







7月23日,Meta正式发布迄今为止最强大的开源模型——Llama 3.1 405B,同时发布了全新升级的Llama 3.1 70B和8B模型。

Meta在正式发布里也附上了长达92页的论文《The Llama 3 Herd of Models》,揭示了Llama 3模型的技术和训练细节。

论文地址:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/。

模型信息
模型版本:共有8B、70B、405B三种版本。其中405B版本拥有4050亿参数,是目前最大的开源模型之一。
上下文长度:扩展到128K上下文长度,能够处理更复杂的任务和对话。
支持语言:支持8种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
模型架构:优化了的Transformer模型架构,微调后的版本使用SFT和RLHF来对齐可用性与安全偏好。
训练数据:使用来自公开来源的超过15万亿个token数据进行了预训练,预训练数据的截止日期为2023年12月;微调数据包括公开可用的指令数据集,以及超过2500万个综合生成的示例。
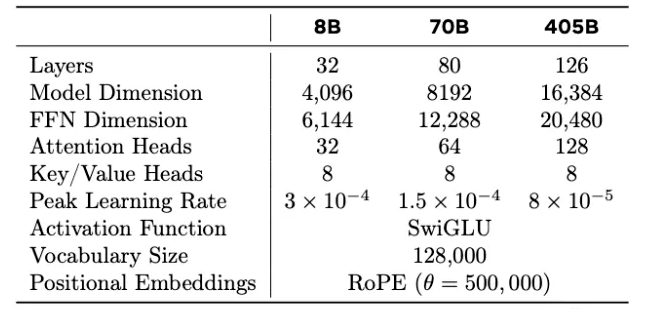
模型的关键参数:

