







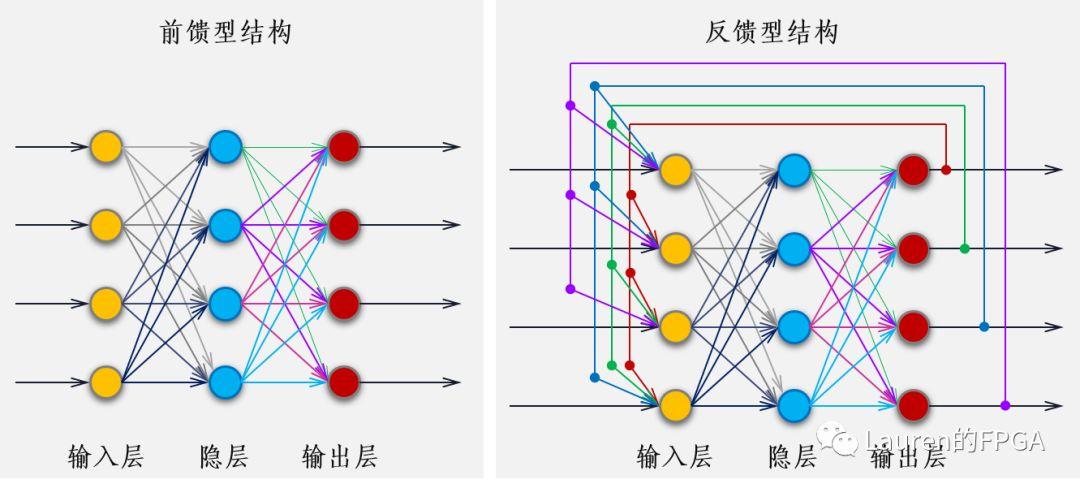
运用AR模型进行预测与人工神经网络进行预测的区别在哪里?
。
AR模型是一种线性预测,即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点),所以其本质类似于插值,其目的都是为了增加有效数据,只是AR模型是由N点递推,而插值是由两点(或少数几点)去推导多点,所以AR模型要比插值方法效果更好。
而用人工神经网络进行预测,构建的网络模型是一种非线性函数,推算出预测值。在速度上比AR慢,但是每个数据可以有几个数据点组成,而AR只能是每个数据有一个数据点。
谷歌人工智能写作项目:小发猫

数据挖掘中分类、预测、聚类的定义和区别。
你好,简单地说,分类(categorizationorclassification)就是按照某种标准给对象贴标签(label),再根据标签来区分归类rfid。
简单地说,聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程。区别是,分类是事先定义好类别,类别数不变。分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴。
聚类则没有事先预定的类别,类别数不确定。聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成。
分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书;聚类则适合不存在分类体系、类别数不确定的场合,一般作为某些应用的前端,比如多文档文摘、搜索引擎结果后聚类(元搜索)等。
分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个类中。要构造分类器,需要有一个训练样本数据集作为输入。
训练集由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,训练样本还有一个类别标记。
一个具体样本的形式可表示为:(v1,v2,...,vn;c)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









