






无论你是AI爱好者、开发者,还是渴望在人工智能领域有所突破的创业者,了解 Hugging Face 上的强大模型,绝对是你迈向成功的必备技能之一。
在AI圈,如果你还不知道 Hugging Face,那就像刷短视频不知道抖音的存在一样——Hugging Face连接最新技术与实际应用的桥梁,作为AI开源社区的领导者,Hugging Face 汇集了当前最先进的开源模型,是全球研究者、开发者和企业加速AI开发的关键平台。
即使是非技术人员,也能通过了解 Hugging Face 的简洁模型分类,掌握最前沿的开源AI工具,帮助你在问题出现时,知道哪类模型能提供帮助。
下图来自于huggingface网站的截图,分类已经帮大家整理了到文章中:
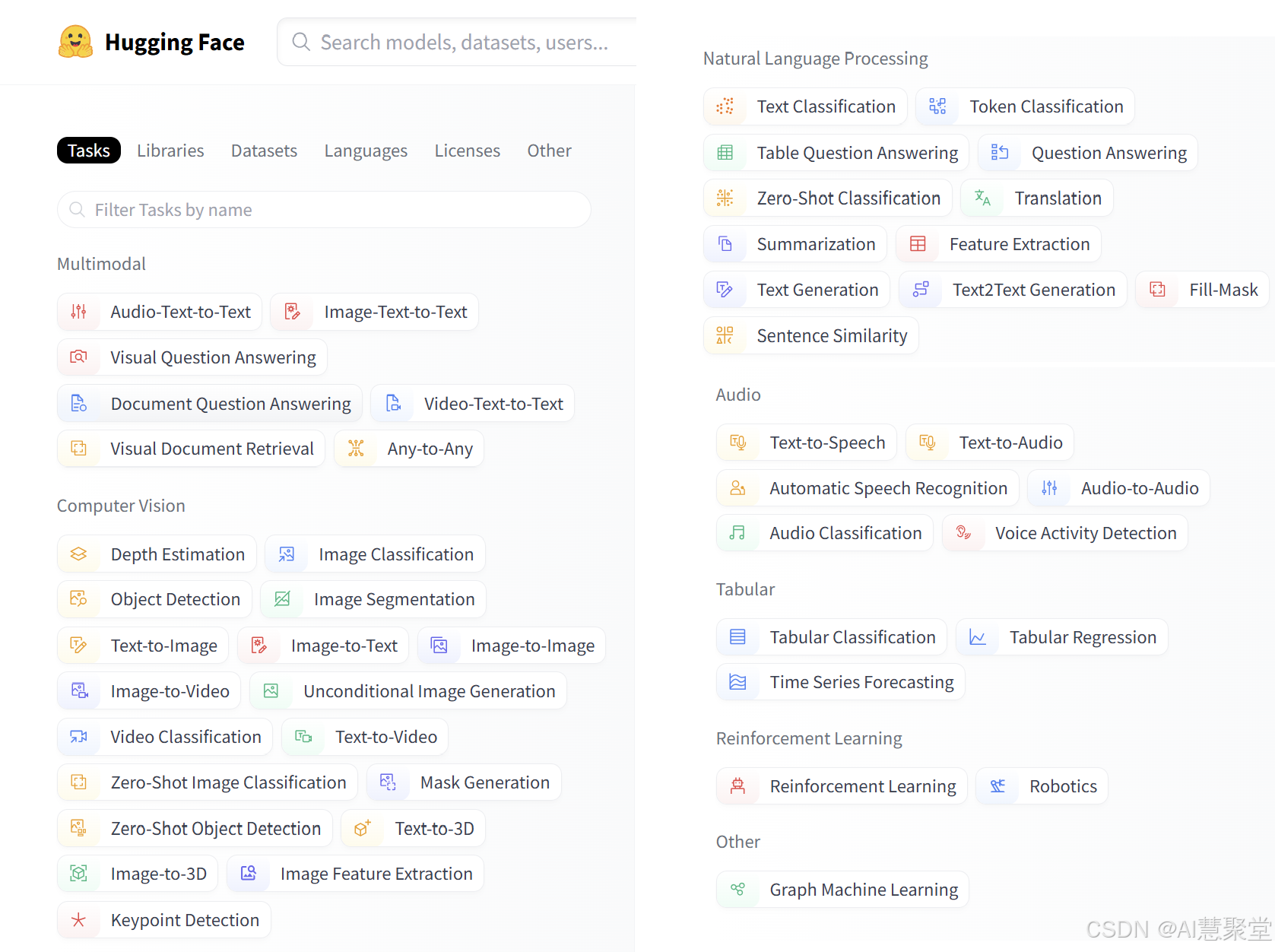
Hugging Face 上的模型分为几个大的分类:
- Multimodal(多模态)、
- Computer Vision(计算机视觉)、
- Natural Language Processing(自然语言处理)、
- Audio(音频处理)、
- Tabular(表格数据处理)
- 其他(Other)。
下面将重点讲解 Multimodal(多模态)模型,探索它们如何结合不同类型的数据,创造出跨领域的智能应用。”
“多模态”是指模型能够同时处理多种类型的数据,比如文本、图像、音频、视频等。简单来说,就是让机器像人类一样理解和融合来自不同感官的信息,极大地拓展了AI应用的边界。属于多模态分类有下面这些种类的模型:
📢1. Audio-Text-to-Text(音频到文本)
-
介绍:音频到文本模型的核心功能是语音识别(Automatic Speech Recognition, ASR),将音频信号转化为文字。它不仅能“复述”语音内容,还能结合上下文进行语义理解(如口音、背景噪音过滤)。
-
代表性模型:
OpenAI/Whisper:支持多语言的高精度语音识别模型,社区应用广泛。
facebook/wav2vec2:基于自监督学习的语音识别模型,适用于低资源语言场景。
Qwen/Qwen2-Audio-7B-Instruct,国产的千问大模型,排在流行的第一位。
-
常见应用:语音助手、会议记录转录、无障碍技术(如实时字幕生成)。
🎨2. Image-Text-to-Text(图像到文本)
-
介绍:图像到文本模型通过视觉编码器(如SigLIP)和文本解码器的结合,生成与图像内容相关的描述或分析。其能力包括物体识别、场景理解,甚至情感推断(如“图片中的夕阳显得宁静”)。
-
代表性模型:
Hugging Face/SmolVLM-256M:轻量级多模态模型,支持移动端部署,仅需1GB显存即可推理。
Salesforce/BLIP-2:结合视觉与语言预训练,生成高质量图文描述。
👀3. Visual Question Answering(视觉问答)
