









查找与排序
查找
简述:
最无脑的在一组数据中查找某个数据的方式是逐个比对,碰到匹配的就输出找到了,找完所有数据都无法匹配,就输出找不到
但这种方法效率极其低下,假如数据的数量有一百万。那么在最坏的情况下,需要进行一百万次比对,才能得出结论
为了提高效率,这里介绍一种朴素却有效的算法:二分法
二分法
原理:
当面对一组有序的数据时(如1~100),需要查找其中是否包含N这个数(N由用户输入,所以并不知道N的具体值)。
首先,将N与50进行比对。如果N>50,说明N在50~100的区间内,反之则N在1~50的区间内。
假如N>50,将N与75进行比对,如果N>75,说明N在75~100的区间内,反正则在50~75的区间内。。如此循环
注:不论初始数据的数量是多少,只要数据有序,就每次都取中间的数进行比对
介绍:
二分法效率高的原因是,他在每次比对之后,都能缩小一半的数据规模
如果总数据有一百万,使用逐个比对需要一百万次比对,而使用二分法最多只需要20次(一百万约为2的20次方)!
代码示例:
#include <stdio.h>
#include <stdlib.h>
/*
这个程序用于演绎二分法
原理:
当面对一组有序的数据时(如1~100),需要查找其中是否包含N这个数(N由用户输入,所以并不知道N的具体值)。
首先,将N与50进行比对。如果N>50,说明N在50~100的区间内,反之则N在1~50的区间内。
假如N>50,将N与75进行比对,如果N>75,说明N在75~100的区间内,反正则在50~75的区间内。。如此循环
介绍:
二分法效率高的原因是,他在每次比对之后,都能缩小一般的数据规模
如果总数据有一百万,使用逐个比对需要一百万次比对,而使用二分法最多只需要20次(一百万约为2的20次方)!
*/
#define SIZE 10
int search(int [],int);
int main()
{
int d[SIZE]={1,3,9,12,32,41,45,62,75,77};
int key,index;
printf("Input a key you want to search:");
scanf("%d",&key);
index=search(d,key);
if(index>=0)//index大于零时说明找到了需要的数
printf("The index of the key is %d .\n",index);
else
printf("Not found.\n");
return 0;
}
int search(int d[],int key)
{
int low=0,high=(SIZE-1),mid,index=-1;//此处直接将index的初值赋为-1,这样只要能找到需要的数,index就一定大于零,免去了另外定义标识变量的麻烦
while(low<=high)
{
mid=(low+high)/2;
if(d[mid]==key)
{
index=mid;
break;
}
else if(d[mid]>key)
high=mid-1;
else
low=mid+1;
}
return index;
}
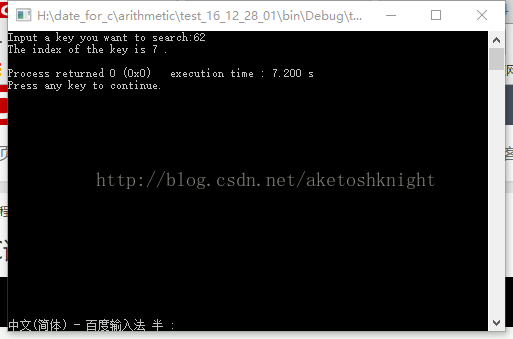
解析:
二分法可以十分效率检索整个数组。
排序
简述:
上述的二分法显然十分的有用,但这个算法的使用限制是,必须是一组有序的数组。
如果需要在一组无序的数组中查找某个元素,就需要先对这组数据进行排序
最无脑的排序方式是选择排序法
机理是:
逐个取出数组中的元素和数组中的其他元素比对,然后将最小/大的取出放入另一个数组,然后再用同样的方式取出第二小/大的,然后第三小/大的。如此循环。
如果数组中有一百个元素的话,完整的排序这个数组就需要100X100=10000次比对,所以仍然是一种效率低下的方法。
为了提高排序的效率,介绍一种同样简单朴素的算法:冒泡排序法
冒泡排序法
原理:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
视频演示:http://dapenti.com/blog/more.asp?name=xilei&id=65524
简述:
冒泡排序法的精巧之处在于:一轮比对完之后,就能获得一组数据中最大的数,然后下一轮获得次大的数,如此重复。
同时,相比于选择排序法的一轮比对完只交换一对数字。冒泡排序几乎每次比对都交换一对数字。这使得效率大大提高。
代码示例:
#include <stdio.h>
#include <stdlib.h>
/*
这个程序用来演绎冒泡排序算法
原理:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
冒泡排序法的精巧之处在于:一轮比对完之后,就能获得一组数据中最大的数,然后下一轮获得次大的数,如此重复。
同时,相比于选择排序法的一轮比对完只交换一对数字。冒泡排序几乎每次比对都交换一对数字。这使得效率大大提高。
如不理解可以通过这里的几段舞蹈直观的认识:http://dapenti.com/blog/more.asp?name=xilei&id=65524
*/
void bubblesort(int [],int n);//核心算法
int main()
{
int i;
int d[10]={51,29,34,11l,547,2,43,66,20,5};
bubblesort(d,10);
for(i=0;i<10;i++)
printf("%d ",d[i]);
return 0;
}
void bubblesort(int a[],int n)
{
int i,j,t;
for(j=0;j<n-1;j++)
{
for(i=0;i<n-j-1;i++)
{
if(a[i]>a[i+1])
{
t=a[i];
a[i]=a[i+1];
a[i+1]=t;
}
}
}
return;
}
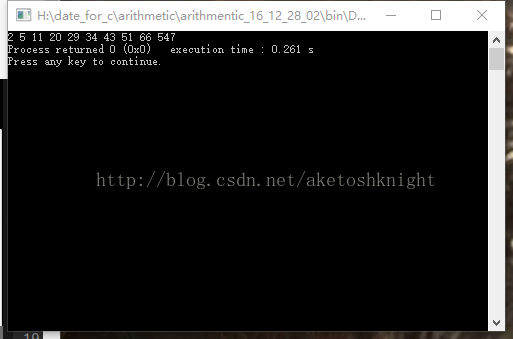
解析:
冒泡排序法只是众多排序算法中的一个,但也是其中较为重要的一个。














 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