模型评估
根据Meta提供的基准测试数据,最受关注的4050亿参数的Llama 3.1 405B版本,从性能上已经可媲美GPT-4o和Claude 3.5。
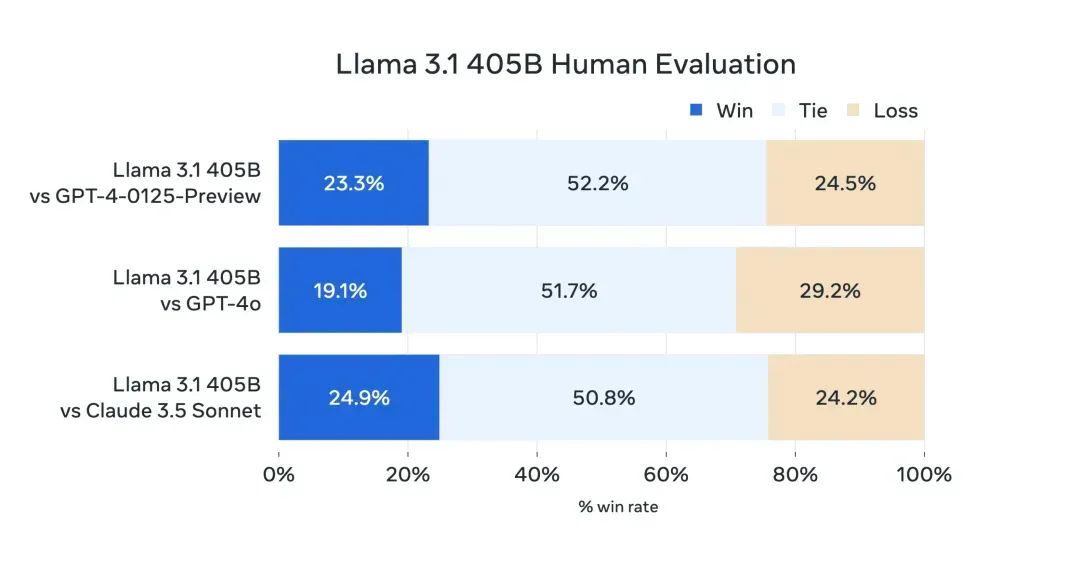
注:Human Evaluation主要用于评估模型在理解和生成代码、解决抽象逻辑问题方面的能力。
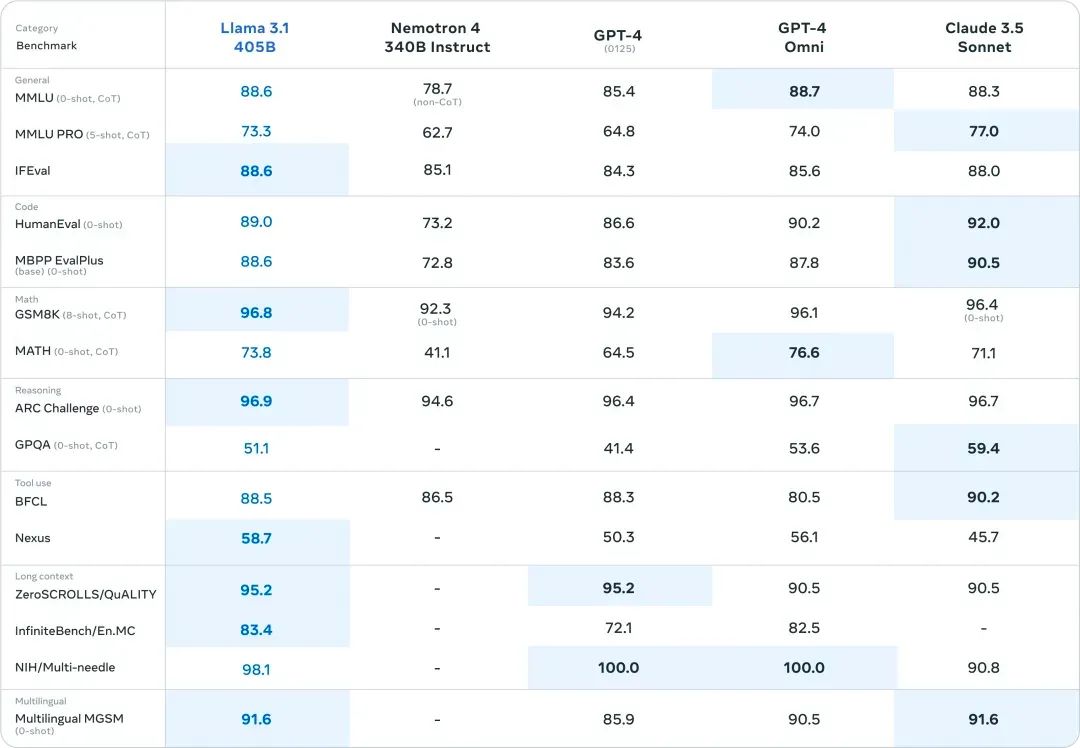
Llama 3.1与GPT4等闭源模型比较:
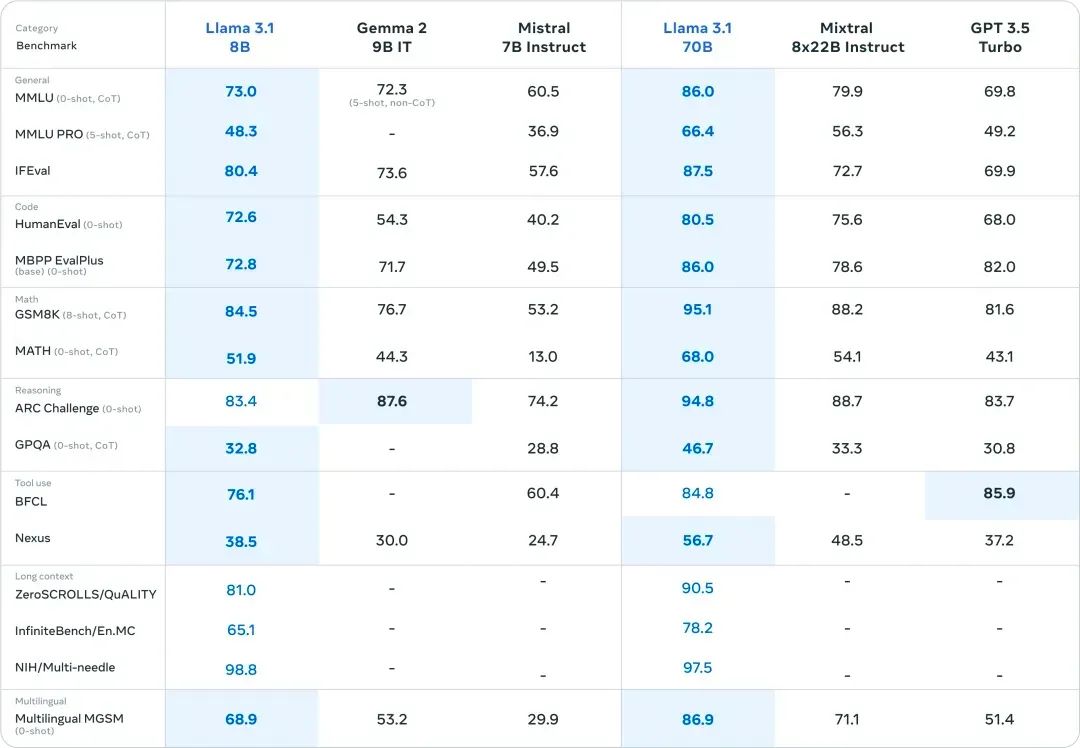
Llama 3.1与Mistral 7B Instruct等开源模型比较:
Llama 3.1的发布,让顶尖的开源模型能真正与顶尖的闭源模型PK了!
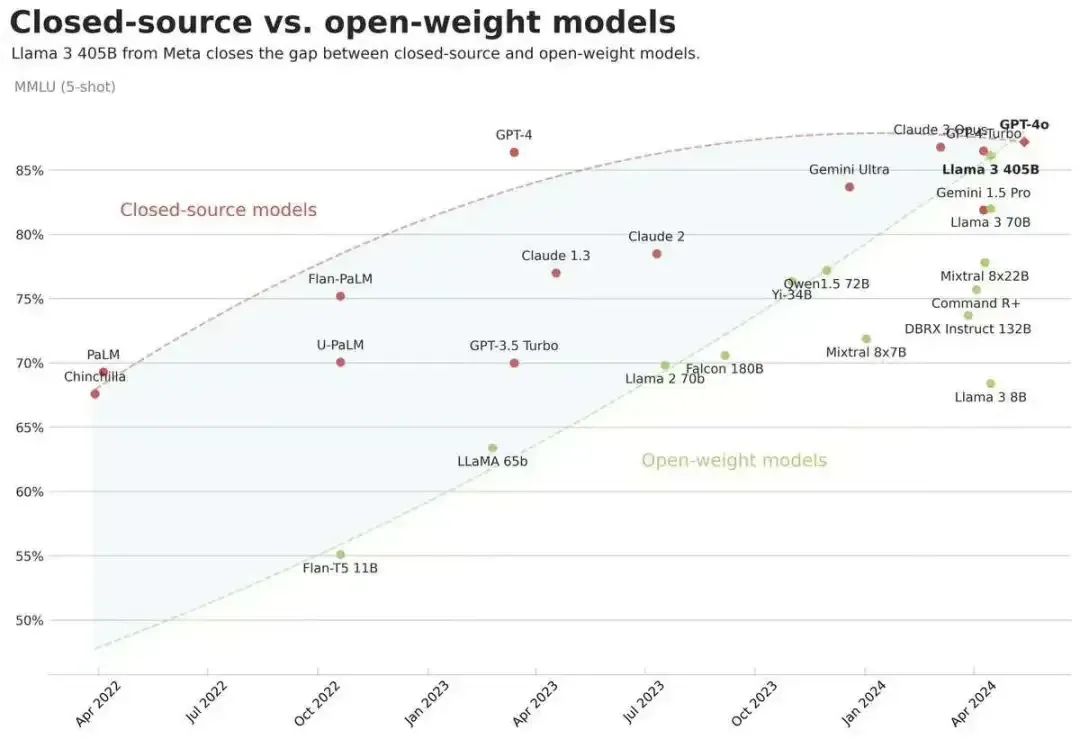
Meta表示“到目前为止,开源大型语言模型在功能和性能方面大多落后于封闭式模型。现在,我们正迎来一个由开源引领的新时代。”

训练细节
-
Llama 3.1的训练使用了16000块NVIDIA H100。
-
为了保证训练稳定性,只用了Transformer模型架构进行调整,而不是现在流行的混合专家模型(MoE)架构。
达到如此训练规模的开源大模型,目前全世界仅此一家。
对于开发者们关心的:大公司们在付出了巨大训练成本后,还会继续开源吗?
在Llama 3.1发布的当下,扎克伯格再次强调:把开源进行到底!
在 AI 发展的浪潮中,我们深知强大算力对于推动 AI 创新的关键作用。英智未来专注于提供高效、稳定、灵活的算力租赁服务,助力您的 AI 项目飞速发展。
无论您是科研机构、创新企业还是个人开发者,英智未来的算力租赁都能为您量身定制解决方案,让您无需为高昂的硬件投入和复杂的运维烦恼,轻松拥抱 AI 新时代!

















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











