







Pandas AI 助力数据处理:10 个常见任务的全新解法。
微信搜索关注《AI科技论谈》

在数据科学领域,Pandas 一直是数据科学家和分析师的得力工具,它开源且能提供便捷高效的数据操作与分析功能,可以轻松应对各种复杂的数据处理任务,堪称数据处理界的 “瑞士军刀”。
如今,一款名为 Pandas AI 的全新 Python 库诞生,为数据处理带来新的思路与方式。 Pandas AI 巧妙地将生成式人工智能融入 Pandas,把传统的数据框操作升级为对话式交互。借助大语言模型,用户能和数据 “对话” 并获得结构化回复,即使不懂编程也能处理数据。
Pandas AI 不是要替代 Pandas,而是增强其功能,帮数据从业者探索新方法、简化数据准备,节省时间精力。
本文介绍 Pandas 的 10 个常见数据处理任务,看看 Pandas AI 如何把编码操作变为对话交互。
准备工作
在开始Pandas任务之前,让我们先编写必要的代码来运行整个Python程序。
-
安装包:复制并运行
!pip install pandas pandasai -
导入模块:由于PandasAI内部调用Pandas进行数据处理,调用OpenAI进行人工智能生成,所以必须导入
pandas和pandasai.llm.openai。
import pandas as pd
from pandasai import PandasAI
from pandasai.llm.openai import OpenAI
-
加载OpenAI大语言模型
OPENAI_API_KEY = "{你的API密钥}"
llm = OpenAI(api_token=OPENAI_API_KEY)
-
创建数据框:在以下演示中,创建了一个包含虚构员工信息的数据框
df,信息包括姓名、年龄、性别、职业和薪资。
data = [
[1, "约翰·多伊", 30, "男", "软件工程师", 100000],
[2, "简·史密斯", 28, "女", "数据科学家", 95000],
[3, "迈克·约翰逊", 35, "男", "产品经理", 120000],
[4, "艾米丽·戴维斯", 32, "女", "软件工程师", 105000],
[5, "亚历克斯·威尔逊", 29, "男", "数据科学家", 90000],
[6, "莎拉·汤普森", 33, "女", "产品经理", 115000],
[7, "大卫·李", 31, "男", "软件工程师", 102000],
[8, "艾玛·布朗", 27, "女", "数据科学家", 92000],
[9, "杰森·安德森", 34, "男", "产品经理", 118000],
