







2024年5月份架构师考试真题完整版
截至2024-5-28 19:24:14已全部收录完成
共75道选择题,5道案例题,4道论文题。题目顺序不分先后。
全网最全的2024年5月份架构师考试真题回忆版,包含答案和解析。
- 选择题
计算机基础
- 操作系统调度算法 选先来先服务调度算法
- 答案:先来先服务调度算法(First-Come, First-Served,FCFS)是一种简单的调度算法,它按照作业到达的顺序进行调度。
1. 先来先服务(FCFS, First-Come, First-Served): 这是最简单的调度算法,按照进程到达就绪队列的顺序进行调度。它公平但可能不是最优的,因为没有考虑进程的执行时间,可能导致长进程等待时间过长。
2. 短作业优先(SJF, Shortest Job First) / 短进程优先(SPF, Shortest Process First): 这种算法优先调度预计执行时间最短的进程。它可以最小化平均等待时间和周转时间,但是可能存在饥饿问题,即长进程可能永远无法得到执行。
3. 最高响应比优先(HRN, Highest Response Ratio Next): 试图结合FCFS和SJF的优点,通过计算每个进程的响应比(响应比 = 1 + 等待时间 / 服务时间)来决定下一个要执行的进程。这样既考虑了等待时间,也考虑了进程的执行时间。
4. 优先级调度(Priority Scheduling): 根据进程的优先级来决定调度顺序。可以是静态优先级(进程创建时确定且不变)或动态优先级(根据进程等待时间或执行情况调整)。需注意防止高优先级进程导致低优先级进程饥饿。
5. 时间片轮转(RR, Round Robin): 为每个进程分配一个固定时间片(时间量子),时间片用完后即使进程还在运行也会被中断,让给下一个进程。这种方法保证了所有进程都能在有限时间内得到处理器时间,适合分时系统。
6. 多级队列调度(Multi-Level Queue): 将进程根据不同特性(如交互性、优先级)分配到不同优先级的队列中,每个队列可以采用不同的调度算法。通常,前台交互性进程所在的队列优先级高于后台批处理进程。
7. 最短剩余时间优先(SRTN, Shortest Remaining Time Next): 是SJF在抢占式调度系统中的应用,当一个新的进程到来时,如果其预计剩余执行时间比当前正在执行的进程短,则立即抢占处理器。
8. 完全公平调度(CFS, Completely Fair Scheduler): 特别是在Linux系统中,CFS使用红黑树来维护一个按照虚拟运行时间排序的进程列表,保证所有进程在长时间尺度上获得公平的CPU时间。
2. 操作系统多道程序设计 选利用率
- 答案:多道程序设计通过将多个程序放入内存中并行执行,提高了系统资源的利用率和CPU的利用率。
- 操作系统状态流转错误的 选等待态到运行态
- 答案:等待态到运行态的说法是错误的。正确的状态流转应该是“就绪态”到“运行态”
- 在分页存储管理系统中,从页号到物理块号的地址映射是通过( )
A.段表
B.页表
C.PCB
D.JCB
- 答案: 选页表。
- 解析:
在分页存储管理系统中,内存管理涉及将虚拟地址转换为物理地址。这个过程依赖于页表(Page Table)来完成虚拟页面到物理页面帧(物理块)的映射。让我们详细解析一下这个过程和选项:
分页存储管理系统
分页存储管理是一种内存管理技术,其中虚拟地址空间和物理地址空间都被划分为固定大小的块,分别称为页面(Page)和页面帧(Page Frame)。分页的目的是简化内存管理,提高内存利用率,并提供虚拟内存支持。
地址转换过程
在分页系统中,虚拟地址(Virtual Address)分为两个部分:
1. 页号(Page Number):表示虚拟地址中的页面部分。
2. 页内偏移量(Offset):表示页面内的具体地址。
地址转换的步骤如下:
1. 页表查找:操作系统使用页号在页表中查找对应的物理块号(物理页面帧号)。
2. 生成物理地址:物理块号加上页内偏移量,得到物理地址(Physical Address)。
选项解析
1. A. 段表(Segment Table):
段表用于分段存储管理系统,它记录段号到段基址的映射,适用于分段管理,不适用于分页管理。
2. B. 页表(Page Table):
页表是分页存储管理系统中用来记录页号到物理块号(页面帧号)映射的关键数据结构。它是虚拟内存系统中地址转换的核心。
3. C. PCB(Process Control Block):
PCB是进程控制块,用于管理进程的各种信息(如进程状态、寄存器内容、内存分配等),但它不涉及页号到物理块号的直接映射。
4. D. JCB(Job Control Block):
JCB是作业控制块,用于作业管理中的信息记录,和内存管理无关。
- 采样频率 0-500hz,采用什么频率接收才不失真。1000Hz 奈奎斯特定理
- 答案:采样频率至少为1000Hz才能保证接收的信号不失真。。
- 解析:要了解采样频率与信号频率之间的关系。根据奈奎斯特定理,为了避免失真并能完美重建原始信号,采样频率必须至少是信号中最高频率分量的两倍。对于0-500Hz的信号,这意味着采样频率应至少为1000Hz。
- 实际应用中通常推荐使用更高的采样率,这是因为虽然理论上两倍足以避免混叠,但实际应用中可能需要更多的带宽来处理信号中的微小变化和潜在的高频噪声。例如,在音频处理中,常见的做法是使用高达信号最高频率4倍以上的采样率,以确保足够的频域分辨率和避免任何可能的频率重叠。
- 编码问题曼彻斯特编码
- 答案:曼彻斯特编码是一种数字通信中常用的编码方式,用于将数字信号转换为易于传输的波形。
数据库
- 数据库2NF每一个非主属性完全依赖主键
- 答案:是的,第二范式(2NF)要求每一个非主属性完全依赖于主键,而不是依赖于主键的一部分。
- 数据库笛卡尔积m*n
- 答案:正确,笛卡尔积是两个集合的所有可能组合,若集合分别有m和n个元组,则笛卡尔积有m*n个元素。
- 数据库不属于事务的特点,并发性
- 答案:事务的四大特性是ACID(原子性、一致性、隔离性、持久性),并发性不属于事务的特点。
- 数据库交集表达式R-(R-S)
- 答案:表达式R-(R-S)表示集合R和S的交集。
解析:具体的题忘了前置条件了,网上给的普遍答案是上面这个,当集合S是集合R的子集时(即S ⊆ R),此时 R-(R-S) 的结果将是空集,因为从R中移除掉R和S的交集(也就是S本身)后不剩下任何元素。同时,若S是R的子集,则 R ∩ S 就是S本身。在这种情况下,虽然 R-(R-S) 得到空集,并不等同于 R ∩ S(即S),但从操作结果对R的影响来看,可以理解为R相对于S没有新增内容(因为交集就是S,而差集操作后R没变化,只是说明了没有不属于S的元素需要从R中移除)。
总结来说,在数学逻辑和集合论的标准定义下,R ∩ S 和 R-(R-S) 不会在一般情况下表示相同的集合,除非在非常特定且理论上不太合理的假设下(比如违反集合定义或逻辑)进行非标准解读,但这种解读并不符合集合运算的常规理解和实践。正确的理解和使用应严格遵循集合运算的定义。
- 数据库反规范化属于逻辑设计
- 答案:反规范化是指在逻辑设计阶段有意地引入冗余,以提高数据库的读性能。
网络
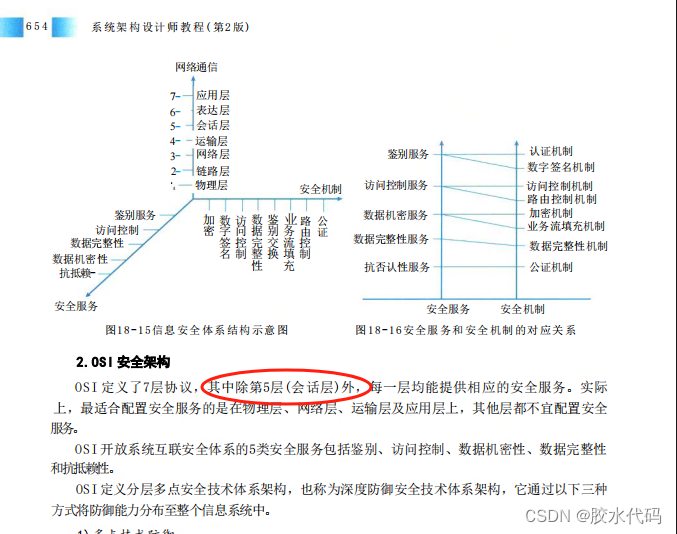
- 网络哪一层没有安全服务,教材上是会话层、但是GPT给的是物理层,目前没有标准答案 (存在争议,大家勿喷,个人观点,有的同学在gpt上问的是会话层,有的说的是传输层)
- 答案: 根据GPT 物理层负责比特流的传输,不涉及加密功能。
群里又有一个同学反馈了一个答案如下图,感觉这个答案 会话层可行性较高,一切以教材为准,比GPT的回答更能作为考官的评分标准,毕竟出题组都是一群大佬哈哈
- 网络二层交换机数据,数据链路层
- 答案:正确,二层交换机工作在数据链路层,处理MAC地址。
- Restful 不正确,选资源与URI多对多
- 答案 RESTful架构中,资源与URI是一对一的关系。
知识产权
- 知识产权 专利法 是否属于民法
- 答案:是的,专利法或知识产权 属于民法的范畴。有的同学查到的是有经济法和刑法。但是网上普遍认知是民法。所以暂时我们就认为是民法。
