) = E[[1]ti=0 γiRt+1+i|s = st, a = at]。在此Q值表达式中,γ ∈ [0, 1]是一个折扣因子,它编码了现在和未来奖励的相对重要性。Q学习的目标是识别最大化Q(st, at)的θ参数的π∗θ最优策略,其中t代表终端状态的时刻。
二、深度强化学习
A2C是一种现代的深度强化学习(DRL)方法,它从动作-评判的概念中脱颖而出。A2C通过适应基线,即优势,来提高DRL算法的性能和稳定性,该优势定义为Aπθ(st, at) = Qπθ(st, at) - Vπθ(st)。这里,Aπθ(st, at)和Qπθ(st, at)代表在智能体在状态st下根据策略πθ选择动作at时的优势和Q值。Vπθ(st)表示在策略πθ下状态st的值,它被定义为智能体将在状态st中获得的折扣累积未来奖励的期望值:Vπθ(st) = E[Rt+1 + γRt+2 + γ2Rt+3 + ···|s = st]。使用优势的目的是减少学习过程中的方差并改善智能体学习过程的收敛性能。A2C方法的目的是最小化损失函数,该损失函数是动作网络和评判网络对应的Lactor t(θ)和Lcritic t(θ)两个不同的损失函数的总和。
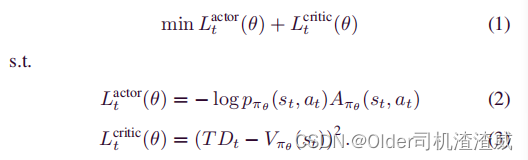
在(2)中,pπθ(st, at)是在时间t在状态st下根据策略πθ选择行动at的概率。在(3)中,T Dt = Rt+1 + γVπθ (st+1)是评判家网络的的目标值,可以通过使用时序差分(TD)方法[25]来更新神经网络权重θ以获得该目标值。
三、联邦强化学习
FRL是一种有希望的机器学习方法,它以分布式方式训练本地设备的神经网络模型,而不共享本地数据。FRL的训练过程包括本地模型的训练和更新本地模型的全球聚合。设N = {1, 2,...N}是一组N个本地设备。每个设备n使用其自己的数据集Dn进行训练并构建自己的模型ωi。在每个本地设备的训练过程完成后,其模型被传输并聚合到一个全局系统中,以估计所有本地设备的全局模型ωG,表示如下:ωG = f(ω1, ω2,...,ωN )。这个全局模型ωG然后广播到所有本地设备,其模型被ωG替换:ωG = ω1 = ω2 ... = ωN。最后,每个本地设备基于全局模型ωG重新开始训练,直到它们都获得所需的模型。在传统的分布式深度强化学习模型中,全局系统必须访问所有本地设备的数据以生成全局系统的深度强化学习模型。这种方法引发了本地设备的数据隐私问题。然而,在FRL方法中,全局系统不需要共享本地数据。因此,FRL可以保护本地数据的隐私。
















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











