







Trie树
Trie树又叫做前缀树、字典树。核心思想是以空间换时间,利用字符串的共同前缀(Common Prefix)作为存储依据。
Trie的字符串搜索时间复杂度为O(m),m为最长的字符串的长度,其查询性能与集合中的字符串的数量无关。
性质
- 根结点(Root)不包含字符,除根结点以外,每个节点都仅包含一个字符。
- 从根结点到某一节点路径上所经过的字符节点连接起来,即为该节点所对应的字符串。
- 任意节点的所有子节点所包含的字符都不相同。
下图的 Trie 树中包含了字符串集合 [“Joe”, “John”, “Johnny”, “Jane”, “Jack”]。
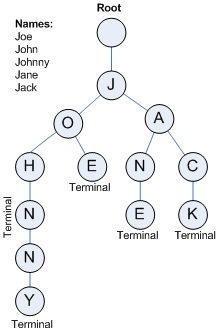
Trim查找过程
- 每次从根结点开始搜索;
- 获取关键词的第一个字符,根据该字符选择对应的子节点,转到该子节点继续检索;
- 在相应的子节点上,获取关键词的第二个字符,进一步选择对应的子节点进行检索;
- 以此类推,进行迭代;
- 若在某个节点处,关键词的所有字母已被取出,则读取附在该节点上的信息,查找完成。
代码
class Trie {
private Trie[] children;
private boolean isEnd;
// Trie树,每个节点包含以下字段:
// 1. 指向子节点的指针数组children。(长度为26,代表26个小写字母)
// node.children[0]==null -> 子节点无字母a
// node.children[0]==new Trie() -> 子节点有字母a
// 2. boolean字段isEnd,表示该节点是否为字符串的结尾.
public Trie() {
children = new Trie[26];
isEnd = false;
}
// 从字典树的根开始,插入字符串
// 1.若子节点存在。沿着指针移动到子节点,继续处理下一个字符。
// 2.若子节点不存在。创建一个新的子节点,记录在node.children数组的对应位置
// 上,然后沿着指针移动到子节点,继续搜索下一个字符。
// 重复上述步骤,直到处理字符串的最后一个字符,然后把当前节点标记为字符串的结尾。
public void insert(String word) {
Trie node = this;
// 插入该单词的字符
for(int i=0; i<word.length(); i++){
char ch = word.charAt(i);
int index = ch-'a'; // 0-a,1-b,...,25-z
if(node.children[index]==null)
node.children[index] = new Trie();
node = node.children[index];
}
node.isEnd = true;
}
// 查找前缀
// 从字典树的根开始查找前缀。对于当前字符对应的子节点,有两种情况:
// 1.子节点存在。沿着指针移动到子节点,继续搜索下一个字符;
// 2.子节点不存在。说明字典树中不包含该前缀,返回空指针.
// 重复上述步骤,直到返回空指针或者搜索完前缀的最后一个字符。
//
// 若搜索到了前缀的末尾,就说明字典树中存在该前缀。
//
// 此外,若前缀末尾对应节点的isEnd为真,说明字典树中存在该字符串。
private Trie searchPrefix(String prefix){
Trie node = this;
for(int i=0; i<prefix.length(); i++){
char ch = prefix.charAt(i);
int index = ch-'a';
if(node.children[index]==null)
return null;
node = node.children[index];
}
return node;
}
public boolean search(String word) {
Trie node = searchPrefix(word);
return node!=null && node.isEnd;
}
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
}














 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