- 知识产权商标不属于,其他几个是发明实用新型、外观
- 答案:商标法不属于专利法的范畴,专利包括发明、实用新型和外观设计。
- 知识产权权利要求说明书
- 答案:专利申请中的权利要求书用于说明发明内容的保护范围。
数学
- 数学题最少工期26天
- 答案:需要具体题目才能确定,但关键路径法等方法可以用于计算最少工期。
- 数学题线性规划,X、Y极值问题
- 答案:线性规划用于求解约束条件下的目标函数的最优值,常涉及X、Y的极值问题。
软件工程
- 面向对象分析没有聚合用例
- 答案:正确,面向对象分析中不包含聚合用例的概念。
- UML构件图不属于需求分析常用的图
- 答案:正确,UML构件图更多用于设计和实现阶段,不是需求分析的常用图。
- 设计模式bridge不属于创建型设计模式
- 答案:正确,桥接模式(Bridge)属于结构型设计模式,而不是创建型设计模式。
- 软件工程敏捷开发不正确,选项里有预测性
- 答案:敏捷开发强调迭代和增量,而不是预测性。
- 体系结构演化修改、增加或删除构件、更新构件间的相互作用、构件组装与测试
- 答案:正确,体系结构演化涉及对构件和构件间相互作用的修改和更新。
- 系统架构风格黑板体系结构属于仓库体系结构
- 答案:正确,黑板体系结构是一种典型的仓库体系结构。
- 系统架构风格过滤器
- 答案:过滤器架构风格用于处理数据流的各个阶段,如流水线处理。
- 系统架构风格管道
- 答案:管道架构风格常用于流式处理,通过多个阶段的过滤器处理数据。
- 系统架构风格应用服务器,客户机在表示层
- 答案:正确,应用服务器架构中,客户机通常负责表示层。
- 系统架构风格不正确性选项,架构设计一定要基于某个特定架构风格
- 答案:不正确,架构设计不一定要基于某个特定的架构风格,可以结合多种风格。
物联网
- 物联网感知层、网络层、应用层
- 答案:正确,物联网的典型架构分为感知层、网络层和应用层。
事件驱动
- 事件驱动不正确,一个事件的发生不会影响另一个事件
- 答案:不正确,事件驱动系统中,一个事件的发生通常会触发或影响其他事件。
SOA
- SOA服务发现UDDI
- 答案:正确,UDDI(Universal Description, Discovery, and Integration)是SOA中的服务发现机制。
RUP
- RUP 4+1视图中没有没有测试视图
- 答案:正确,RUP的4+1视图模型包括逻辑视图、开发视图、过程视图、物理视图和场景视图,没有测试视图。
构件
- 管理可复用资产分析可复用资产
- 答案:正确,管理可复用资产涉及对可复用资产的分析。
- 获得领域模型领域分析阶段
- 答案:正确,领域模型是在领域分析阶段获得的。
- 构件组装没有循环构件组装
- 答案:正确,构件组装不应存在循环依赖。
- 构件组装操作不完备
- 答案:正确,构件组装操作需要完备才能保证系统功能。
- 构件二进制,无需编译;没有公开接口适配
- 答案:构件通常以二进制形式发布,无需编译;如果没有公开接口,则需要适配器。
质量属性
我个人感受 今年质量属性分值占比同比是最高的
- 质量属性开发期、运行期质量属性
- 答案:质量属性分为开发期属性(如可维护性)和运行期属性(如性能)。
- 4个常用的质量属性没有可测试性
- 答案:可测试性不属于常见的质量属性,常见的是可靠性、性能、可用性和安全性。
- 可用性正常工作的比例
- 答案:可用性是系统正常工作的时间与总时间的比例。
- 互操作性难易程度
- 答案:互操作性指系统与其他系统交互的难易程度。
- 场景描述质量属性
- 答案:质量属性可以通过场景来描述,以便更好地理解和分析。
- 响应采取后的行动
- 答案:响应是系统采取行动后的表现,通常指系统处理输入后产生的输出。
- 效用树优先级排序
- 答案:效用树用于对质量属性进行优先级排序,帮助决策。
- 初始架构评估SAAM
- 答案:SAAM(Software Architecture Analysis Method)用于初始架构的评估。
- 多种质量属性折中ATAM
- 答案:ATAM(Architecture Tradeoff Analysis Method)用于分析多种质量属性之间的折中。
- 性能处理个数
- 答案:性能指标包括系统每秒处理的事务或请求数。
- 性能增加资源
- 答案:通过增加资源(如CPU、内存)可以提高系统性能。
- 机密性保证信息不被泄露
- 答案:机密性保证信息在传输和存储过程中不被未授权的访问和泄露。
- 不可否认性否认交换
- 答案:不可否认性确保通信双方不能否认他们发送或接收的信息。
- 可靠性指标MTTD
- 答案:MTTD(Mean Time To Detection)是指检测故障的平均时间。
解析:在去年11月份考的是MTTF和MTBF。这次考的MTTD。计算机系统和软件工程中,MTTD(Mean Time to Detect,平均故障检测时间)是一个重要的可靠性指标,衡量的是检测到故障所需的平均时间。除了MTTD之外,还有许多其他相关的可靠性和维护性指标。这种题的答题技巧一定是先把简写前的英文记忆方便联想记忆。比如TF to fail 、BF是between Fail TR 是to Repair、TD 是to detect 。这样就不需要记忆哪些概念,只要题目中出现相关关键词大概率选择对应的。
1. MTTF(Mean Time to Failure,平均故障间隔时间):
- 定义:系统或组件从开始工作到首次故障的平均时间。
- 用途:用于评估系统的可靠性。
2. MTBF(Mean Time Between Failures,平均无故障时间):
- 定义:两次故障之间的平均时间。
- 用途:衡量系统的可靠性,是MTTF和MTTR之和。
3. MTTR(Mean Time to Repair,平均修复时间):
- 定义:从故障发生到修复完成的平均时间。
- 用途:用于评估系统的可维护性。
4. MTTA(Mean Time to Acknowledge,平均响应时间):
- 定义:从故障发生到运维人员开始处理故障的平均时间。
- 用途:衡量运维团队对故障的响应速度。
5. MTTRS(Mean Time to Restore Service,平均服务恢复时间):
- 定义:从故障发生到系统恢复正常服务的平均时间。
- 用途:衡量系统恢复服务的速度。
6. MTBFs(Mean Time Between Service Incidents,平均服务事故间隔时间):
- 定义:两次服务事故之间的平均时间。
- 用途:衡量服务的稳定性。
7. MTBR(Mean Time Between Repairs,平均维修间隔时间):
- 定义:两次维修之间的平均时间。
- 用途:用于评估设备或系统的可靠性。
8. MTTD(Mean Time to Diagnose,平均诊断时间):
- 定义:从故障发生到确诊故障根本原因的平均时间。
- 用途:用于评估故障诊断的效率。
9. MTTSF(Mean Time to System Failure,平均系统故障时间):
- 定义:从系统启动到系统整体故障的平均时间。
- 用途:评估系统的整体可靠性。
10. MTBCF(Mean Time Between Critical Failures,平均关键故障间隔时间):
- 定义:两次关键故障之间的平均时间。
- 用途:用于衡量关键系统或组件的可靠性。
11. MTBDE (Mean Time Between Detection and Execution,平均检测与执行时间)
- 定义:从故障检测到采取行动的平均时间。
- 用途:评估故障响应的效率。
- 不属于需求分析的工作 可靠性建模
- 答案:可靠性建模不属于
- 能够在发生错误的时候按照设定的方式正常终止
- 答案:健壮性,健壮性是系统在面对异常输入或异常操作时能够正常运行并终止。
- 解析:健壮性(Robustness):是指系统在遇到异常输入或非预期情况时,仍能继续运行或安全终止的能力。健壮性强调的是系统在面对各种异常情况时的行为和反应。
- 健壮性:
系统在接收到无效或异常输入时,不会崩溃或产生不可预测的行为。
系统在遭遇硬件故障、网络中断或其他异常情况时,能够继续运行或安全地停止。