[10, "索菲·安德森", 30, "女", "数据科学家", 97000],
[11, "艾米丽·米勒", 29, "女", "业务分析师", 85000],
[12, "艾拉·泰勒", 31, "女", "用户体验设计师", 95000],
[13, "珍妮·威尔逊", 27, "女", "市场经理", 110000],
[14, "亚当·亚当斯", 33, "男", "项目经理", 105000],
[15, "雅各布·戴维斯", 30, "男", "业务分析师", 88000],
[16, "艾娃·托马斯", 28, "女", "用户体验设计师", 98000],
[17, "本杰明·怀特", 34, "男", "市场经理", 115000],
[18, "米娅·安德森", 32, "女", "项目经理", ],
[19, "洛根·泰勒", 29, "男", "业务分析师", 90000],
[20, "杰克·威尔逊", 31, "男", "用户体验设计师", 102000],
[12, "艾拉·泰勒", 31, "女", "用户体验设计师", 95000]
]
# 根据数据创建DataFrame
df = pd.DataFrame(data, columns=["id", "name", "age", "gender", "occupation", "salary"])
-
创建PandasAI对象
pandas_ai = PandasAI(llm)
下面使用Pandas AI进行编码吧。
1 数据选择
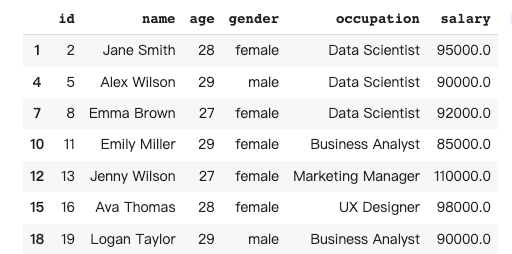
Pandas中的数据选择是指根据特定条件或标准,从数据框中选择特定的行和列。在这个例子中,我们想要一个只包含30岁以下人员的数据框。
# 提示
df1 = pandas_ai.run(df, prompt='''
give me a dataframe that contains the people under age 30
''', is_conversational_answer=False)
Pandas AI的回复:
2 数据排序
Pandas中的数据排序是指根据一个或多个列中的值,按升序或降序排列数据框中的数据。在这个例子中,要一个按薪资升序排列的数据框。
# 提示
df2 = pandas_ai.run(df, prompt='''
give me a dataframe that sort the salary in ascending order
''', is_conversational_answer=False)
Pandas AI的回复:
3 数据聚合
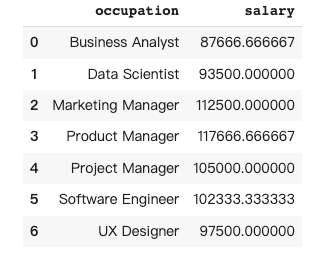
