







学习自周志华老师《机器学习》的前两章,一个简短的学习笔记。
基本概念
分类问题:预测离散值
回归问题:预测连续值
泛化能力:学习得到的模型适用于新样本的能力
模型评估与选择
对数据集处理得到训练集和测试集的方法
① 留出法
将数据集D直接划分为两个互斥的集合,一个作为训练集S,一个作为测试集T(一般设置大约2/3~4/5的用于训练)。
单次使用留出法的结果可能不可靠,一般要采用若干次随机划分并重复进行实验评估后取平均值作为留出法的结果。
② 交叉验证法
K折交叉验证:将数据集D划分为k个大小相似的互斥子集,每次用k-1个子集作为训练集,余下的1个子集作为测试集,从而获得k组训练集/测试集,可进行k次训练和测试,最终返回k次训练和测试结果的均值。
同留出法,为减小因样本划分不同带来的差异,k折交叉验证还需随机使用不同的划分重复p次,最终返回p次k折交叉验证结果的均值。
③ 自助法
每次从包含m个样本的数据集D中随机挑选一个样本置于D’中,重复m次,得到训练集D’,将D-D’作为测试集。
在m次采样中,始终没有被采到D’的概率约为1/3。故实际模型与期望评估模型都使用m个样本,但仍有1/3的样本没出现在训练集以用于测试。
性能度量
错误率,精度,查准率,查全率,代价敏感错误率
以下查准率,查全率,真正例率和假正例率均以二分类问题为例。
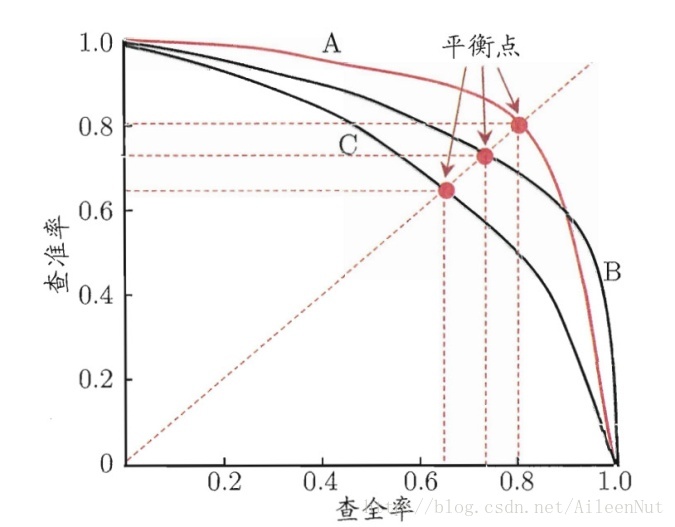
① P-R曲线:以查全率为横轴,查准率为纵轴
查准率:预测出的真正例/所有预测出的正例
查全率:预测出的真正例/所有的正例
如果一个学习器的曲线能包围另一个,则表明性能高于另一个。如图中,A>C。
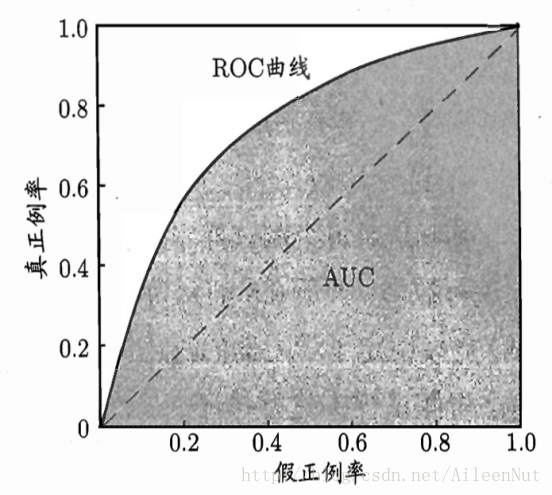
② ROC曲线:以假正例率为横轴,真正例率为纵轴
真正例率:预测出的真正例/所有的正例
假正例率:预测出的假正例/所有的反例
如果一个曲线能包围另一个,则表明性能优于另一个。如果二者有交叉,则可判断AUC(曲线下的面积大小)。
比较检验
① 已知测试错误率e,推算泛化错误率e0,验证对泛化错误率的假设是否成立。
主要用到t检验,交叉t检验,McNemar检验,Friedman检验和Nemenyi后续检验等方法。(此处涉及很多概率论的知识,有点遗忘,没有仔细看)
② 对泛化误差进行偏差-方差分解:泛化误差=偏差+方差+噪声。
偏差:刻画学习算法本身的拟合能力
方差:刻画数据扰动造成的影响
噪声:刻画学习问题本身的难度
说明一个学习器的泛化性能由学习算法的能力,数据的充分性和学习任务的难度共同决定。














 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