系统在错误发生时,能够按预期方式进行错误处理和恢复。
因此,能够在发生错误的时候按照设定的方式正常终止,是健壮性的一部分特征。健壮系统在面对不可恢复的错误时,会采取预先设定的措施进行安全终止,以避免更大的损失或风险。
健壮性和容错性在概念上有重叠,但重点不同:
- 容错性(Fault Tolerance):
是指系统在部分组件发生故障时,仍能继续提供正常或降级的服务。容错性主要关注的是系统如何通过冗余、备份和自动切换等机制,在发生故障时维持功能。
总结:能够在发生错误的时候按照设定的方式正常终止,属于系统健壮性的体现,而健壮性确保系统在各种异常和错误情况下的预期反应和安全终止能力。
软件工程
- 关于净室软件工程,选不正确选项 一定不能基于传统的模块测试
- 答案:净室软件工程是一种软件开发方法,其主要特点是基于清晰定义的规范和过程,而不是“一定不能基于模块测试”。
- 解析:净室软件工程(Cleanroom Software Engineering)是一种软件开发方法,旨在通过预防性措施和严格的工程学原理来确保软件的高可靠性和高质量。目标是通过避免缺陷,而不是通过检测和修复缺陷来提高软件质量。这种方法受到生产制造中“零缺陷”理念的启发,采用了严谨的数学和统计技术来保证软件的正确性和可靠性
- 误区和澄清
- 不需要传统测试:净室软件工程并不是完全不需要测试。虽然净室方法强调通过预防性措施减少缺陷,但它仍然依赖于统计质量控制和随机测试来验证软件的可靠性和性能。
- 传统测试的作用:传统的功能测试和系统测试在净室方法中作用较小,重点在于预防缺陷和保证设计正确性。
- 系统架构:视角 描述不同的架构
- 答案: 选视角。
测试
- 测试复杂程序逻辑选择什么测试方法 静态测试
- 答案:关键字程序逻辑。对于复杂的程序逻辑,静态测试尤为重要,因为它可以帮助及早发现设计缺陷、逻辑错误和潜在的执行路径问题
- 测试第二个空选 灰盒测试
- 答案:灰盒测试是介于黑盒测试和白盒测试之间的测试方法,关键字:既考虑了功能需求,又考虑了内部结构。
- 系统测试依据的来源 软件需求规格说明书
- 答案:测试系统的依据通常来自软件需求规格说明书,以确保系统符合规定的功能和性能要求。
- 解析:
- 单元测试:详细设计文档、源代码
- 集成测试:软件架构设计文档、模块接口文档
- 系统测试:软件需求规格说明书
- 验收测试:用户需求文档、业务需求文档、合同或项目计划
- 回归测试:缺陷报告、变更请求文档、回归测试计划
- 性能测试:性能需求文档、系统性能指标
- 安全测试:安全需求文档、安全标准和规范
- 可用性测试:用户体验设计文档、用户需求文档
- 以下关于软件测试说法错误的是()。
选项
- 每个测试用例都必须定义预期的输出或结果
- 测试用例中不仅要说明合法有效的输入条件,还应该描述那些不期望的、非法的输入条件
- 软件测试可以证明被测对象的正确性
- 80%的软件错误都可以在大概20%的模块中找到根源
- 答案:C
- 解析:略
云计算
- 云计算虚拟化技术 openVz xen kvm
- 答案:具体答案选项忘了,但是根据我的网上的答案搜索结果,大概有这些都是常见的虚拟化技术 OpenVZ、KVM、Xen、Hyper-V。我记得有的window 开启vmware虚拟机的时候必须开启Hyper-V功能。
信息系统集成
今年信息系统集成整体来看就考了一分,但是还是不得不学
- EAI 从低向高,流程控制
- 答案:EAI(Enterprise Application Integration)从低向高指的是集成各种企业应用系统的层次,流程控制不是EAI的主要特点。
ADL
- 下列哪些属于ADL?具体选项忘了 Unicon rapide Acme AADL
- 答案:Unicon rapide Acme AADL
- 解析:
- ADL(Architecture Description Language,架构描述语言)是一种用于描述软件系统架构的语言。它们用于定义软件系统的结构、组件、连接和配置等。下列属于ADL的有:
- Unicon:一种架构描述语言,适用于描述和分析软件系统的架构。
- Rapide:一种用于描述、模拟和分析分布式系统架构的语言。
- Acme:一种通用的架构描述语言,设计用于支持软件架构的描述、分析和演化。
- AADL(Architecture Analysis & Design Language):一种标准化的架构描述语言,主要用于嵌入式系统和实时系统的建模和分析。
安全
今年安全相关的选择题占比有点高啊,往年最多两个选择题
- 基于任务的访问控制(TBAC)模型的组成
答案: 工作流、授权结构体、受托人集、许可集四部分组成
解析:
- 基于任务的访问控制(TBAC)模型包括以下四个部分
- 1. 工作流(Workflow):
- 工作流定义了任务的执行流程和步骤,描述了任务之间的依赖关系和执行顺序。工作流确保任务按照预定的流程进行,并且能够有效管理和监控任务的执行。
- 2. 授权结构体(Authorization Structure):
授权结构体定义了角色、用户和任务之间的关系,确定了哪些用户和角色有权执行特定的任务。它是任务与权限之间的映射关系。
- 3. 受托人集(Trustee Set):
受托人集是指被授权执行任务的用户集合。受托人集中的用户通过其角色或直接授权来获取执行任务的权限。
- 4. 许可集(Permission Set):
许可集定义了每个任务所需的具体权限。这些权限与系统资源和操作相关联,确保用户在执行任务时具有适当的权限。
- tsecy
- 答案:TSecY是一种网络安全标准,用于数据的传输安全。
- 安全等级最高的是 访问验证保护级
- 答案:访问验证保护级
- 解析:
- 在软考中提及的安全等级,通常是指信息技术系统安全保护等级,这是中国国家标准GB 17859-1999《计算机信息系统安全保护等级划分准则》中定义的安全级别。这个标准将计算机系统安全级别从低到高分为以下四组七等级:
- 最低级别:D级,称为自主保护级,它又细分为D1级。
- 中间级别:C级,称为系统审计保护级,分为C1级(自主安全保护)和C2级(受控访问保护)。
- 较高级别:B级,称为安全标记保护级,包括B1级(标记安全保护)、B2级(结构化保护)和B3级(安全域)。
- 最高级别:A级,称为访问验证保护级,仅有A1级,是安全级别中最高的,要求最为严格,提供形式化的安全验证。
A1级是安全等级中最高的,而D1级则是最低的。这个分级系统用于指导不同安全需求的计算机信息系统采取相应级别的安全保护措施。
- 灾难恢复级别最高的 数据零丢失和远程集群支持
- 答案:数据零丢失和远程集群支持
- 解析:
远程集群是一种灾难恢复策略,用于在灾难发生时保证系统的持续运行。
国际标准SHARE78
灾难备份能力0~6级
0级:无异地备份
1级:简单异地备份
2级:热备中心备份
3级:电子传输备份
4级:自动定时备份
5级:实时数据备份
6级:数据零丢失
《重要信息系统灾难恢复指南》
工信部2005年
6个灾难恢复等级
第1级 基本支持
第2级 备用场地支持
第3级 电子传输和部分设备支持
第4级 电子传输及完整设备支持
第5级 实时数据传输及完整设备支持
第6级 数据零丢失和远程集群支持
数字孪生
- 数字孪生应用共识
- 答案:数字孪生是通过模拟和仿真技术构建的现实世界的虚拟映像,应用共识是数字孪生中的一种应用场景。
嵌入式系统
- 嵌入式系统屏蔽操作系统
- 答案:嵌入式系统通常屏蔽操作系统的复杂性,直接运行特定的应用程序。
- 嵌入式系统层次化架构模式、递归模式架构
- 答案:层次化架构模式和递归模式架构是嵌入式系统中常见的架构设计模式。
英语题
- 今年英语题考的是需求管理相关,就靠碰运气了,我能回忆出来的就只有下面几个了
- 一道英语题是 Requirements engineering and software architecture
- Requirements engineering 关心什么:
Requirements engineering focuses on gathering, analyzing, documenting, and managing software requirements.