Pandas中的数据聚合是指对数据框中的数据进行分组和汇总的过程,以便深入了解数据并得出有意义的结论。在这个例子中,要一个按职业提供平均薪资的数据框。
# 提示
df3 = pandas_ai.run(df, prompt='''
give me a dataframe that group the occupation and provide average salary
''', is_conversational_answer=False)
Pandas AI的回复:
4 数据重塑
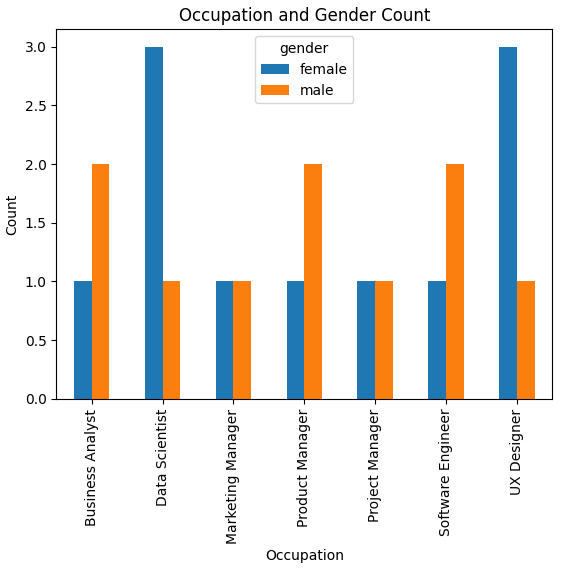
Pandas中的数据重塑是指改变数据框的布局,使其更适合分析需求,例如通过透视、堆叠或融合数据来创建新的结构。在这个例子中,我们想要一个条形图,它反映一个透视表,以查看每个职业中的性别差异。
# 提示
df4 = pandas_ai.run(df, prompt='''
bar chart a pivot table that show the people count under occupation and gender
''', is_conversational_answer=False)
Pandas AI的回复:
5 数据清洗
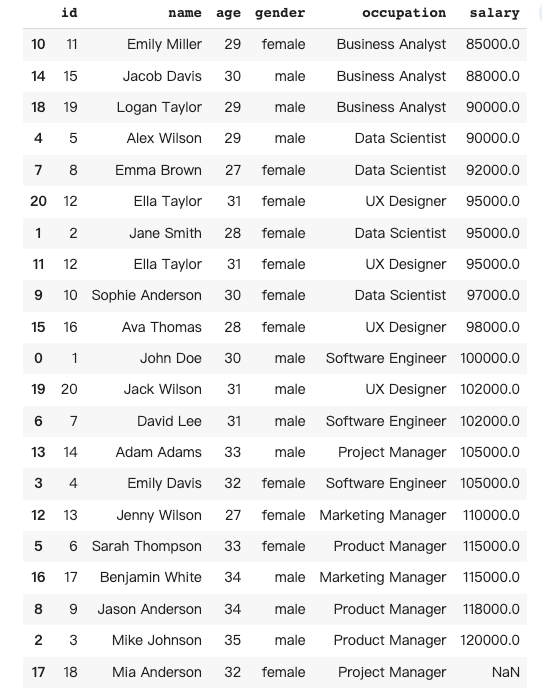
Pandas中的数据清洗是指通过检测和处理缺失、重复或错误的数据,对数据框进行预处理,使其适合分析。在这个例子中,希望Pandas AI自动填充“米娅·安德森”缺失的薪资数据,并删除“艾拉·泰勒”的重复行。
# 提示
df5 = pandas_ai.run(df, prompt='''give me a dataframe that
1) fill in the missing data
2) delete the duplicated rows
''', is_conversational_answer=False)
Pandas AI的回复:
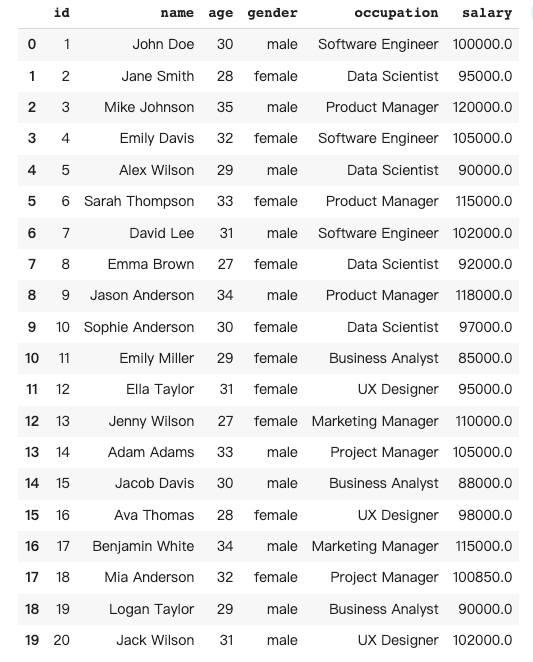
6 数据合并
Pandas中的数据合并是指根据一个或多个共同列,将两个或多个数据框合并为一个数据框。在这个例子中,将另外5个人的信息添加到原始数据框中。
# 另一个数据集
data2 = [
[1, "索菲娅·布朗", "女", 28, "数据科学家", 93000],
[2, "简·史密斯", 28, "女", "数据科学家", 95000],
[3, "米歇尔·陈", 30, "女", "软件工程师", 100500],
[4, "迈克尔·约翰逊", 35, "男", "产品经理", 120000],
[5, "奥利维亚·威尔逊", 29, "女", "数据科学家", 90000]
