







谈起爬虫,一般人都会嗤之以鼻,没错,它本身不是一个很有挑战的技术活!当然,直到你读完本文内容可能会有所改观。本着技术服务于业务,业务需要的是供应商谈判助手,市场营销.....等等。
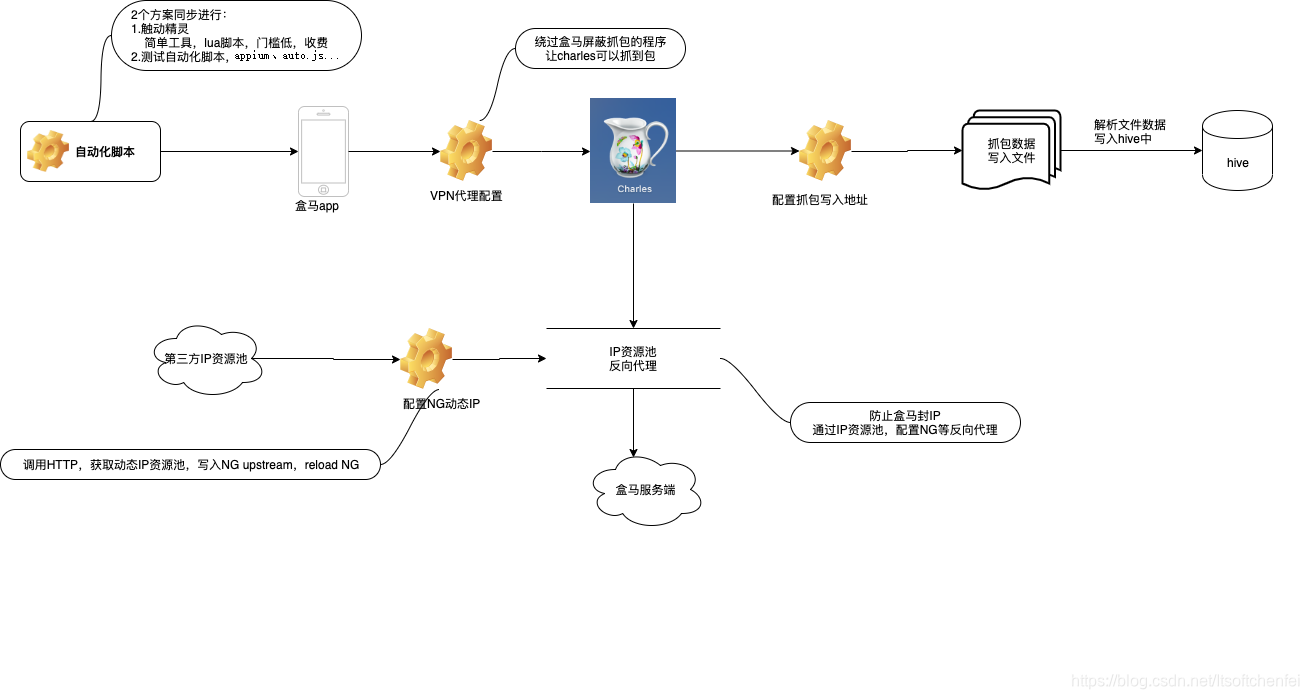
抓包有这么复杂吗?
没错,一般情况下我们直接爬取一个网页(html)或对方的接口是没什么难度,根据对方的规则进行即可,然后就是数据清洗,筛选出自己关注的产品制作报表即可。
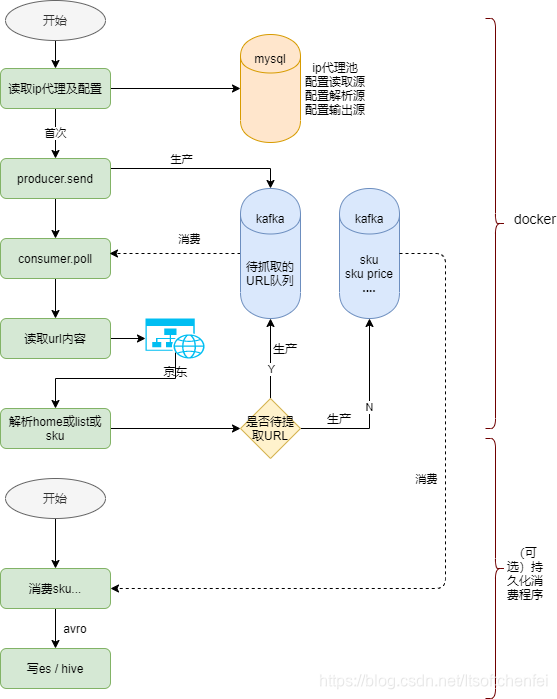
技术上实现上没有太大的创新,无非就是关注2个点:
- 收集种子(生产url)
- 消费种子(消费url)
二者递归即可!下图就是笔者理解的一个分布式的爬虫架构图
然而,一些知名App的反爬都是非常健全的,要保障每天稳定的抓取,我们通常要面临以下问题:
- 比如要爬的是淘系产品,它的x-sign签名有可能是绕不过的坑,可能就要借助自动化(有可能需要多机触控)
- ip请求频率限制,很多ip代理可以采购解决
- android系统中安装的抓包软件啥都看不到(app上做了反代理策略),可能要借助vpn
到这里,再次温习网络知识(http/https)因为会遇到各种tcp/ip通讯上的错,接下来可以实操了!
实操环节
首先你需要搞好环境,android刷机、系统root、安装系统证书等等。
vpn:
- shadowrocket,国内android好像不太行
- Drony,还算比较稳
抓包软件:
- charles,功能非常强大,不支持脚本
- mitmproxy,功能也非常强大,支持脚本,运行不太稳定(偶尔会有些错)
- fiddler,功能也非常强大,支持脚本,但不支持添加二次正向代理(出口网络)
实操其实没啥经验,对着每个软件的使用手册熟读几遍足以。


















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









