









RL for 推荐
经典的推荐系统方案包括:collaborative filtering(content-based/user-based),DeepFM,Wide&Deep等方法。这些方法往往只考虑one-shot回报,而忽略了当前推荐对用户未来行为的影响。
而基于强化学习的方案将推荐系统和用户的交互建模成一个序列决策问题,既支持线上学习,又能更好地考虑长期的推荐收益。
谷歌研究人员将强化学习中经典的REINFORCE算法应用于youtube的视频推荐中,他们将用户长期平均的观看视频时间ViewTime作为评价指标(不是将单次视频时间ViewTime作为评价指标)[20]。此外,推荐系统往往利用日志文件进行学习,日志文件纪录的可能是其它版本的用户行为,这个过程对应强化学习中off-policy的设定。针对这一训练设定,[20]提出改进版的REINFORCE算法。具体而言,论文提出一种估算behavior policy的方法,利用importance sampling的思想对于sample weight进行修正。由于action是一组候选物品,算法同时需要做Top-K Correction。模型假设候选物品组内是相互独立的,得到REINFORCE新的更新式。此模型被部署在在实际线上环境进行了为期数天的A/B测试,并同时将实验期间用户上传的新视频也作为线上训练的资料。实验发现ViewTime提升了0.88%,证明了基于强化学习的推荐系统方案的可实现性和优越性。
论文[21]采用Actor/Critic框架进行训练,这一框架适用于state space和action space都极大的场景。Actor由encoder-decoder结构组成,encoder负责计算用户兴趣的动态变化,decoder负责生成候选的商品。Critic返回(state,action)对应的Q-value。本文的创新点之一是考虑到了推荐时商品之间的2D位置关系,Actor输出的action中同时包括了每个商品的2D位置信息。
可解释性的推荐系统指的是系统在生成推荐列表的同时,针对每一个推荐商品,生成推荐的理由。通过分析模型生成推荐列表的逻辑链,开发人员能更好地理解系统的性能,并针对特定的需求和场景进行优化。用户也可以通过具体的推荐理由,给出更细化的反馈内容,从而进一步提升推荐系统的整体性能。
论文[22]提出了一种基于图谱的推荐解释性方法。具体而言,可解释性的实现是通过先建立用户和商品之间的知识图谱,再将推荐行为建模成路径搜索问题,路径经过的节点即是推荐逻辑链的组成部分。路径搜索问题由强化学习算法进行学习。如下图示例,推荐的逻辑链可表示为:
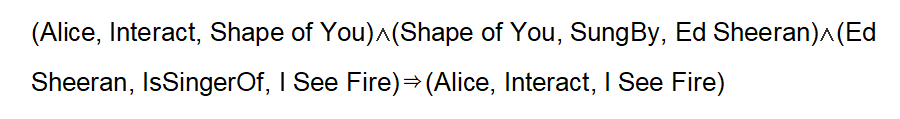

结论与展望
随着AlphaGo的出现,强化学习引起了广泛的关注。与监督学习相比,强化学习的主要特点体现在:(a)强化学习以整体回报为目标来优化整个序列决策过程;(b)强化学习通过和环境交互而优化策略,无需标记样本。
除了在游戏领域崭露头角,最近几年强化学习也逐渐被应用于其他领域,本文主要介绍了强化学习在NLP和推荐系统中的应用。总的来说,强化学习能在部分场景中取得比较好的性能;但在实际应用中也存在一些问题,如学习效率低、训练难度大、泛化能力不稳定等[23]。如何在强化学习的实际使用过程中处理好这些问题,这是我们在后续工作中需要重点思考的。
推荐系统可以根据用户的偏好推荐产品、服务、信息、新闻、电影、音乐等。个性化推荐可以帮助减缓信息爆炸带来的困扰。
在以用户为中心的推荐系统中,关键是:
1、能以自然、透明的方式与用户交互,了解用户真实的需求和偏好。
2、通过与用户的自然交互,推荐系统估计、提取同时也向用户反馈:影响用户的满意度、偏好、需求、兴趣、活动模式等隐含的状态
从而从用户的偏好、用户决策推理的行为过程出发,替用户做最好的决定。强化学习在这些任务中都有重要作用。
面向用户的强化学习有如下挑战:
1)大规模的用户数量和动作数量、多用户马尔科夫决策过程(Markov Decision Process, MDP)、像候选名单这样的组合动作空间;
2)有特性的动作空间,比如随机的动作集、动态候选名单大小等;
3)用户在偏好、活动、个性、学习、外部因素、行为效果等方面的隐含状态导致高度的不可观察性和随机性,从而降低信噪比、加长时间范围(horizon)等;
4)生态系统效果,比如动机、生态系统的动态性、公平性等。
如何处理强化学习中的大规模离散动作空间问题
强化学习系列三——如何处理大规模离散动作空间 - 知乎 (zhihu.com)
InteractiveRecommendation
Session_based Recommendation -------- dragonflyshi_item
Session_based
强化学习在推荐系统中的
推荐系统简单介绍:
基于内容的->基于协同过滤的->结合深度学习->结合强化学习(深度强化学习DRL in RS)
主要论文引述讲解:针对强化学习中的大规模离散空间问题的解决方法–TPGR
关键知识点(常出现):
马尔可夫决策过程
DQN算法
元数据:描述数据的数据,一个事物的属性信息,比如一个节目的名称、标签

















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