- Software architecture 关心什么:Software architecture concerns the design and organization of software components and subsystems, focusing on high-level structures and interactions.
- 解空间
Solution space
- 问题空间
Problem space
- 需求管理
- Management
- 方法
- Methodology 不确定了,忘记题目和上下文了
解析: 需求工程师和软件工程师在软考中的角色和职责属于软件工程的内容,可以具体划分到以下两个章节:在软件工程和系统设计中,"问题空间"(Problem Space)和"解空间"(Solution Space)是两个关键概念,分别由不同的角色关注:
问题空间(Problem Space)
需求工程师(Requirements Engineer)关心问题空间。
- 定义:问题空间是指系统或软件要解决的问题、满足的需求和面对的约束。它包括业务需求、用户需求、功能性需求、非功能性需求、环境约束、法规要求等。
- 关注点:
- 理解用户需求:明确系统应具备哪些功能,解决哪些业务问题。
- 识别问题和需求:通过需求收集和分析,识别系统应满足的各类需求。
- 需求规格说明:将需求记录成文档,确保开发团队清楚需要解决的问题。
- 需求管理:跟踪需求的变化,确保开发过程中的需求清晰和一致。
解空间(Solution Space)
软件工程师(Software Engineer)关心解空间。
- 定义:解空间是指为了解决问题空间中的问题而设计和实现的各种技术解决方案。它包括系统架构设计、技术选型、模块设计、接口设计、算法实现等。
- 关注点:
- 系统设计:根据需求设计系统的总体架构和详细设计。
- 技术实现:选择合适的技术栈和实现方案来满足需求。
- 编码和实现:编写代码实现系统功能,确保代码质量和性能。
- 测试和验证:通过各种测试手段验证系统是否满足需求,确保系统的功能性和非功能性质量。
总结
- 需求工程师关心问题空间(Problem Space),即明确和管理系统或软件要解决的问题和需求。
- 软件工程师关心解空间(Solution Space),即设计和实现解决方案来满足需求和解决问题。
1. 需求工程(Requirements Engineering)
- 需求工程概述:描述需求工程的定义、目标和重要性。
- 需求收集:讲解需求收集的过程和技术,如访谈、问卷调查、观察等。
- 需求分析:介绍需求分析的方法和工具,如用例分析、需求模型等。
- 需求规格说明:讨论如何编写需求规格说明书(SRS),确保需求的清晰和完整。
- 需求验证与确认:描述需求验证和确认的过程,确保需求的准确性和一致性。
- 需求管理:讲解需求变更管理、需求追踪和版本控制等内容。
2. 软件设计与开发(Software Design and Development)
- 系统设计:讨论系统架构设计、详细设计、模块设计等内容。
- 编码实现:介绍编码的最佳实践、编程规范、代码审查等内容。
- 软件测试:讲解单元测试、集成测试、系统测试和验收测试等不同层次的测试。
- 系统集成:描述系统集成的过程和方法,确保系统各模块的正确集成。
- 维护与支持:讨论软件维护的类型、维护过程和常见问题等内容。
- 技术文档编写:介绍如何编写各种技术文档,如设计文档、用户手册、维护手册等。
这些章节共同构成了软件工程的核心内容。具体来说:
- 需求工程部分主要关注需求工程师的职责,包括需求收集、分析、规格说明、验证、确认和管理。
- 软件设计与开发部分主要关注软件工程师的职责,包括系统设计、编码实现、测试、集成、维护与支持以及技术文档编写。
- 案例分析:
今年的案例题 第一个必选题是 系统架构评估,文老师是押中了。
案例一:系统架构评估
1. 简述微服务架构 对比单体架构和微服务架构 微服务架构的优缺点。(7分)
答:微服务架构是一种分布式系统架构,将一个应用程序拆分为一组小型、独立的服务,每个服务都围绕特定的业务功能构建,并通过轻量级通信机制进行通信。相比之下,单体架构将整个应用程序作为一个单一的单元构建和部署。
微服务架构的优点:
- 灵活性和可扩展性:每个微服务都是独立的,可以独立部署和扩展,使系统更具弹性。
- 技术多样性:每个微服务可以使用不同的技术栈,使开发团队可以选择最适合其需求的技术。
- 易于理解和维护:微服务的小型化和聚焦性使得代码更易于理解、开发和维护。
微服务架构的缺点:
- 复杂性:微服务架构涉及到分布式系统,需要处理分布式事务、服务发现、服务治理等复杂问题。
- 部署和测试:由于微服务的数量增加,部署和测试变得更加复杂。
- 运维成本:微服务架构需要更多的运维工作,包括监控、日志收集、故障排查等。
2. 质量属性及其场景(质量效用树),填空6个。(6分)
就是一个质量效用树,忘了把哪几个空挖了,反正考察,安全性,可用性,功能性,可修改性
3. 用质量属性6要素描述e)和h)两条可用性的场景描述。(12分)
答:质量属性6要素描述:
- e) 可连续运行时间不少于240h,断电或故障后10s内应重启
- 刺激源:断电或故障
- 刺激:系统故障或断电
- 制品:系统
- 环境:运行环境
- 响应:重启
- 响应度量:10秒内
- h) 网络失效后,10s内应发起重新连接
- 刺激源:网络失效
- 刺激:网络失效
- 制品:系统
- 环境:网络环境
- 响应:重新连接
- 响应度量:10秒内
案例二:UML
1. 序列图的哪三种消息和概念。
送分题
答:序列图的三种消息和概念:
- 同步消息
- 异步消息
- 返回消息
2. 序列图补全填空。
3. 系统分析设计过程中两种交互图的选取原则。
解析:在UML中,交互图(Interaction Diagrams)主要用于描述在特定语境中对象之间的交互,它们可以在分析和设计阶段使用。交互图主要包括两种类型:序列图(Sequence Diagrams)和协作图(Collaboration Diagrams)。
- 序列图:强调消息的时间顺序,展示对象之间的动态合作关系,常用于分析阶段。
- 协作图:强调参与交互的对象以及它们如何相互关联,常用于设计阶段。
在分析阶段,你可能想要创建序列图来捕捉对象之间的动态合作,并且能够清晰地展示时序和并发。
在设计阶段,你可能想要创建协作图来定义交互模式,并且能够清晰地展示对象之间的静态关系和它们之间的关联。