-
介绍:该模型需同时理解图像内容和自然语言问题,输出基于视觉推理的答案。例如,输入一张餐桌图片并提问“桌上有多少餐具?”,模型需识别物体并计数。
-
代表性模型:
dandelin/vilt-b32-finetuned-vqa:基于ViLT架构,支持复杂视觉推理任务。
internlm/internlm-xcomposer2:国产,浦语·灵笔,支持多轮对话式视觉问答,适合动态交互场景,下载量遥遥领先。
🔎4. Document Question Answering(文档问答)
-
介绍:文档问答模型结合OCR(光学字符识别)与自然语言处理技术,从结构化或非结构化文档(如PDF、扫描件)中提取答案。例如,从合同文件中快速定位条款内容。
-
代表性模型:
impira/layoutlmv3:支持表格、图表混合文档的问答,精度较高。
naver-clova-ix/donut:基于Transformer的端到端文档理解模型,无需OCR预处理。
📺5. Video-Text-to-Text(视频到文本)
-
介绍:视频到文本模型需解析时序动态信息,生成视频摘要、动作描述或事件推理(如“两人握手后开始谈判”)。部分模型支持帧级关键内容提取。
-
代表性模型:
Hugging Face/SmolVLM-500M:专为企业场景设计,支持短视频字幕生成,推理显存需求仅1.23GB。
microsoft/viper-7b:结合时空注意力机制,适用于长视频分析。
📚6. Visual Document Retrieval(视觉文档检索)
-
介绍:该任务通过图像特征匹配,从海量文档库中检索相关内容。例如,输入产品设计草图,检索出相似的专利文档。
-
代表性模型:
facebook/dpr:基于稠密段落检索(DPR),支持图文跨模态检索。
clip-ViT-B-32:结合CLIP的视觉-文本对齐能力,实现零样本检索。
🧘🏻♀️7. Any-to-Any(多模态全能模型)
-
介绍:支持任意模态输入与输出的通用模型,例如音频生成图像、视频生成文本等。这类模型依赖统一的嵌入空间和跨模态对齐技术。
-
代表性模型:
Hugging Face/IDEFICS:支持图像、文本、视频的混合输入与生成,开源社区评价较高。
deepseek-ai/Janus-Pro-7B:优秀的国产模型,出自DeepSeek。
DeepMind/Flamingo:基于少样本学习的多模态模型,擅长复杂推理任务。
通过了解这些多模态模型,我们可以应对更多复杂的任务,打造出智能、跨界的AI应用。对于初学者来说,了解这些模型的基本功能,并熟悉一些代表性工具,是你在人工智能领域成长的必经之路。
在下一篇文章中,我们将深入探讨 Computer Vision(计算机视觉) 模型,敬请期待!


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