]
df2 = pd.DataFrame(data2, columns=["id", "name", "age", "gender", "occupation", "salary"])
# 提示
pandas_ai.run([df,df2], prompt='''
give me a dataframe that combine all the rows
''', is_conversational_answer=False)
Pandas AI的回复:
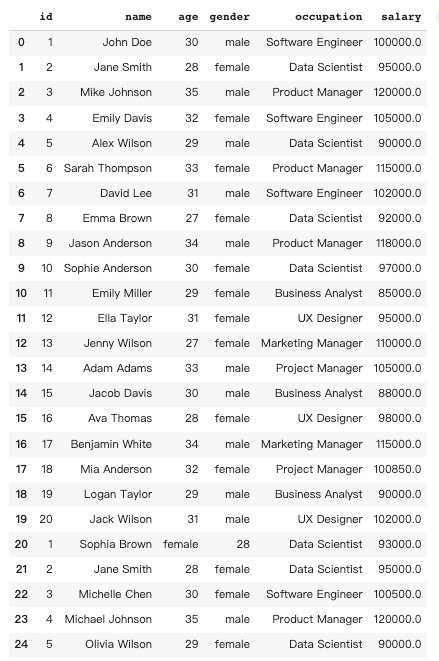
7 数据转换
Pandas中的数据转换是指对数据框的结构或内容进行操作和更改,使其更适合分析,或从数据中获取有价值的信息。在这个例子中,想将所有数据科学家的薪资翻倍。
# 提示
df7 = pandas_ai.run(df, prompt='''
give me a dataframe that double the salary to all the data scientists
''', is_conversational_answer=False)
Pandas AI的回复:
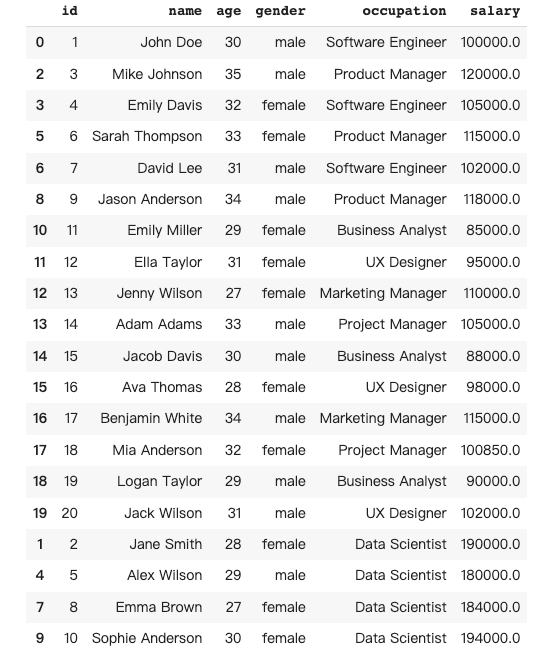
8 数据描述
Pandas 中的 describe() 方法可通过计算各种统计量(如计数、均值、标准差、最小值和最大值),对数据框分布的集中趋势、离散程度和形态进行总结。
提示代码:
df8 = pandas_ai.run(df, prompt='''
Pandas describe the dataframe
''', is_conversational_answer=False)
Pandas AI 的回复:
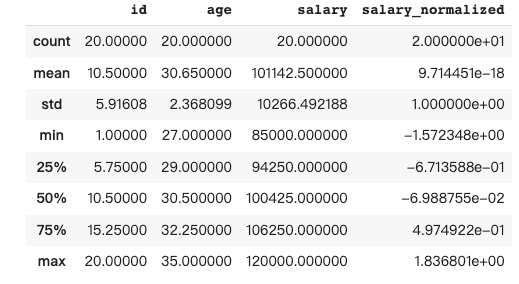
9 数据归一化
Pandas 中的数据归一化是将数值数据缩放到一个共同范围(如 0 到 1 之间)的过程,这样可以消除偏差,使数据更具可比性,便于分析。
在这种情况下,想通过减去均值并除以标准差的方式对薪资数据进行归一化处理。
提示代码:
pandas_ai.run(df, prompt='''
give me a dataframe that normalizing every salary by subtracting mean
and dividing by standard deviation
''', is_conversational_answer=False)
Pandas AI 的回复:
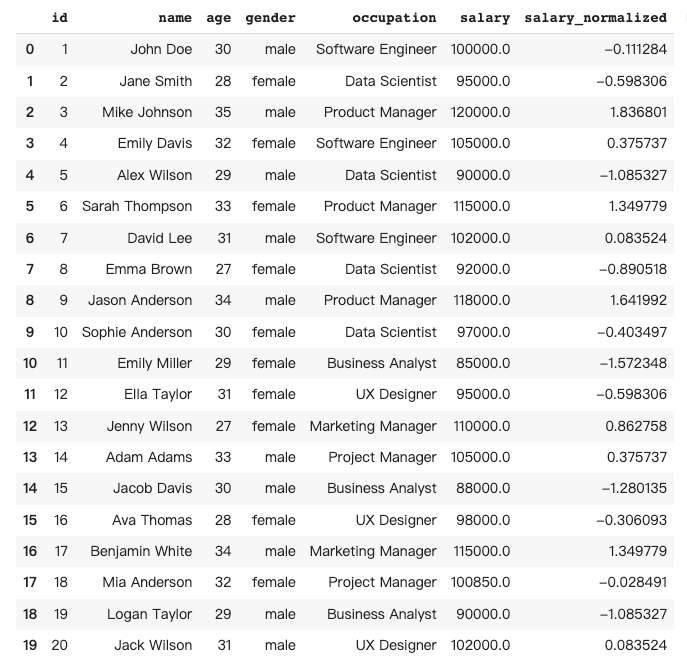
10 时间序列分析