4. 顺序图表示条件分支序列片段有哪些。
答:顺序图表示条件分支序列片段包括:
- Alt(Alternative)
- Opt(Option)
- Loop(循环)
- Break(中断)
- Par(并行)
区别总结
- Alt:用于条件分支,有多个互斥的条件。
- Opt:用于可选行为,只有一个条件。
- Loop:用于循环操作,根据条件重复执行。
- Break:用于中断行为,根据条件跳出当前片段。
- Par:用于并行操作,多个消息序列同时执行。
- Critical:用于临界区,确保操作的原子性。
- Neg:用于不应发生的行为,表示错误情况。
- Ref:用于引用其他序列图,实现模块化和重用。
案例三:分布式锁
基于MySQL实现分布式锁的缺点。(9分)
答对5项即可满分 送分题
- 性能瓶颈:MySQL数据库本身可能成为性能瓶颈,特别是在高并发情况下,大量的锁请求和释放可能导致数据库性能下降。
- 单点故障:MySQL单点的特性使得其成为系统的单点故障,如果数据库出现故障,将导致整个系统的分布式锁失效。
- 锁粒度问题:MySQL的锁粒度可能过大或者过小,过大的锁粒度会导致并发性能降低,而过小的锁粒度可能会增加锁冲突的概率,影响系统的并发性能。
- 数据一致性问题:分布式系统中,不同的数据库节点之间的数据同步可能存在延迟或者不一致的情况,这可能导致分布式锁的有效性受到影响。
- 扩展性差:随着系统规模的扩大,单个MySQL数据库可能无法满足系统的性能和容量需求,需要进行垂直或者水平扩展,这会增加系统的复杂性和成本。
- 容错性差:MySQL数据库本身的容错性可能不如专门设计的分布式锁方案,例如基于ZooKeeper或者Redis的分布式锁方案,因此在面对网络分区或者其他故障时可能无法提供可靠的锁服务。
举一个产生Redis分布式锁死锁的场景。(10分)
描述清楚即可满分,送分题
一个可能导致Redis分布式锁死锁的场景是:
假设有两个客户端同时请求获取同一把分布式锁,并且两个客户端的请求几乎同时到达Redis服务器。此时,两个客户端都成功地获取了锁,并开始执行各自的任务。然而,由于某些原因(例如网络延迟、服务器负载等),其中一个客户端在执行任务时花费的时间较长,导致其持有锁的时间超过了预期。在此期间,另一个客户端一直在等待获取锁,因为它无法在锁被释放之前执行任务。
当第一个客户端最终完成任务并释放锁时,第二个客户端会立即获取到锁并开始执行任务。但此时第一个客户端可能又尝试获取锁以执行另一个任务,由于第二个客户端已经获取到了锁,因此第一个客户端将被阻塞等待获取锁,导致死锁的发生。
这种情况下,由于两个客户端的请求在一段时间内交替执行,每个客户端都等待另一个客户端释放锁,最终导致了死锁的产生。为避免这种情况,需要在设计分布式锁的使用场景时考虑合理的超时机制和重试策略,以及确保释放锁的操作能够及时执行。
3. 填写Redis命令,基于ZSet。(6分)
关于nosql平时都是关注的理论层面的,集群,主从,同步,分片等等。没想到现在考的都是实践层面的,我在这儿也翻了船,看来以后的各个培训机构要在这块开设专题了,
答案:
- 存入秒杀的分数命令:ZADD
- 获取分数范围的命令:ZRANGE
- 获取分数:ZSCORE
解析:Redis zset扩展学习
在Redis中,ZSet(有序集合)是一种数据结构,用于存储带有分数(score)的成员(member)。以下是针对ZSet的常用操作命令:
- ZADD key score member [score member ...]
将一个或多个成员元素及其分数值加入到有序集合中。
- ZCARD key
返回有序集合中的成员数量。
- ZSCORE key member
返回有序集合中指定成员的分数。
- ZRANGE key start stop [WITHSCORES]
返回有序集合中指定索引范围内的成员,可选择返回成员的分数。
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回有序集合中分数范围内的成员,可选择返回成员的分数,并可指定返回结果的偏移量和数量。
- ZREM key member [member ...]
移除有序集合中的一个或多个成员。
- ZINCRBY key increment member
将有序集合中指定成员的分数增加增量 increment 。
- ZCOUNT key min max
计算有序集合中分数范围内的成员数量。
- ZREVRANGE key start stop [WITHSCORES]
返回有序集合中指定逆序索引范围内的成员,可选择返回成员的分数。
- ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
返回有序集合中指定逆序分数范围内的成员,可选择返回成员的分数,并可指定返回结果的偏移量和数量。
案例四:嵌入式的题
- 简要分析some/ip协议及其特点 (9分)
SOME/IP是一种应用层协议,它允许在车辆内部网络中实现高效的服务交换和远程调用。这种协议支持车辆各组件之间的复杂通信需求,特别适用于具有高数据吞吐量的场景。基于TCP/IP,支持TCP和UDP。
特点:
服务导向架构 (Service-Oriented Architecture, SOA)SOME/IP实现了一种服务导向架构,允许车辆的各个电子控制单元(ECUs)以服务提供者或服务消费者的身份互动。这种架构使得车辆内部的软件组件可以更加灵活地通信和交互。
远程过程调用 (Remote Procedure Call, RPC)
通过RPC,SOME/IP支持跨网络的函数或过程调用,实现不同ECU之间的紧密协作。
高度可伸缩性和灵活性 (Scalability and Flexibility)
SOME/IP协议的设计考虑到了未来车辆网络可能的扩展,支持从小型车辆到大型车队的不同规模应用。
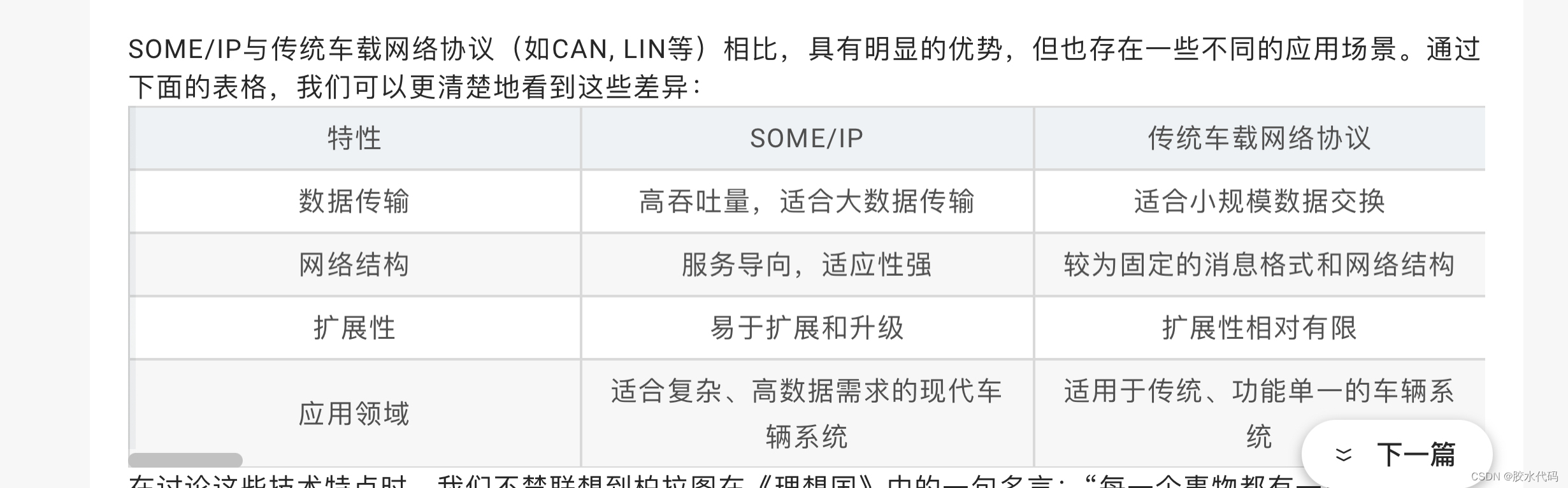
- 填写DDS协议和some/ip协议到以下框图。(6分)
分析:一般dds用于框架模块内部之间通信,some/ip用于外部设备间通信。
参考:(来源于网络,侵权可删除)
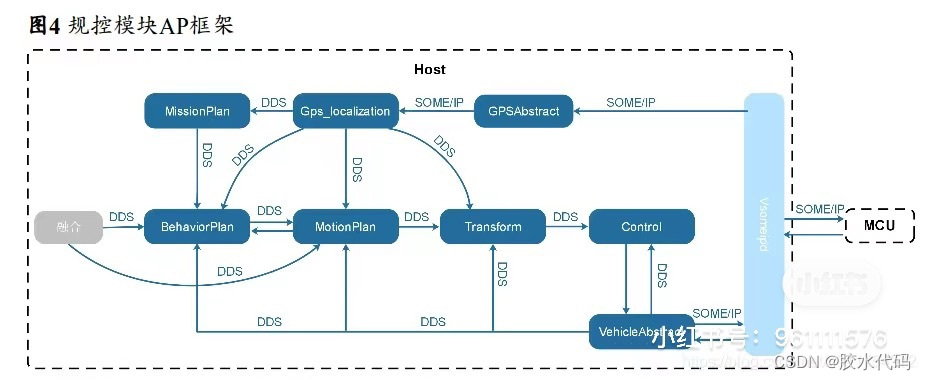
- 规控AP模块的流程框图(10分)。
分析:地图先定位,结合感知模块进行感知,对当前实时环境中的其他目标进行预测,然后规划路径,路径会考虑道路中其他参与者,有路径后交给控制决策车怎么走,然后控制信息传递给交互界面。
