







一、引言
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过与环境交互来学习最佳行为策略。DDPG(Deep Deterministic Policy Gradient)算法是一种基于深度学习的强化学习算法,适用于连续动作空间的问题。DDPG结合了策略梯度方法(Policy Gradient)和值函数方法(Value Function),使用深度神经网络(Deep Neural Networks, DNN)来近似策略函数和值函数。
本文将详细介绍DDPG算法的结构图、算法流程、计算处理过程、主要公式,并给出一个Matlab代码示例和效果图。代码示例将不使用深度学习工具箱,而是使用基本的Matlab函数和自定义神经网络类来实现。
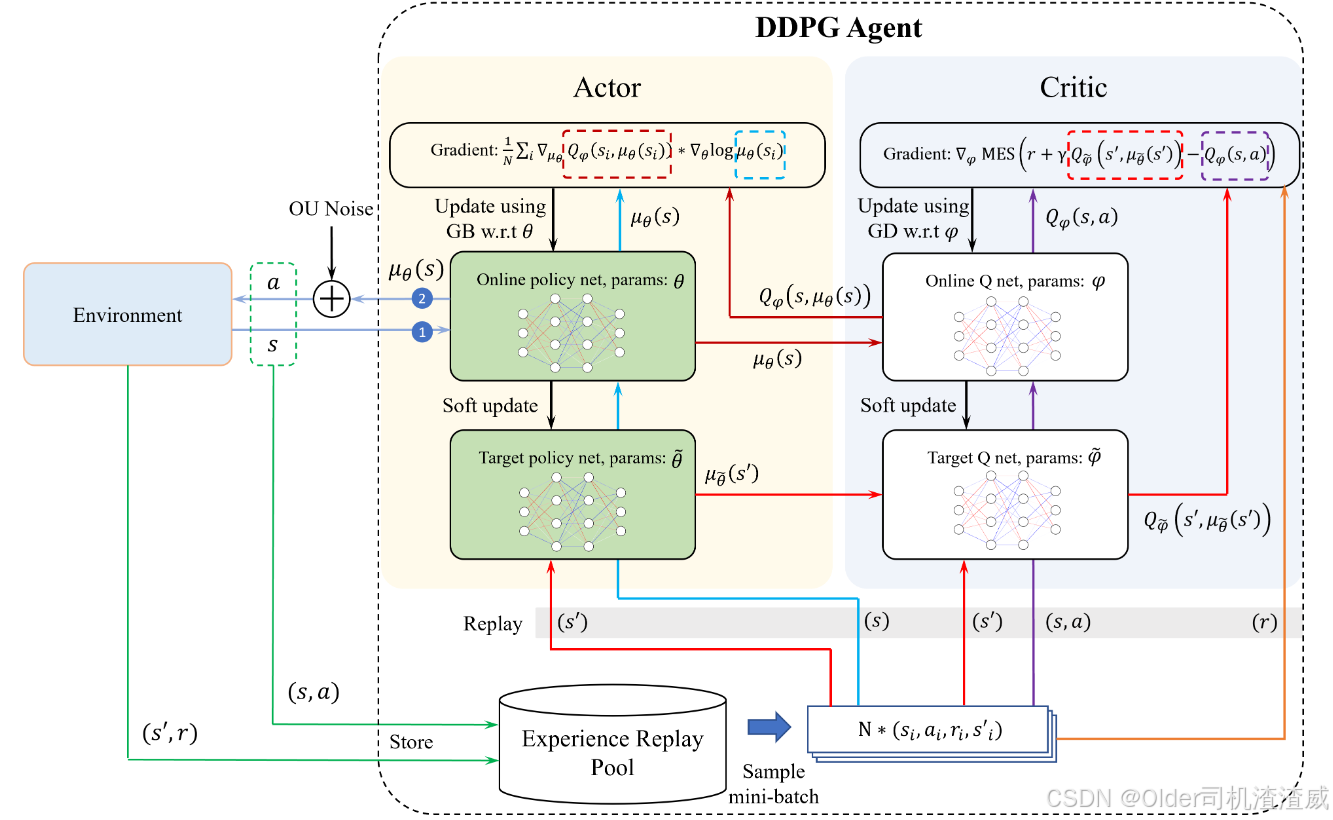
二、DDPG算法结构图
DDPG算法的结构图如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6794
6794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