Pandas 中的时间序列分析涉及对按时间索引的数据(如每日股票价格或每小时天气数据)进行分析,以识别模式和趋势,并根据历史数据进行预测。
在这种情况下,创建了另一个虚拟数据集,列出了 100 天的随机数据。Pandas AI 的任务是使用均值函数将数据从按天采样重采样为按周采样。
原始数据集:
import numpy as np
df_t = pd.DataFrame({'Date': pd.date_range('2023-03-07', periods=100), 'Open': np.random.randn(100)})
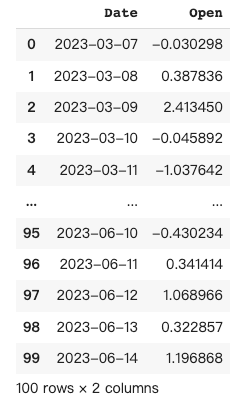
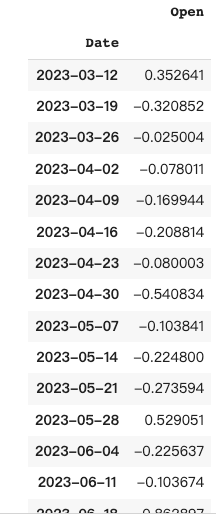
提示代码:
pandas_ai.run(df_t, prompt='''
Resample the DataFrame to a weekly frequency and take the mean
''', is_conversational_answer=False)
Pandas AI 的回复:
《LangChain大模型AI应用开发实践》
本书是一本深度探索LangChain框架及其在构建高效AI应用中所扮演角色的权威教程。本书以实战为导向,系统介绍了从LangChain基础到高级应用的全过程,旨在帮助开发者迅速掌握这一强大的工具,解锁人工智能开发的新维度。
本书内容围绕LangChain快速入门、Chain结构构建、大模型接入与优化、提示词工程、高级输出解析技术、数据检索增强(RAG)、知识库处理、智能体(agent)开发及其能力拓展等多个层面展开。通过详实的案例分析与步骤解说,读者可以学会整合如ChatGLM等顶尖大模型,运用ChromaDB进行高效的向量检索,以及设计与实现具有记忆功能和上下文感知能力的AI智能体。此外,书中还介绍了如何利用LangChain提升应用响应速度、修复模型输出错误、自定义输出解析器等实用技巧,为开发者提供了丰富的策略与工具。
本书主要面向AI开发者、数据科学家、机器学习工程师,以及对自然语言处理和人工智能应用感兴趣的中级和高级技术人员。
【5折促销中】购买链接:https://item.jd.com/14848506.html

精彩回顾
QwQ-32B本地部署教程来了,全新开源推理大模型,性能比肩DeepSeek满血版
解读Deep Research:传统RAG已死,带你实现Agentic RAG
大模型应用开发平台Dify推出1.0版本,基于向量数据库Milvus实现RAG

















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