参考:(来源于网络,侵权可删除)
案例五:系统设计
1. 系统架构图填空,7个空。(11分)
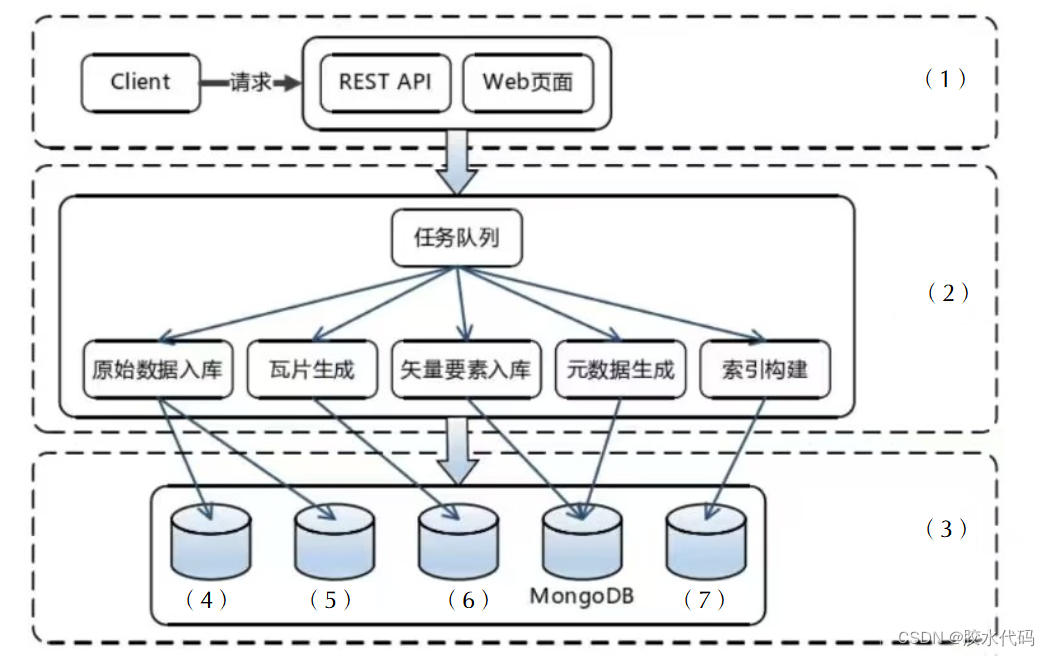
解析:
此处有争议。答案和解析仅供参考,以官方的答案为准,在此大家就不要争论了。
目前大家 对瓦片地图用 HDFS存储还是用Hbase 存储比较有争议,但是这道题来自华中科技大学的硕士论文,如下图。所以标准答案可能就按照论文里面的来了。瓦片地图一般有两种。一般我们理解的瓦片地图是栅格瓦片。这块的瓦片数据没有说明是栅格瓦片还是矢量瓦片。如果是栅格瓦片HDFS应该优先使用。矢量瓦片可能是以JSON结构组装,用Hbase。

瓦片数据和相关的存储方案在选择时确实需要根据数据类型(栅格瓦片或矢量瓦片)来决定。
1. 栅格瓦片(Raster Tiles):
- 描述:栅格瓦片是由像素组成的图像数据,通常用于地图、卫星图像等。
- 适用场景:适合存储在HDFS(Hadoop Distributed File System)中,因为HDFS擅长处理大文件和顺序读取。栅格瓦片通常是大文件,HDFS的设计优化了这种类型的数据存储和处理。
- 存储建议:使用HDFS存储栅格瓦片数据,因为HDFS提供了高吞吐量的读写性能,并且能够很好地扩展来处理大量的数据。
2. 矢量瓦片(Vector Tiles):
- 描述:矢量瓦片是基于矢量数据的瓦片格式,通常以JSON、MVT(Mapbox Vector Tiles)等格式存储,包含点、线、多边形等地理信息。
- 适用场景:适合使用HBase存储,因为HBase是一个分布式、面向列的数据库,擅长处理大量的小文件和随机读写操作。矢量瓦片的数据结构(如JSON)可以很好地映射到HBase的列族和列中。
- 存储建议:使用HBase存储矢量瓦片数据,因为HBase提供了低延迟的随机读写性能,并且可以高效地存储和查询结构化和半结构化数据。
总结:
- 栅格瓦片:优先使用HDFS存储,以利用其高吞吐量和大文件处理能力。
- 矢量瓦片:优先使用HBase存储,以利用其高效的小文件处理和低延迟随机读写能力。
2.MongoDB如何存储非结构性数据的,MongoDB 矢量化存储的优点(10分)
MongoDB 是一个基于分布式文件存储的NoSQL数据库,它使用一种灵活的、面向文档的数据模型来存储非结构化数据。以下是MongoDB存储非结构化数据的方式及其矢量化存储(虽然MongoDB官方并没有直接使用“矢量化存储”这一术语,但我们可以理解为处理和存储复杂数据结构的能力)的一些优点:
MongoDB存储非结构化数据的方式:
1. 文档存储:MongoDB以BSON(Binary JSON)格式存储数据,这是一种类JSON的二进制格式,支持更丰富的数据类型(比如Date、ObjectId等),比传统的JSON更高效。每个文档可以包含任意数量的字段,字段值可以是数组、嵌套文档等多种复杂数据结构,非常适合存储半结构化和非结构化数据。
2. 灵活的数据模型:MongoDB不强制要求数据遵循固定的模式,同一个集合(相当于关系数据库中的表)中的文档可以有不同的字段和结构。这使得MongoDB能轻松适应不断变化的数据需求,特别适合存储那些模式不固定或经常演变的数据。
3. 动态模式:MongoDB的集合不需要预先定义结构,字段可以随时添加或删除,这为非结构化数据的存储提供了极大的灵活性。
4. 索引支持:尽管数据是非结构化的,MongoDB仍然支持对文档中的任何字段创建索引,包括嵌套字段,这大大提升了查询性能。
MongoDB矢量化存储(处理复杂数据结构)的优点:
1. 高效存储与查询:BSON格式不仅支持复杂数据类型,还能高效地存储和查询这些数据。通过利用索引,即使是嵌套文档和数组也能实现快速查询。
2. 简化数据模型:通过文档嵌套和数组,可以将相关数据聚合在一个文档中,减少了数据的连接操作,简化了数据模型,提高了查询效率。
3. 易于扩展与演变:由于数据模型的灵活性,MongoDB能够轻松应对数据结构的变化,无需进行复杂的模式迁移,简化了系统升级和扩展的过程。
4. 高性能:MongoDB使用内存映射文件技术,能够将热数据加载到内存中,提高读写性能。同时,支持水平扩展和分片,能够处理大量数据和高并发请求。
5. 数据处理能力:对于非结构化数据的分析和处理,MongoDB提供了丰富的聚合框架,支持复杂的数据转换和分析操作,如聚合管道、地图reduce等,便于从非结构化数据中提取有价值的信息。
- 使用热数据、温数据和冷数据存储的原因。(4分)
使用热数据、温数据和冷数据存储的原因及好处主要包括以下几点
答出原因或者优点 任意4点即可满分
解析:
原因:
1. 资源优化:不同数据的访问频率差异巨大,将数据按照热度分类可以更合理地分配存储资源。热数据通常需要快速访问,因此存储在高性能、高成本的媒介上;而冷数据访问较少,可以存储在低成本、低速的媒介上。
2. 成本效率:通过区分数据的访问频率,企业可以将有限的预算投入到最关键的数据存储上,如使用SSD或RAM存储热数据,而冷数据则存储在磁带或蓝光光盘上,这样既能保证关键业务的性能,又能控制存储成本。
3. 性能提升:将频繁访问的热数据放置在快速存储设备上,如SSD或内存,可以显著减少数据访问延迟,提高应用响应速度。而冷数据存储在低速设备上对整体系统性能影响较小。
4. 数据保护:对于冷数据,虽然访问频率低,但可能需要长期保存,使用耐久性高的存储介质可以确保数据的安全与持久。
5. 扩展性和灵活性:随着数据量的增长,分层存储策略提供了更好的扩展性,可以根据数据增长和访问模式的变化灵活调整存储策略。
优点:
1. 提升效率:确保高访问频度的数据能够迅速被获取,提升用户体验和业务处理速度。
2. 降低成本:通过将不常访问的数据转移到成本较低的存储介质,减少整体存储成本。
3. 资源利用率最大化:高效利用存储资源,避免高性能存储资源被低访问频度数据占用。
4. 增强数据管理能力:便于数据生命周期管理,如数据归档、备份和恢复策略的实施。
5. 适应业务变化:灵活调整数据存储布局,快速响应业务需求变化,支持业务的持续创新与发展。
综上所述,依据数据热度进行分类存储是一种策略,旨在通过智能地分配存储资源,平衡成本与性能,确保关键业务数据的高效访问,同时合理管理数据生命周期,从而实现整体IT架构的优化。
三、论文
- 关于大数据的,Lambda架构
文老师押中了原题,几乎描述一致
撰写关于Lambda架构的软考论文时,一个清晰且结构化的大纲是成功的关键。以下是一个简单的论文大纲示例,旨在覆盖Lambda架构的核心概念、设计原则、优缺点、实际应用案例以及对比其他架构(如Kappa架构)的分析:
大纲
- 简要介绍Lambda架构的基本概念及其在大数据处理领域的地位。
- 概述论文的主要研究内容、目的及预期贡献。
- 背景介绍:阐述大数据处理的挑战,特别是在实时性和历史数据一致性方面。
- 研究意义:解释研究Lambda架构的重要性,尤其是在现代数据驱动型企业中的应用。
- 论文结构概述。
结合项目可以写的一些内容
论述1:Lambda架构概述
- 定义:明确Lambda架构的定义及提出背景。
- 架构层次:详细介绍批处理层、加速层和服务层的功能与作用。
- 设计原则:概括Lambda架构遵循的核心设计理念。
论述2:Lambda架构的核心组件与工作原理
- 批处理层(Batch Layer):描述其在数据摄入、处理和建立不可变数据视图的作用。
- 加速层(Speed Layer):分析实时处理和补充最近数据的功能。
- 服务层(Serving Layer):说明如何合并实时与批处理数据,提供统一查询接口。
- 数据流与一致性:探讨数据在不同层间流动的机制及确保查询结果一致性的策略。
论述3:Lambda架构的优势与局限性
- 优势:即时查询能力、容错与可扩展性、兼容历史数据处理。
- 局限性:数据重复处理、维护复杂度高、系统设计复杂。
论述4:Lambda架构的实际应用案例分析
- 选取一至两个行业或具体项目,分析Lambda架构的应用场景、实施效果与面临的挑战。
- 案例对比:在不同规模和需求下的适用性讨论。
论述5:Lambda架构与其他架构的对比(可选,具体看论文题目有没有)
- Kappa架构介绍:概述Kappa架构的设计理念和工作流程。
- 对比分析:从数据处理模式、实时性、维护成本等方面对比Lambda与Kappa。
- 选择考量:根据应用场景指导何时选择Lambda或Kappa。
结尾
- 总结Lambda架构在项目实践过程中的使用效果,以及对于项目的核心价值和存在的问题。
- 强调其在大数据处理领域的持续影响力,并指出研究的现实意义。
- 云原生DevOps,云上运维
这个其实我也不太懂。我在网上找了一些答案,可能一些标准教材上也没有详细论述。毕竟算是一个新技术。目前云原生和服务上云还是大厂一直在歌颂的,毕竟命题组也是大学的一些教授和IT行业的专家。
针对“云原生DevOps与云上运维”的主题,这里提供一个简明的指南而非论文大纲,旨在概述这两个概念的核心要素、实施策略及它们如何协同工作以提升软件开发与运维的效率与质量。
云原生DevOps简介
核心要素:
- 容器化:利用Docker等技术,实现应用的轻量级打包与标准化部署。
- 微服务架构:将应用拆分成小型、独立的服务,便于独立开发、部署和扩展。
- 持续集成/持续部署(CI/CD):自动化代码集成、测试与部署,加速软件交付流程。
- 基础设施即代码(IaC):使用代码(如Terraform、CloudFormation)管理基础设施配置。
- 服务网格:如Istio,管理服务间的交互,提供安全、监控与故障恢复等功能。
云上运维特点
优势:
- 弹性与可扩展性:根据需求自动调整资源,应对流量高峰。
- 成本效益:按需付费模型,减少闲置资源成本。
- 自动化运维:利用云服务商工具(如AWS CloudFormation、Azure Automation)实现运维任务自动化。
- 全球部署:轻松实现应用的全球分布与低延迟访问。
- 安全性与合规:利用云平台提供的安全服务和最佳实践,保障数据安全与合规性。
实施策略
1. 拥抱容器化与Kubernetes:作为云原生基础,实现应用的高效部署与管理。
2. 建立CI/CD管道:集成如Jenkins、GitLab CI/CD,确保代码变更快速、可靠地交付到生产环境。
3. 采用微服务设计:分解大型应用,提高开发效率与系统的可维护性。
4. 实施全面监控与日志管理:利用ELK Stack、Prometheus+Grafana等工具,实现系统状态的实时监控与问题快速定位。
5. 强化安全性:集成云原生安全解决方案,如密钥管理、网络策略、安全扫描等。
6. 文化和组织调整:推动DevOps文化,促进开发、运维及其它团队之间的紧密合作与知识共享。
协同工作
云原生DevOps与云上运维的协同,关键在于实现开发与运维流程的高度自动化与协同,确保从代码提交到生产部署的每一个环节都能快速、安全、可靠。通过云原生技术栈的运用,结合云平台的强大功能,可以极大地提升软件交付的速度与质量,同时降低运维复杂度和成本。此外,持续的学习与反馈循环也是保持体系高效运行的重要组成部分。
- 关于模型驱动软件开发方法 领域驱动开发
我记得论文题是模型驱动软件开发方法,但是不排除下次就考目前最流行的DDD了。所以我把模型驱动开发和DDD一起列出来。这个用来写论文确实不好写。等我学习一段时间,再回来继续补充。
领域驱动设计(Domain-Driven Design, DDD)与模型驱动软件开发方法(Model-Driven Software Development, MDSD)是两种注重软件开发质量和效率的方法论。下面分别概述两者的核心概念,并探讨它们如何相互作用以提升软件项目的成功概率。
领域驱动设计 (DDD)
核心要素:
1. 核心领域:识别并聚焦于业务中最关键、最具价值的部分。
2. 界限上下文:划分不同的领域边界,确保领域内的模型一致性。
3. 领域模型:通过实体、值对象、聚合根等元素精确表达业务逻辑。
4. 通用语言:建立业务和技术团队间的共同语言,减少误解。
5. 分层架构:常见的有战略设计、战术设计分层,确保领域逻辑的纯净性。
模型驱动软件开发方法 (MDSD)
基本概念:
1. 抽象模型:从不同的视角(如业务、技术)建立软件的抽象表示。
2. 模型转换:使用转换引擎或代码生成工具将高级模型转换为可执行代码或配置。
3. 元模型与元数据:定义模型的结构和规则,支持模型的标准化和复用。
4. 工具支持:依赖于建模工具、代码生成器等自动化工具链来提高开发效率。
5. 迭代与反馈:模型不是静态的,需在开发过程中不断迭代优化,以反映真实需求。
DDD与MDSD的协同
结合点:
- 领域模型作为起点:DDD的领域模型可作为MDSD中高层次抽象模型的基础,确保模型直接反映业务本质。
- 模型驱动的领域实现:利用MDSD工具将DDD中定义的领域模型转换为具体的实现代码,提高开发效率,减少错误。
- 复杂性管理:DDD帮助识别和管理软件的复杂性,而MDSD通过模型的自动化转换减少实现层面的复杂性。
- 迭代与进化:DDD强调通过迭代深化对领域的理解,而MDSD支持模型的快速迭代和演化,二者结合促进了软件的持续优化。
- 标准化与复用:MDSD的元模型和元数据管理有助于DDD中核心领域模型的标准化表述和跨项目复用。
结论
结合领域驱动设计与模型驱动软件开发方法,可以构建更加贴合业务需求、易于维护和扩展的软件系统。DDD确保软件设计深度契合业务领域,而MDSD则通过自动化工具链提升开发效率和质量,两者相辅相成,共同促进软件工程实践的现代化和高效性。在实践中,需要根据项目特点灵活运用这两种方法,平衡业务理解的深度与技术实现的效率。
- 关于软件单元测试的,静态测试和动态测试 白盒测试的覆盖标准 回归测试如何实施
单单一个单元测试来写一个论文还是内容还是比较鸡肋的,当我考试时看到的时候,感觉挺好写,构思了一下,发现还有内容可能写的不够详实。要写可能从单元测试这些方面
-
- 测试的内容
模块接口测试、局部数据结构测试、边界条件测试、路径覆盖测试、错误处理与异常测试。
-
- 测试的执行场景
描述为什么要进行这些测试,以及测试的必要性
这些都需要我们对这些测试的具体内容要了解才能扯出2000+字数的一篇饱满的论文。感觉要写好,还是要一些基本功的。
撰写关于“软件单元测试的架构设计师”这一主题的论文,可以从介绍单元测试的基本概念入手,逐步深入到架构设计层面如何有效指导和实施单元测试策略,最终提出创新的设计方法或最佳实践案例。下面是一个简化的论文大纲及部分内容示例,
供参考:
关键词: 单元测试, 架构设计, 测试策略, 软件质量, 开发效率
- 单元测试基础理论
- 架构设计与测试的关联性
- 现有单元测试方法及局限性
- 研究缺口分析
基于架构设计的单元测试策略
架构视角下的单元测试原则
- 模块独立性
- 测试可达性
- 依赖管理
设计阶段的单元测试考虑
- 接口设计与测试先行
- 模块边界清晰化
3.3 实施框架与工具选择
- 自动化测试框架
- 持续集成/持续部署(CI/CD)集成
实现步骤
项目背景与目标系统概述,为什么需要进行单元测试
测试架构设计与实施步骤
- 识别核心模块与接口
- 设计测试用例与桩/模拟对象
- 集成自动化测试流程
结果分析与评估
- 测试覆盖率提升
- 缺陷检测率与修复周期
- 对开发流程的影响
结尾 讨论与结论
5.1 使用了单元测试给项目和系统带来哪些好处,收到了xxx好评。等等一通好的就扯,
5.3 总结与建议
样例内容示例(摘自“第三章 基于架构设计的单元测试策略”):
设计阶段的单元测试考虑
在软件设计的早期阶段融入单元测试的思维,是确保高质量代码的关键。首要考虑的是接口设计与测试先行(Test-Driven Development, TDD)。TDD鼓励开发者在编写实际功能代码之前先编写测试用例,这不仅迫使开发者明确接口行为,还促进了代码的模块化设计。例如,在设计一个用户认证模块时,首先定义其接口(如`authenticate(username, password)`),然后编写测试用例检查不同输入下的预期输出,确保后续实现能够满足这些预先设定的测试条件。
其次,模块边界清晰化是提高测试效率和可维护性的另一个重要因素。清晰的模块边界减少了测试之间的相互影响,使得单元测试能够更专注于单一职责的验证。采用接口编程而非直接耦合具体实现,可以进一步增强这种边界清晰度,便于为每个模块独立设计测试策略。
通过这些策略的应用,架构设计师不仅能够促进软件系统的可测试性,还能在架构层面促进代码的解耦和重用,从而提升整体项目的质量和开发效率。
仅仅根据教材上的内容来写一篇优质内容饱满的的单元测试论文,还是很不容易的。
- 对今年软考题目的整体评价
- 题目内容
1. 全面性:
- 覆盖广泛:题目涵盖了计算机基础、网络、操作系统、数据库、软件工程、系统架构、嵌入式系统、虚拟化技术、知识产权等多个方面,展示了全面的知识要求。
- 深度合理:每个领域的题目既包括基础概念,又涉及到具体应用和实践,例如进程状态转换、OSI七层模型、数据库范式、虚拟化技术等。
作为一个合格的架构师应该要具备 技术的广度和一定的深度,要在技术上有一定的追求。以及趁着考系统架构师的契机,把知识成体系的梳理一遍,也不枉为了应试背了那么多八股文。
虽然架构师软考中很多题目都是国内专家、教授、计算机博士,将一些国际的学术论文直白的翻译过来,形成我们自己的方法论题目。可能和现在的互联网企业的真实实践,虽然具有一定的滞后性,
但是对于架构师考试的技术人来说,有的时候一些架构思想和设计思想可能几十年都有它存在的价值。架构师考试也是一个整体了解的体系知识的契机。尤其今年案例题已经是来源于实际的项目案例了。掌握一些方法论的东西还是有一定的好处的。
不然在技术选型和客户技术交流,招投标技术答疑中,被一个随机的问题噎住了也可能比较尴尬,也影响架构师本身的形象。
2. 细节和应用:
- 实际应用:题目不仅仅考察理论知识,还包括实际应用,如Redis分布式锁、数据流风格中的过滤器、质量属性效能树等,显示了对实际工程能力的要求。
- 具体技术:涉及到具体技术和工具,例如曼彻斯特编码、OpenVZ、Xen、KVM、UDDI等,这些都是在实际工作中可能会用到的技术。
3. 架构设计:
- 关注现代架构:题目中包含对微服务架构、敏捷开发、ATAM、SAAM等现代软件架构和设计模式的考察,反映了当前软件工程的前沿。
- 评估和优化:涉及到系统架构评估、质量属性识别和优先级排序等内容,强调了架构设计中的评估和优化能力。
4. 综合能力:
- 多方面考察:题目考察了从需求分析、系统设计、编码实现、测试到维护的整个软件开发生命周期的知识。
- 逻辑思维和分析能力:例如最短路径问题、复杂算法逻辑问题、静态测试和灰度测试的考察,体现了对逻辑思维和分析能力的要求。
5. 知识点覆盖
1. 基础知识:
- 涵盖了计算机科学与技术的基础知识,包括计算机组成原理、操作系统、数据结构与算法、网络、数据库等。
2. 专业知识:
- 涉及到软件工程、系统架构、嵌入式系统、虚拟化技术、分布式系统等专业领域的知识。
3. 实用技能:
- 强调实际工程中的技能,如系统架构设计、软件开发中的质量保证、测试方法、数据管理等。
6. 题目难度
1. 适中难度:
- 题目难度总体适中,既有基础概念的考察,也有对具体技术和实际应用的深层次理解。
2. 重点突出:
- 重点考察了需求分析、系统设计、测试、架构评估等重要环节,符合架构师的职业要求。

















 9244
9244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









